This post has been translated into Chinese here.
I will update this post based on constructive feedback as I receive it (with attribution)—although I’ve tried to largely stick to my area of specialty (data science) I’ve had to touch on various areas that I’m not an expert in, so please do let me know if you notice any issues. You can reach me on Twitter at @jeremyphoward.
Introduction
Unless you’ve been off-planet for the last few days, you’ve probably read about the Stanford paper Deep Neural Networks Can Detect Sexual Orientation From Faces. There have been many reactions to the preprint, such as Oberlin sociology professor Greggor Mattson, who summarised his response as AI Can’t Tell if You’re Gay… But it Can Tell if You’re a Walking Stereotype.
When I first read about this study, I had a strong negative emotional response. The topic is of great personal interest to me—Rachel Thomas and I started fast.ai explicitly for the purpose of increasing diversity in the field of deep learning (including the deep neural networks used in this study), and we even personally pay for scholarships for diverse students, including LGBTQ students. In addition, we want to support the use of deep learning in a wider range of fields, because we believe that it can both positively and negatively impact many people’s lives, so we want to show how to use the technology appropriately and correctly.
Like many commentators, I had many basic concerns about this study. Should it have been done at all? Was the data collection an invasion of privacy? Were the right people involved in the work? Were the results communicated in a thoughtful and sensitive way? These are important issues, and can’t be answered by any single individual. Because deep learning is making it possible for computers to do things that weren’t possible before, we’re going to see more and more areas where these questions are going to arise. Therefore, we need to see more cross-disciplinary studies being done by more cross-disciplinary teams. In this case, the researchers are data scientists and psychologists, but the paper covers topics (and claims to reach conclusions) in fields from sociology to biology.
So, what does the paper actually show - can neural nets do what is claimed, or not? We will analyze this question as a data scientist - by looking at the data.
Summary
The key conclusions of both the paper (“Deep neural networks can detect sexual orientation from faces”) and the response (“AI can’t tell if you’re gay”) are not supported by the research shown. What is supported is a weaker claim: in some situations deep neural networks can recognize some photos of gay dating website users from some photos of heterosexual dating website users. We definitely can’t say “AI can’t tell if you’re gay”, and indeed to make this claim is irresponsible: the paper at least shows some sign that the opposite might well be true, and that such technology is readily available and easily used by any government or organization.
The senior researcher on this paper, Michael Kosinski, has successfully warned us of similar problems in the past: his paper Private traits and attributes are predictable from digital records of human behavior is one of the most cited of all time, and was at least partly responsible for getting Facebook to change their policy of having ‘likes’ be public by default. If the key result in this new study does turn out to be correct, then we should certainly be having a discussion about what policy implications it has. If you live in a country where homosexuality is punishable by death, then you need to be open to the possibility that you could be profiled for extra surveillance based on your social media pictures. If you are in a situation where you can’t be open about your sexual preference, you should be aware that a machine learning recommendation system could (perhaps even accidentally) target you with merchandise targeted to a gay demographic.
However, the paper comes to many other conclusions that are not directly related to this key question, are not clearly supported by the research, and are overstated and poorly communicated. In particular, the paper claims that the research supports the “widely accepted” prenatal hormone theory (PHT) that “same-gender sexual orientation stems from the under-exposure of male fetuses or overexposure of female fetuses to androgens that are responsible for sexual differentiation”. The support for this in the paper is far from rigorous, and should be considered inconclusive. Furthermore, the sociologist Greggor Mattson says that not only is the theory not widely accepted, but that “literally the first sentence of a decade-old review of the field is ‘Public perceptions of the effect of testosterone on ‘manly’ behavior are inaccurate’”.
How was the research was done?
A number of studies are presented in the paper, but the key one is ‘study 1a’. In this study, the researchers downloaded on average 5 images of 70,000 people from a dating website. None of the data collected in the study has been made available, although nearly any programmer could easily replicate this (and indeed many coders have created similar datasets in the past). Because the study’s focus is on detecting sexual orientation from faces, they cropped the photos to the area of the face. They also removed photos with multiple people, or where the face wasn’t clear, or wasn’t looking straight at the camera. The technical approach here is very standard and reliable, using widely used open source software called Face++.
They then removed any images that a group of non-expert workers considered either not adult, or not caucasian (using Amazon’s Mechanical Turk system). It wasn’t entirely clear why they did this; most likely they were assuming that handling more types of face would make it harder to train their model.
