Background
GitHub Copilot is a new service from GitHub and OpenAI, described as “Your AI pair programmer”. It is a plugin to Visual Studio Code which auto-generates code for you based on the contents of the current file, and your current cursor location.
It really feels quite magical to use. For example, here I’ve typed the name and docstring of a function which should “Write text to file fname”:

The grey body of the function has been entirely written for me by Copilot! I just hit Tab on my keyboard, and the suggestion gets accepted and inserted into my code.
This is certainly not the first “AI powered” program synthesis tool. GitHub’s Natural Language Semantic Code Search in 2018 demonstrated finding code examples using plain English descriptions. Tabnine has provided “AI powered” code completion for a few years now. Where Copilot differs is that it can generate entire multi-line functions and even documentation and tests, based on the full context of a file of code.
This is particularly exciting for us at fast.ai because it holds the promise that it may lower the barrier to coding, which would greatly help us in our mission. Therefore, I was particularly keen to dive into Copilot. However, as we’ll see, I’m not yet convinced that Copilot is actually a blessing. It may even turn out to be a curse.
Copilot is powered by a deep neural network language model called Codex, which was trained on public code repositories on GitHub. This is of particular interest to me, since in back in 2017 I was the first person to demonstrate that a general purpose language model can be fine-tuned to get state of the art results on a wide range of NLP problems. I developed and showed that as part of a fast.ai lesson. Sebastian Ruder and I then fleshed out the approach and wrote a paper, which was published in 2018 by the Association for Computational Linguistics (ACL). OpenAI’s Alec Radford told me that this paper inspired him to create GPT, which Codex is based on. Here’s the moment from that lesson where I showed for the first time that language model fine tuning gives a state of the art result in classifying IMDB sentiment:
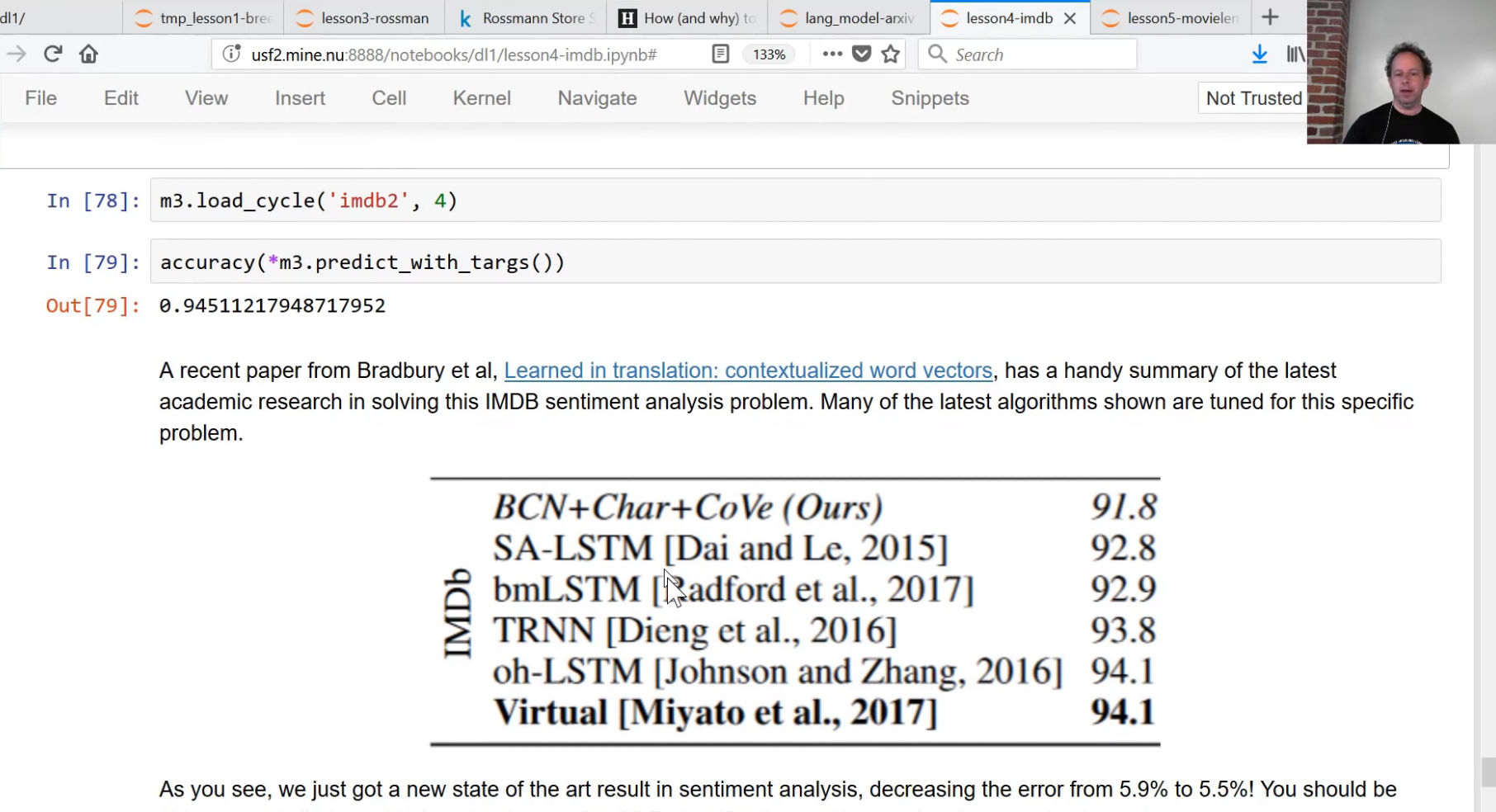
A language model is trained to guess missing words in a piece of text. The traditional “ngram” approach used in previous years can not do a good job of this, since context is required to guess correctly. For instance, consider how you would go about filling in the missing words in each of these examples:

Knowing that in one case “hot day” is correct, but in another that “hot dog” is correct, requires reading and (to some extent) understanding the whole sentence. The Codex language model learns to guess missing symbols in programming code, so it has to learn a lot about the structure and meaning of computer code. As we’ll discuss later, language models do have some significant limitations that are fundamentally due to how they’re created.
The fact that Copilot is trained on publicly available code, under a variety of licenses, has led to many discussions about the ethical and legal implications. Since this has been widely discussed I won’t go into it further here, other than to point out one clear legal issue for users of Copilot discussed by IP lawyer Kate Downing, which is that in some cases using Copilot’s suggestions may be a breach of license (or require relicensing your own work under a GPL-compatible license):
“The more complex and lengthy the suggestion, the more likely it has some sort of copyrightable expression.”
Walk-through
Before we dive into Copilot more deeply, let’s walk-through some more examples of using it in practice.
In order to know whether that auto-generated write_text function actually works, we need a test. Let’s get Copilot to write that too! In this case, I just typed in the name of my test function, and Copilot filled in the docstring for me:

After accepting that suggestion, Copilot got a bit confused and suggested a meaningless function containing many lines of near duplicate code:
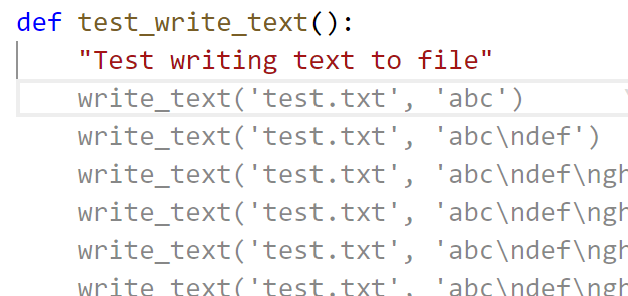
No problem – Copilot can show us other suggested options, by hitting Ctrl-Enter. The first listed actually looks pretty reasonable (except for an odd extra tab character in the first line):
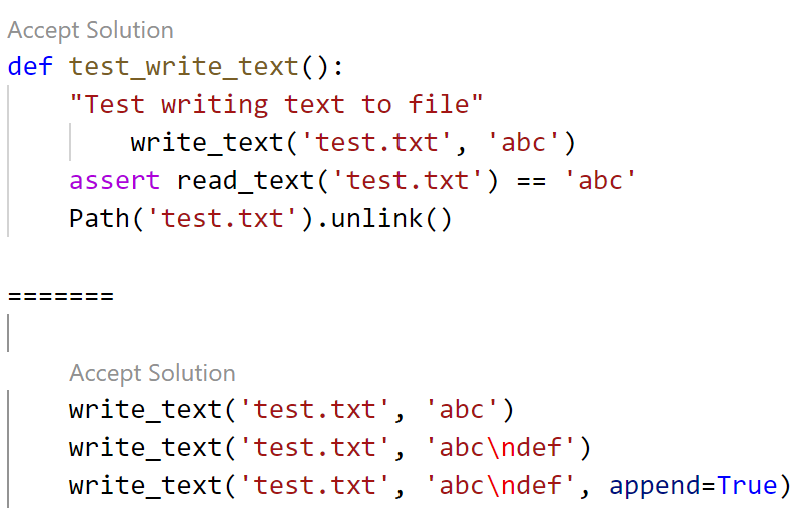
Here Copilot assumes there’s a function available called read_text, which doesn’t actually exist. But it’s easy enough for us to ask Copilot to write and test that for us too.
I also asked Copilot to create a function for me that would “Tar and optionally compress directory dir to dest in bz2, xz, or gzip format”, which resulted in:
def tar_dir(dir, dest):
"Tar and optionally compress directory `dir` to `dest` in bz2, xz, or gzip format"
if dest.endswith('.bz2'):
with tarfile.open(dest,'w:bz2') as f: f.add(dir, arcname=os.path.basename(dir))
