Last year we announced that we were developing a new deep learning course based on Pytorch (and a new library we have built, called fastai), with the goal of allowing more students to be able to achieve world-class results with deep learning. Today, we are making this course, Practical Deep Learning for Coders 2018, generally available for the first time, following the completion of a preview version of the course by 600 students through our diversity fellowship, international fellowship, and Data Institute in-person programs. The only prerequisites are a year of coding experience, and high school math (math required for understanding the material is introduced as required during the course).
The course includes around 15 hours of lessons and a number of interactive notebooks, and is now available for free (with no ads) at course.fast.ai. About 80% of the material is new this year, including:
- All models train much faster than last year’s equivalents, are much more accurate, and require fewer lines of code
- Greatly simplified access to cloud-based GPU servers, including Crestle, Paperspace, and AWS
- Shows how to surpass all previous academic benchmarks in text classification, and how to match the state of the art in collaborative filtering, and time series and structured data analysis
- Leverages the dynamic compilation features of Pytorch to provide deeper understanding of the internals of designing and training models
- Covers recent network architectures such as Resnet and ResNeXt, including building a Resnet with batch normalization from scratch.
Combining research and education
fast.ai is first and foremost a research lab. Our research focuses on how to make practically useful deep learning more widely accessible. Often we’ve found that the current state of the art (SoTA) approaches aren’t good enough to be used in practice, so we have to figure out how to improve them. This means that our course is unusual in that although it’s designed to be accessible with minimal prerequisites (just high school math and a year of coding experience) we show how to match or better SoTA approaches in computer vision, natural language processing (NLP), time series and structured data analysis, and collaborative filtering. Therefore, we find our students have wildly varying backgrounds, including 14 year old high school students and tenured professors of statistics and successful Silicon Valley startup CEOs (and dairy farmers, accountants, buddhist monks, and product managers).
We want our students to be able to solve their most challenging and important problems, to transform their industries and organizations, which we believe is the potential of deep learning. We are not just trying to teach people how to get existing jobs in the field — but to go far beyond that. Therefore, since we first ran our deep learning course, we have been constantly curating best practices, and benchmarking and developing many techniques, trialing them against Kaggle leaderboards and academic state-of-the-art results.
The 2018 course shows how to (all with no more than a single GPU and a few seconds to a few hours of computation): - Build world-class image classifiers with as little as 3 lines of code (in a Kaggle competition running during the preview class, 17 of the top 20 ranked competitors were fast.ai students!) - Greatly surpass the academic SoTA in NLP sentiment analysis - Build a movie recommendation system that is competitive with the best highly specialized models - Replicate top Kaggle solutions in structured data analysis problems - Build the 2015 imagenet winning resnet architecture and batch normalization layer from scratch
A unique approach
Our earlier 2017 course was very successful, with many students developing deep learning skills that let them do things like:
- Sara Hooker, who only started coding 2 years ago, and is now part of the elite Google Brain Residency
- Tim Anglade, who used Tensorflow to create the Not Hot Dog app for HBO’s Silicon Valley, leading Google’s CEO to tweet “our work here is done”
- Gleb Esman, who created a new fraud product for Splunk using the tools he learned in the course, and was featured on Splunk’s blog
- Jacques Mattheij, who built a robotic system to sort two tons of lego
- Karthik Kannan, founder of letsenvision.com, who told us “Today I’ve picked up steam enough to confidently work on my own CV startup and the seed for it was sowed by fast.ai with Pt.1 and Pt.2”
- Matthew Kleinsmith and Brendon Fortuner, who in 24 hours built a system to add filters to the background and foreground of videos, giving them victory in the 2017 Deep Learning Hackathon.
The new course is 80% new material, reflecting the major developments that have occurred in the last 12 months in the field. However, the key educational approach is unchanged: a top-down, code-first approach to teaching deep learning that is unique. We teach “the whole game”–starting off by showing how to use a complete, working, very usable, state of the art deep learning network to solve real world problems, by using simple, expressive tools. And then gradually digging deeper and deeper into understanding how those tools are made, and how the tools that make those tools are made, and so on… We always teach through examples: ensuring that there is a context and a purpose that you can understand intuitively, rather than starting with algebraic symbol manipulation. For more information, have a look at Providing a Good Education in Deep Learning, one of the first things we wrote after fast.ai was launched.