It’s important to be aware that steps like this used to ‘clean’ a dataset are necessary for nearly all data science projects, but they are rarely if ever perfect - and those imperfections are generally not important in understanding the accuracy of a study. What’s important for evaluation is to be confident that the final metrics reported are evaluated appropriately. More on this shortly…
They labeled each as gay or not based on each dating profile’s listed sexual preference.
The researchers then used a deep neural network (VGG-Face) to create features. Specifically, each image was turned into 4096 numbers, each of which had been trained by University of Oxford researchers to be as good as possible for recognizing humans from their faces. They compressed those 4096 numbers down 500 using a simple statistical technique called SVD, and they then used a simple regression model to map these 500 numbers to the label (gay or not).
They repeated the regression 10 times. Each time they used a different 90% subset of the data, and tested the model using the remaining 10% (this is known as cross-validation). The ten models were scored using a metric called AUC which is a standard approach for evaluating classification models like this one. The AUC for people marked as males in the dataset was 0.91.
How accurate is this model?
The researchers describe their model as “91% accurate”. This is based on the AUC score of 0.91. However, it is very unusual and quite misleading to use the word “accuracy” to describe AUC. The researchers have clarified that the actual accuracy of the model can be understood as follows: if you pick the 10% of people in the study with the highest scores on the model, about half will actually be gay based on the collected labels. If the actual percentage of gay males is 7%, then this shows that the model is a lot better than random. However it is probably not as accurate as most people would imagine if they heard something was “91% accurate”.
It is also important to note that based on this study (study 1a) we can only really say that the model can recognize gay dating profiles from one web-site of people that non-experts label as adult caucasian, not that it can recognize gay photos in general. It’s quite likely that this model will generalize to other similar populations, but we don’t know from this research how similar those populations would need to be, and how accurate it will be.
Have the researchers created a new technology here?
The approach used in this study is literally the very first technique that we teach in our introductory deep learning course. Our course does not require an advanced math background - only high school math is need. So the approach used here is literally something anyone can do with high school math, an hour of free online study, and a basic knowledge of programming.
A model trained in this way takes under 20 seconds to run on a commodity server that can be rented for $0.90/hour. So it does not require any special or expensive resources. The data can be easily downloaded from dating websites by anyone with basic coding skills.
The researchers say that their study shows a potential privacy problem. Since the technology they used is very accessible, then if you believe that the capabilities shown are of concern, then this claim seems reasonable.
It is probably reasonably to assume that many organizations have already completed similar projects, but without publishing them in the academic literature. This paper showing what can already be easily done—it is not creating a new technology. It is becoming increasingly common for marketers to use social media data to help push their products; in these cases the models simply look for correlations between product sales and and social media data that is available. In this case it would be very easy for a model in implicitly find a relationship between certain photos and products targeted to a gay market, without the developers even realizing it had made that connection. Indeed, we have seen somewhat similar issues before such as that described in the article How Target Figured Out A Teen Girl Was Pregnant Before Her Father Did.
Did the model show that gay faces are physically different?
In study 1b, the researchers cover up different parts of each image, to see which parts when covered up cause the prediction to change. This is a common technique for understanding the relative importance of different parts of an input to a neural network.
The results this analysis are shown in this picture from the paper:

The red areas are relatively more important to the model than the blue areas. However, this analysis does not show how much more important it is, or why or in what way the red areas were more important.
In study 1c they try to create an “average face” for each of male and female and for each of gay and heterosexual. This part of the study has no rigorous analysis and relies entirely on an intuitive view of the images shown. From a data science point of view, there is no additional information that can be gained from this section.
The researchers claim that these studies show support for the prenatal hormone theory. However, no data is presented that shows how this theory is supported or what level of support is provided, nor investigates possible alternative theories for the observations.
Is the model more accurate than humans?
The researchers claim in the first sentence of the abstract that “faces contain much more information about sexual orientation than can be perceived and interpreted by the human brain”. They base this claim on Study 4, in which they ask humans to classify images from the same dataset as study 1a. However, this study completely fails to provide an adequate methodology to support the claim. Stanford researcher Andrej Karpathy (now at Tesla) showed a fairly rigorous approach to how human image classification can be compared to a neural net. The key piece is to give the human the same opportunity to study the training data as the computer received. In this case, that would mean letting each human judge study many examples of the faces and labels collected in the dataset, before being asked to classify faces themselves.
By failing to provide this “human training” step, the humans and computers had very different information with which to complete the task. Even if the methodology was better, there would still be many possible explanations other than the very strong and unsupported claim that they decided to open their paper with.
