Jeremy is the past president of Kaggle, founder of Enlitic, FastMail.FM, and Optimal Decisions Group, and is on the faculty at Singularity University. See fast.ai’s About page for a brief bio.
About six months ago, I resigned from my position as CEO of Enlitic, the company that I founded to bring medical diagnostics and treatment planning into the data driven world. I created Enlitic because there are 4 billion people in the world without access to modern medical diagnostics, and it will take about 300 years to train enough doctors to fill this gap – but with deep learning, we can make doctors 10 times more productive, and therefore bring modern medicine to these people within 5 to 10 years. This is only possible thanks to the power of deep learning and neural networks, a technology which I have been using for over 20 years, but which just in the last couple of years has reached a point where it can help solve many previously unsolved problems. I discussed the implications of this a couple of years ago in my TED.com talk, back when I was first launching Enlitic. And indeed, many of the predictions I made then, have since come to pass. Deep learning is now becoming embedded in products such as Apple’s Siri, Google photos, and self-driving cars.
(Some people are even claiming that deep learning is “overhyped”. This is as ridiculous a claim as somebody in the early 90s claiming that the Internet was overhyped. Deep learning is clearly going to be even more widely used and far-reaching and transformative than the Internet.)
But for all the successes, I discovered during my two years at Enlitic that deep learning has a very long way to go before it can help most people. Creating a deep learning model is, ironically, a highly manual process. Training a model takes a long time, and even for the top practitioners, it is a hit or miss affair where you don’t know whether it will work until the end. No mature tools exist to ensure models train successfully, or to ensure that the original set up is done appropriately for the data.
Therefore, Dr. Rachel Thomas (a math PhD with past experience as a quant, Uber data scientist, full-stack developer, and educator) and I decided to create fast.ai, a research lab dedicated to doing everything necessary to allow deep learning to meet its enormous potential. We believe that this requires allowing domain experts to be able to leverage the technology themselves, rather than leaving it in the hands of a small and exclusive group of mathematicians. Only domain experts: fully understand and appreciate what are the most important problems in their field; have access to the data necessary to solve those problems; and understand the opportunities and constraints to implementing data driven solutions.
Consider this chart shared by Jeff Dean, leader of Google Brain:
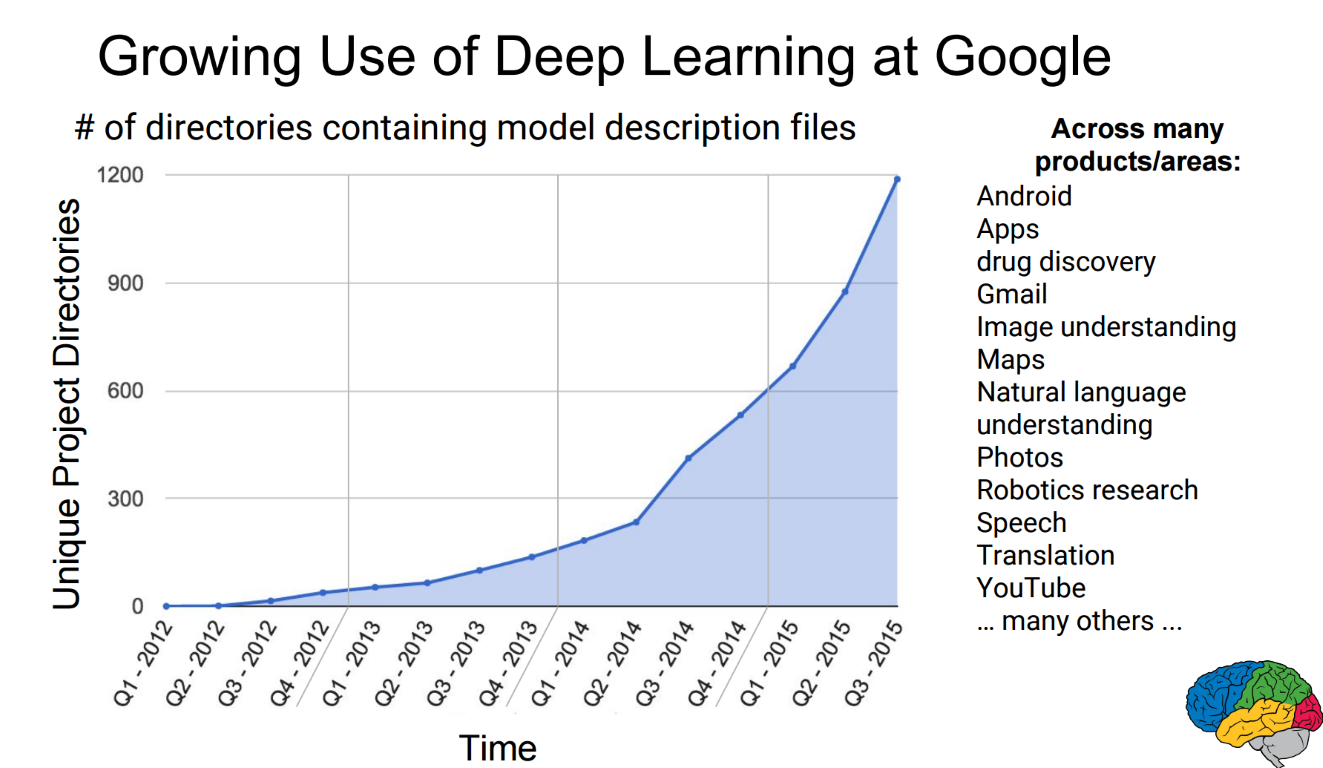
At the start of 2012, deep learning was not being used at Google outside of Google Brain research. Since then, it’s use has grown exponentially, and it was being used in aprox 1,200 different projects by late 2015. Now imagine the impact deep learning can have as it spreads beyond the Bay Area tech elite, and we see this exponential growth in every organization around the world. The impact will be greatest in the two-thirds world, where resources are most constrained. For instance: there are only 14 pediatric radiologists for the entire continent of Africa (and half of those are in a single country, South Africa); many African countries have none! What if medical technology could read x-rays? Tens of millions of children would have access to medical image diagnostics for the first time. And the value of this technology to automate identifying tuberculosis, a disease that receives little research attention in the west but is the leading cause of death from infectious disease worldwide, killing almost 4,000 people daily, could be even higher. In India, Indonesia, and China, there are over 3 billion people, most of whom live in areas with similarly poor access to medical image diagnostics.
During my eight years in management consulting I worked with hundreds of domain experts across dozens of fields and industries. I saw people who were highly creative in figuring out how to solve their problems, given the tools that they were familiar with. Nowadays we receive requests for help nearly every day, from people who want to use deep learning by solving everything from helping treat mental illness, to increasing agricultural yields in the developing world, identifying and treating plant disease, and developing adaptive educational materials. The best way we can help these people is by giving them the tools and knowledge to solve their own problems, using their own expertise and experience.
We believe that the steps necessary to meet our goal of democratising deep learning are as follows:
- fix the shortage of data scientists with deep learning expertise
- create highly automated tools for training deep learning models
- build software to provide deep insight into the training of, and results from, deep learning models
- develop a range of “role model” applications, in areas where deep learning is currently being poorly utilized.
So we’re starting at the start! In our next post, we’ll talk about how we’re trying to deal with step 1 - fixing the shortage of data scientists with deep learning expertise.
If you can’t wait, check out the official USF Data Institute description of our upcoming deep learning course on Monday evenings and send your resume to [email protected] to apply.