A good example of this approach is shown in the article Fun with small image data-sets, where a fast.ai student shows how to use the teachings from lesson 1 to build near perfect classifiers with <20 training images.
A special community
Perhaps the most valuable resource of all are the flourishing forums where thousands of students and alumni are discussing the lessons, their projects, the latest research papers, and more. This community has built many valuable resources, such as the helpful notes and guides provided by Reshama Shaikh, including: - GPU Image Setup on AWS - fast.ai FAQs for Beginners - Deep Learning Terms
Some forum threads have become important sources of information, such as Making your own server which now has over 500 posts full of valuable information, and Implementing Mask R-CNN which has been viewed by thousands of people that are interested in this cutting edge segmentation approach.
A new deep learning library
The new course is built on top of Pytorch, and uses a new library (called fastai) that we developed to make Pytorch more powerful and easy to use. I won’t go into too much detail about this now, since we discussed the motivation in detail in Introducing Pytorch for fast.ai and will be providing much more information about the implementation and API shortly. But to give a sense of what it means for students, here’s some examples of fastai in action:
- fastai is the first library to implement the Learning Rate Finder (Smith 2015) which solves the challenging problem of selecting a good learning rate for your model
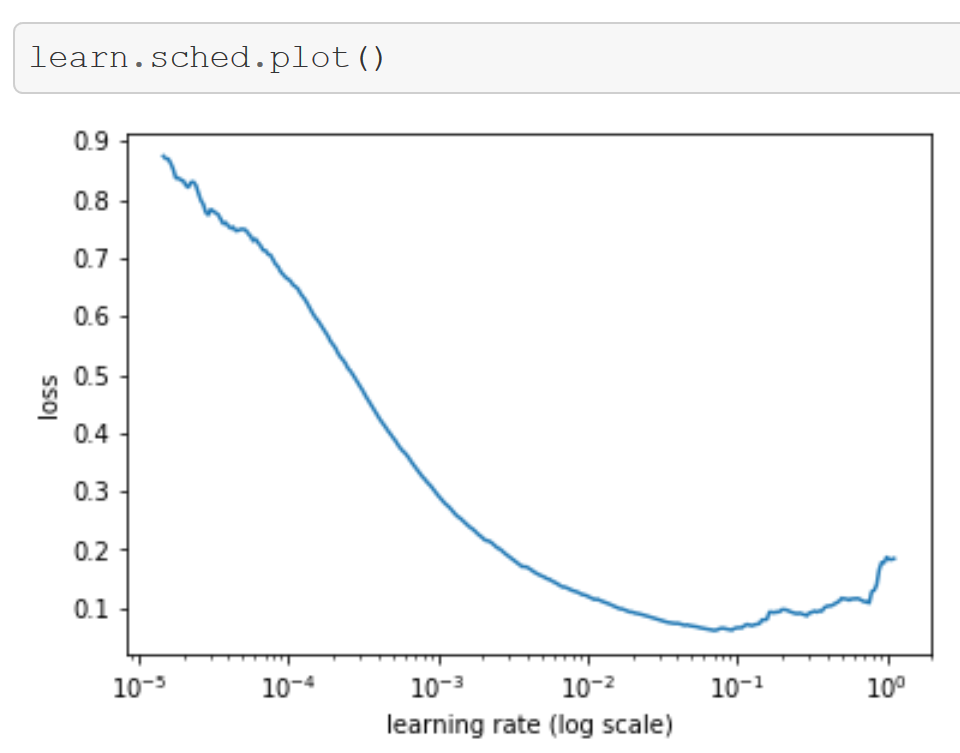
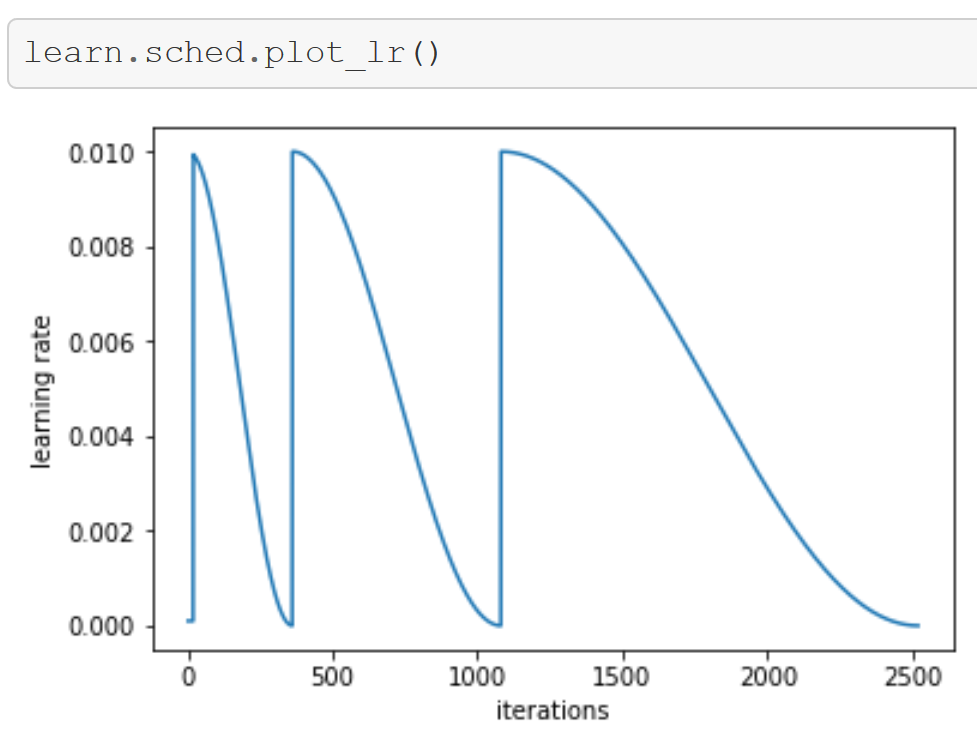
- Having found a good learning rate, you can train your model much faster and more reliably by utilizing Stochastic Gradient Descent with Restarts (SGDR) - again fastai is the first library to provide this feature