elif dest.endswith('.xz'):
with tarfile.open(dest,'w:xz') as f: f.add(dir, arcname=os.path.basename(dir))
elif dest.endswith('.gz'):
with tarfile.open(dest,'w:gz') as f: f.add(dir, arcname=os.path.basename(dir))
else: raise ValueError('bad dest: {}'.format(dest))I also had Copilot create a test using the same basic approach as above, and it wrote:
with TemporaryDirectory() as tmp:
write_text(os.path.join(tmp,'a.txt'),'hello')
write_text(os.path.join(tmp,'b.txt'),'world')
tar_dir(tmp,'out.tar.bz2')
assert os.path.exists('out.tar.bz2')
with tarfile.open('out.tar.bz2') as f:
assert f.getnames()==['a.txt','b.txt']That test doesn’t actually pass, since getnames in the last line includes the parent directory, but it’s an easy enough fix from there. Copilot even cleverly decided to use the write_text function I created earlier, which is something I wasn’t expecting.
You can even use Copilot to write prose. I’m writing this blog post in vscode right now, and just clicked the “enable Copilot” button. After I typed the previous sentence, here’s what Copilot recommended as a completion:
“I can now write my blog post in a single line of text, and Copilot will generate the rest of the post for me”
Clearly Copilot has a rather inflated understanding of its own prose generation capabilities!
Code problems
The code Copilot writes is not very good code. For instance, consider the tar_dir function above. There’s a lot of duplicate code there, which means more code to maintain in the future, and more code for a reader to understand. In addition, the docstring said “optionally compress”, but the generated code always compresses. We could fix these issues by writing it this way instead:
def tar_dir(dir, dest):
"Tar and optionally compress directory `dir` to `dest` in bz2, xz, or gzip format"
suf = ':' + Path(dest).suffix[1:]
if suf==':tar': suf=''
with tarfile.open(dest,f'w{suf}') as f: f.add(dir, arcname=dir)A bigger problem is that both write_text and tar_dir shouldn’t have been written at all, since the functionality for both is already provided by Python’s standard library (as pathlib’s write_text and shutil’s make_archive). The standard library versions are also better, with pathlib’s write_text doing additional error checking and supporting text encoding and error handling, and make_archive supporting zip files and any other archive format you register.