As a rule, academic claims should be made with care and rigor and communicated thoughtfully. Especially when it opens a paper. Especially especially when it is in such a sensitive area. Double especially especially when it covers an area outside the researchers’ area of specialty. This issue is thoughtfully discussed with relation to this paper in a Calling Bullshit case study.
Is the classifier effective for images other than dating pics from one website?
In short: we don’t know. Study 5 in the paper asserts that it is, but it does not provide strong support for this claim, and is set up in a oddly convoluted way. The method used for study 5 was to find facebook pics from some extra-super-gay facebook users: people who listed a same-sex partner, and liked at least two pages such as “Manhunt” and “I love being gay”. It then tried to see if they could train a classifier to separate these pics from heterosexual dating web-site users. The claimed accuracy of this classifier was 74%, although the exact meaning of this 74% figure is not listed. If it means an AUC of 0.74 (which is how the researchers referred to AUC earlier in the paper), this is not a strong result. It’s also comparing across datasets (facebook vs dating website), and using a very particular type of facebook profile to do their test.
The researchers state that they didn’t compare to heterosexual profile pics because they didn’t know how to find them.
Are their conclusions supported by their studies?
In the General Discussion section the researchers come to a number of conclusions. All of the conclusions as stated are stronger than what can be concluded from the research results shown. However, we can at least say (assuming that their data analysis was completed correctly, which we can’t confirm since we don’t have access to their data or code) that sexual preference of people in some photos can be identified much better than randomly in some situations.
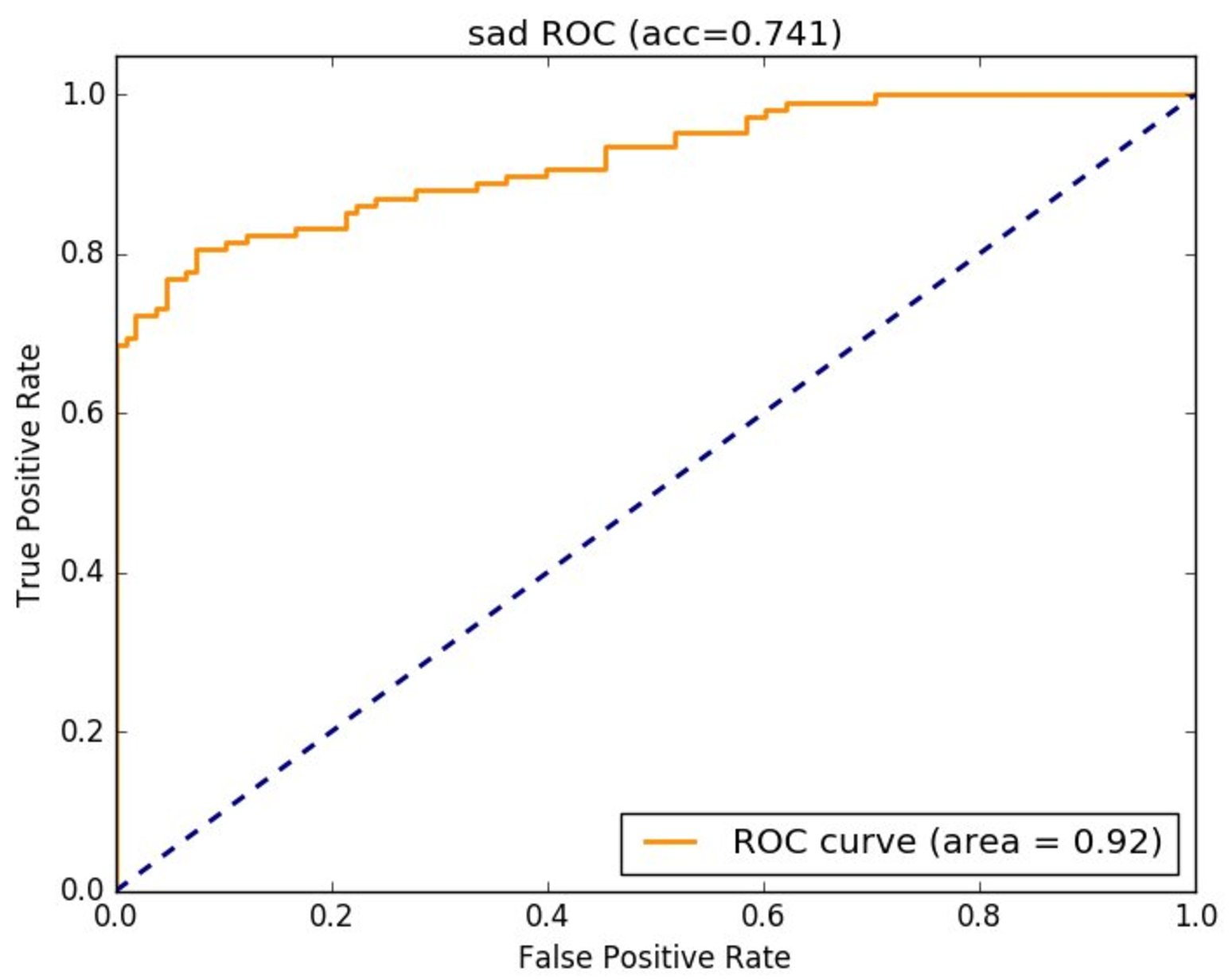
They conclude that their model does not simply find differences in presentation between the two groups, but actually shows differences in underlying facial structure. This claim is based partly on an assertion that the VGG-Face model they use is trained to identify non-transient facial features. However, some simple data analysis readily shows that this assertion is incorrect. Victoria University researcher Tom White shared an analysis that showed this exact model, for instance, can recognize happy from neutral faces with a higher AUC (0.92) than the model shown in this paper (and can recognize happy from sad faces even better, with an AUC of 0.96).
Did the paper confuse correlation with causation?
Any time that a paper from social scientists comes to the attention of groups of programmers (such as when shared on coding forums), inevitably we hear the cry “correlation is not causation”. This happened for this paper too. What does this mean, and is it a problem here? Naturally, XKCD has us covered:

Correlation refers to an observation that two things happen at the same time. For instance, you may notice that on days when people buy more ice-cream, they also buy more sun-screen. Sometimes people incorrectly assume that such an observation implies causation—in this case, that eating ice-cream causes people to want sunscreen. When a correlation is observed between some event x (buying ice-cream) and event y (buying sunscreen), there are three main possibilities:
x causes y
y causes x
something else causes both x and y (possibly indirectly)
pure chance (we can measure the probability of this happening - in this study it is vanishingly low)
In this case, of course, a warm and sunny day causes both the desire for ice-cream, and the need for sunscreen.
Much of the social sciences deals with this issue. Researchers in these fields often have to try to reach conclusions from observational studies in the presence of many confounding factors. This is a complex and challenging task, and often results in imperfect results. For mathematicians and computer scientists, results from the social sciences can seem infuriatingly poorly founded. In math, if you want to claim that, for example, no three positive integers a, b, and c satisfy the equation an + bn = cn for any integer value of n greater than 2, then it doesn’t matter if you try millions of values of a, b, and c and show none have this relationship—you have to prove it for all possible integers. But in the social sciences this kind of result is generally not possible. So we must try to weigh the balance of evidence versus our a priori expectations regarding the results.
The Stanford paper tries to separate out correlation from causation by using various studies, as discussed above. And in the end, they don’t do a great job of it. But the simple claim that “correlation is not causation” is a sloppy response. Instead, alternative theories need to be provided, preferably with evidence: that is, can you make a claim that y causes x, or that something else causes both x and y, and show that your alternative theory is supported by the research shown in the paper?
In addition, we need to consider the simple question: does it actually matter? E.g. if it is possible for a government (or an over-zealous marketer) to classify a photo of a face by sexual orientation, mightn’t this be an important result regardless of whether the cause of the identified differences are grooming, facial expression, or facial structure?
Should we worry about privacy?
The paper concludes with a warning that governments are already using sophisticated technology to infer intimate traits of citizens, and that it is only through research like this that we can guess what kind of capabilities they have. They state:
Delaying or abandoning the publication of these findings could deprive individuals of the chance to take preventive measures and policymakers the ability to introduce legislation to protect people. Moreover, this work does not offer any advantage to those who may be developing or deploying classification algorithms, apart from emphasizing the ethical implications of their work. We used widely available off-the-shelf tools, publicly available data, and methods well known to computer vision practitioners. We did not create a privacy-invading tool, but rather showed that basic and widely used methods pose serious privacy threats.
These are genuine concerns and it is clearly a good thing for us all to understand the kinds of tools that could be used to reduce privacy. It is a shame that the overstated claims, weak cross-disciplinary research, and methodological problems clouded this important issue.