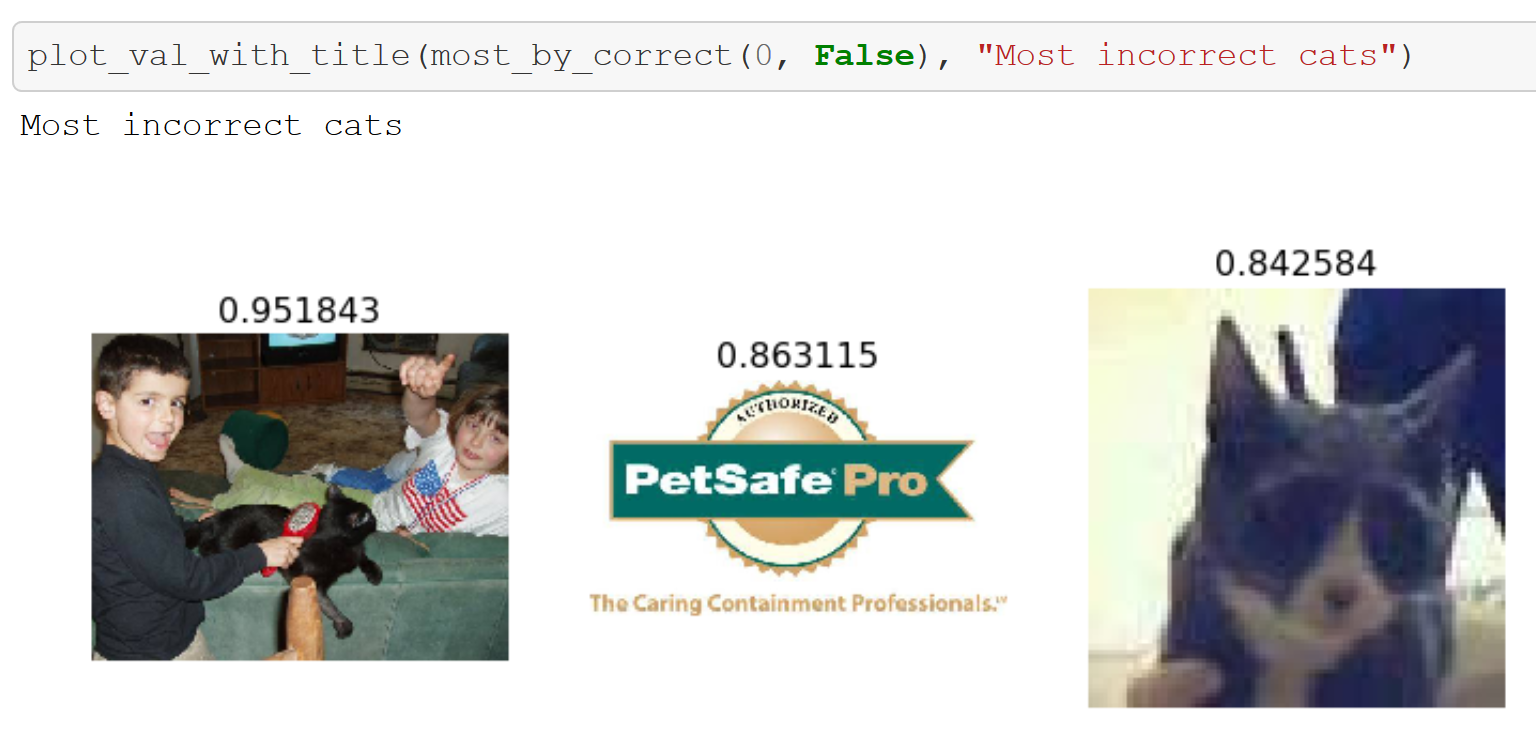
- Once you’ve trained your model, you’ll want to view images that the model is getting wrong - fastai provides this feature in a single line of code
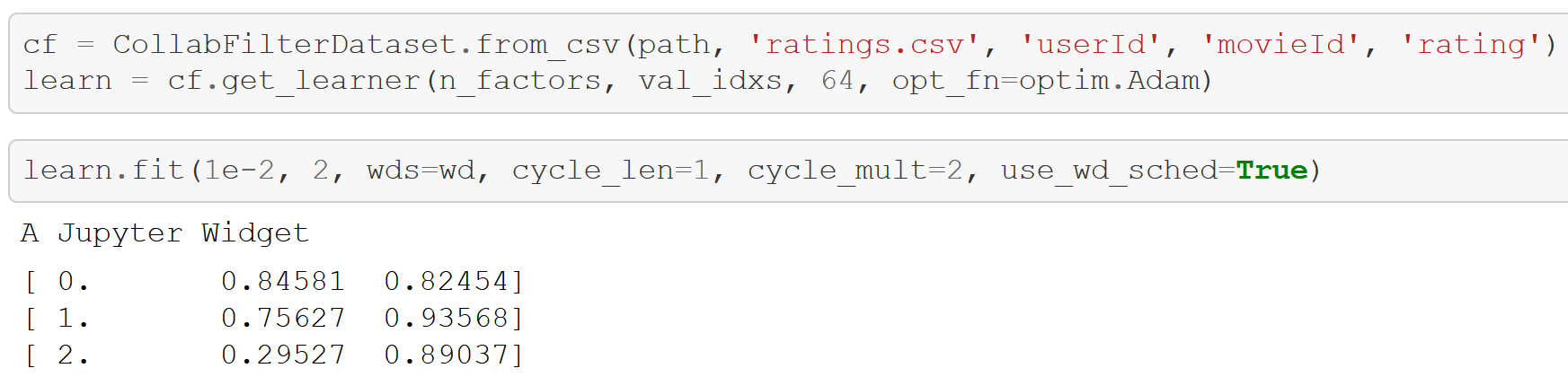
- The same API can be used to train any kind of model with only minor changes - here are examples of training an image classifier, and a recommendation system:

The course also shows how to use Keras with Tensorflow, although it takes a lot more code and compute time to get a much lower accuracy in this case. The basic steps are very similar however, so students can rapidly switch between libraries by using the conceptual understanding developed in the lessons.
Taking your learning further
Part 2 of the 2018 course will be run in San Francisco for 7 weeks from March 19. If you’re interested in attending, please see the details on the in-person course web site.
To discuss this post at Hacker News, click here.