Why Copilot writes bad code
According to OpenAI’s paper, Codex only gives the correct answer 29% of the time. And, as we’ve seen, the code it writes is generally poorly refactored and fails to take full advantage of existing solutions (even when they’re in Python’s standard library).
Copilot has read GitHub’s entire public code archive, consisting of tens of millions of repositories, including code from many of the world’s best programmers. Given this, why does Copilot write such crappy code?
The reason is because of how language models work. They show how, on average, most people write. They don’t have any sense of what’s correct or what’s good. Most code on GitHub is (by software standards) pretty old, and (by definition) written by average programmers. Copilot spits out it’s best guess as to what those programmers might write if they were writing the same file that you are. OpenAI discuss this in their Codex paper:
“As with other large language models trained on a next-token prediction objective, Codex will generate code that is as similar as possible to its training distribution. One consequence of this is that such models may do things that are unhelpful for the user”
One important way that Copilot is worse than those average programmers is that it doesn’t even try to compile the code or check that it works or consider whether it actually does what the docs say it should do. Also, Codex was not trained on code created in the last year or two, so it’s entirely missing recent versions, libraries, and language features. For instance, prompting it to create fastai code results only in proposals that use the v1 API, rather than v2, which was released around a year ago.
Complaining about the quality of the code written by Copilot feels a bit like coming across a talking dog, and complaining about its diction. The fact that it’s talking at all is impressive enough!
Let’s be clear: The fact that Copilot (and Codex) writes reasonable-looking code is an amazing achievement. From a machine learning and language synthesis research point of view, it’s a big step forward.
But we also need to be clear that reasonable-looking code that doesn’t work, doesn’t check edge cases, and uses obsolete methods, and is verbose and creates technical debt, can be a big problem.
The problems with auto-generated code
Code creation tools have been around nearly as long as code has been around. And they’ve been controversial throughout their history.
Most time coding is not taken up in writing code, but with designing, debugging, and maintaining code. When code is automatically generated, it’s easy to end up with a lot more of it. That’s not necessarily a problem, if all you have to do to maintain or debug it is to modify the source which the code is auto-generated from, such as when using code template tools. Even then, things can get confusing when debugging, since the debugger and stack traces will generally point at the verbose generated code, not at the templated source.
With Copilot, we don’t have any of these upsides. We nearly always have to modify the code that’s created, and if we want to change how it works, we can’t just go back and change the prompt. We have to debug the generated code directly.
As a rule of thumb, less code means less to maintain and understand. Copilot’s code is verbose, and it’s so easy to generate lots of it that you’re likely to end up with a lot of code!
Python has rich dynamic and meta-programming features that greatly reduce the need for code generation. I’ve heard a number of programmers say that they like that Copilot writes a lot of boilerplate for you. However, I almost never write any boilerplate anyway – any time in the past I found myself needing boilerplate, I used dynamic Python to refactor the boilerplate out so I didn’t need to write it or generate it any more. For instance, in ghapi I used dynamic Python to create a complete interface to GitHub’s entire API in a package that weighs in at just 40kB (by comparison, an equivalent packages in Go contains over 100,000 lines of code, most of it auto-generated).
A very instructive example is what happened when I prompted Copilot with:
def finetune(folder, model):
"""fine tune pytorch model using images from folder and report results on validation set"""With a very small amount of additional typing, it generated these 89 lines of code nearly entirely automatically! In one sense, that’s really impressive. It does indeed basically do what was requested – finetune a PyTorch model.
However, it finetunes the model badly. This model will train slowly, and result in poor accuracy. Fine tuning a model correctly requires considering things like handling batchnorm layer statistics, finetuning the head of the model before the body, picking a learning rate correctly, using an appropriate annealing schedule, and so forth. Also, we probably want to use mixed precision training on any CUDA GPU created in the last few years, and are likely to want to add better augmentation methods such as MixUp. Fixing the code to add these would require many hundreds of lines more code, and a lot of expertise in deep learning, or the use of a higher level API such as fastai, which can finetune a PyTorch model in 4 lines of code, resulting in something with higher accuracy, faster, and that’s more extensible.)
I’m not really sure what would be best for Copilot to do in this situation. I don’t think what it’s doing now is actually useful in practice, although it’s an impressive-looking demonstration.
Parsing Python with a regular expression
I asked the fast.ai community for examples of times where Copilot had been helpful in writing code for them. One person told me they found it invaluable when they were writing a regex to extract comments from a string containing python code (since they wanted to map each parameter name in a function to its comment). I decided to try this for myself. Here’s the prompt for Copilot:
code_str = """def connect(
host:str, # host to connect to
port:int=80, # port to connect to
ssl:bool=True, # whether to use SSL
) -> socket.socket: # the connected socket
"""
# regex to extract comments from strings looking like code_strHere’s the generated code:
comment_re = re.compile(r'^\s*#.*$', re.MULTILINE)This code doesn’t work, since the ^ character is incorrectly binding the match to the start of the line. It’s also not actually capturing the comment since it’s missing any capturing groups. (The second suggestion from Copilot correctly removes the ^ character, but still doesn’t include the capturing group.)
These are minor issues, however, compared to the big problem with this code, which is that a regex can’t actually parse Python comments correctly. For instance, this would fail, since the # in tag_prefix:str="#" would be incorrectly parsed as the start of a comment:
code_str = """def find_tags(
input_str:str, # the string to search for tags
tag_prefix:str="#" # prefix marking the start of a tag
) -> List[str]: # list of all tags foundIt turns out that it’s not possible to correctly parse Python code using regular expressions. But Copilot did what we asked: in the prompt comment we explicitly asked for a regex, and that’s what Copilot gave us. The community member who provided this example did exactly that when they wrote their code, since they assumed that a regex was the correct way to solve this problem. (Although even when I tried removing “regex to” from the prompt Copilot still prompted to use a regex solution.) The issue in this case isn’t really that Copilot is doing something wrong, it’s that what it’s designed to do might not be what’s in the best interest of the programer.
GitHub markets Copilot as a “pair programmer”. But I’m not sure this really captures what it’s doing. A good pair programmer is someone who helps you question your assumptions, identify hidden problems, and see the bigger picture. Copilot doesn’t do any of those things – quite the opposite, it blindly assumes that your assumptions are appropriate and focuses entirely on churning out code based on the immediate context of where your text cursor is right now.
Cognitive Bias and AI Pair Programming
An AI pair programmer needs to work well with humans. And visa versa. However humans have two cognitive biases in particular that makes this difficult: automation bias and anchoring bias. Thanks to this pair of human foibles, we will all have a tendency to over-rely on Copilot’s proposals, even if we explicitly try not to do so.
Wikipedia describes automation bias as:
“the propensity for humans to favor suggestions from automated decision-making systems and to ignore contradictory information made without automation, even if it is correct”
Automation bias is already recognized as a significant problem in healthcare, where computer decision support systems are used widely. There are also many examples in the judicial and policing communities, such as the city official in California who incorrectly described an IBM Watson tool used for predictive policing: “With machine learning, with automation, there’s a 99% success, so that robot is—will be—99% accurate in telling us what is going to happen next”, leading the city mayor to say “Well, why aren’t we mounting .50-calibers [out there]?” (He claimed he was he was “being facetious.”) This kind of inflated belief about the capabilities of AI can also impact users of Copilot, especially programmers who are not confident of their own capabilities.
The Decision Lab describes anchoring bias as:
“a cognitive bias that causes us to rely too heavily on the first piece of information we are given about a topic.”
Anchoring bias has been very widely documented and is taught at many business schools as a useful tool, such as in negotiation and pricing.
When we’re typing into vscode, Copilot jumps in and suggests code completions entirely automatically and without any interaction on our part. That often means that before we’ve really had a chance to think about where we’re heading, Copilot has already plotted a path for us. Not only is this then the “first piece of information” we’re getting, but it’s also an example of “suggestions from automated decision making systems” – we’re getting a double-hit of cognitive biases to overcome! And it’s not just happening once, but every time we write just a few more words in our text editor.
Unfortunately, one of the things we know about cognitive biases is that just being aware of them isn’t enough to avoid being fooled by them. So this isn’t something GitHub can fix just through careful presentation of Copilot suggestions and user education.
Stack Overflow, Google, and API Usage Examples
Generally if a programmer doesn’t know how to do something, and isn’t using Copilot, they’ll Google it. For instance, the coder we discussed earlier who wanted to find parameters and comments in a string containing code might search for something like: “python extract parameter list from code regex”. The second result to this search is a Stack Overflow post with an accepted answer that correctly said it can’t be done with Python regular expressions. Instead, the answer suggested using a parser such as pyparsing. I then tried searching for “pyparsing python comments” and found that this module solves our exact problem.
I also tried searching for “*extract comments from python file”, which gave a first result showing how to solve the problem using the Python standard library’s tokenize module. In this case, the requester introduced their problem by saying “I’m trying to write a program to extract comments in code that user enters. I tried to use regex, but found it difficult to write.” Sounds familiar!
This took me a couple of minutes longer that finding a prompt for Copilot that gave an answer, but it resulted in me learning far more about the problem and the possible space of solutions. The Stack Overflow discussions helped me understand the challenges of dealing with quoted strings in Python, and also explained the limitations of Python’s regular expression engine.
In this case, I felt like the Copilot approach would be worse for both experienced and beginner programmers. Experienced programmers would need to spend time studying the various options proposed, recognize that they don’t correctly solve the problem, and then would have to search online for solutions anyway. Beginner programmers would likely feel like they’ve solved the problem, wouldn’t actually learn what they need to understand about limitations and capabilities of regular expressions, and would end up with broken code without even realizing it.
In addition to CoPilot, Microsoft, the owners of GitHub, have created a different but related product called “API Usage Examples”. Here’s an example taken directly from their web-site:
This tool looks for examples online of people using the API or library that you’re working with, and will provide examples of real code showing how it’s used, along with links to the source of the example. This is an interesting approach that’s somewhere between Stack Overflow (but misses the valuable discussions) and Copilot (but doesn’t provide proposals customized to your particular code context). The crucial extra piece here is that it links to the source. That means that the coder can actually see the full context of how other people are using that feature. The best ways to get better at coding are to read code and to write code. Helping coders find relevant code to read looks to be an excellent approach to both solving people’s problems whilst also helping them improve their skills.
Whether Microsoft’s API Usage Examples feature turns out the be great will really depend on their ability to rank code by quality, and show the best examples of usage. According to the product manager (on Twitter) this is something they’re currently working on.
Conclusions
I still don’t know the answer to the question in the title of this post, “Is GitHub Copilot a blessing, or a curse?” It could be a blessing to some, and a curse to others. For those for whom it’s a curse, they may not find that out for years, because the curse would be that they’re learning less, learning slower, increasing technical debt, and introducing subtle bugs – are all things that you might well not notice, particularly for newer developers.
Copilot might be more useful for languages that are high on boilerplate, and have limited meta-programming functionality, such as Go. (A lot of people today use templated code generation with Go for this reason.) Another area that it may be particularly suited to is experienced programmers working in unfamiliar languages, since it can help get the basic syntax right and point to library functions and common idioms.
The thing to remember is that Copilot is an early preview of a very new technology that’s going to get better and better. There will be many competitors popping up in the coming months and years, and GitHub will no doubt release new and better versions of their own tool.
To see real improvements in program synthesis, we’ll need to go beyond just language models, to a more holistic solution that incorporates best practices around human-computer interaction, software engineering, testing, and many other disciplines. Currently, Copilot feels like a product designed and implemented by machine learning researchers, rather than a complete solution incorporating all needed domain expertise. I’m sure that will change.