Posted: May 2, 2018
Benchmark results
DAWNBench is a Stanford University project designed to allow different deep learning methods to be compared by running a number of competitions. There were two parts of the Dawnbench competition that attracted our attention, the CIFAR 10 and Imagenet competitions. Their goal was simply to deliver the fastest image classifier as well as the cheapest one to achieve a certain accuracy (93% for Imagenet, 94% for CIFAR 10).
In the CIFAR 10 competition our entries won both training sections: fastest, and cheapest. Another fast.ai student working independently, Ben Johnson, who works on the DARPA D3M program, came a close second in both sections.
In the Imagenet competition, our results were:
- Fastest on publicly available infrastructure, fastest on GPUs, and fastest on a single machine (and faster than Intel’s entry that used a cluster of 128 machines!)
- Lowest actual cost (although DAWNBench’s official results didn’t use our actual cost, as discussed below).
Overall, our findings were:
- Algorithmic creativity is more important than bare-metal performance
- Pytorch, developed by Facebook AI Research and a team of collaborators, allows for rapid iteration and debugging to support this kind of creativity
- AWS spot instances are an excellent platform for rapidly and inexpensively running many experiments.
In this post we’ll discuss our approach to each competition. All of the methods discussed here are either already incorporated into the fastai library, or are in the process of being merged into the library.
Super convergence
fast.ai is a research lab dedicated to making deep learning more accessible, both through education, and developing software that simplifies access to current best practices. We do not believe that having the newest computer or the largest cluster is the key to success, but rather utilizing modern techniques and the latest research with a clear understanding of the problem we are trying to solve. As part of this research we recently developed a new library for training deep learning models based on Pytorch, called fastai.
Over time we’ve been incorporating into fastai algorithms from a number of research papers which we believe have been largely overlooked by the deep learning community. In particular, we’ve noticed a tendency of the community to over-emphasize results from high-profile organizations like Stanford, DeepMind, and OpenAI, whilst ignoring results from less high-status places. One particular example is Leslie Smith from the Naval Research Laboratory, and his recent discovery of an extraordinary phenomenon he calls super convergence. He showed that it is possible to train deep neural networks 5-10x faster than previously known methods, which has the potential to revolutionize the field. However, his paper was not accepted to an academic publishing venue, nor was it implemented in any major software.
Within 24 hours of discussing this paper in class, a fast.ai student named Sylvain Gugger had completed an implementation of the method, which was incorporated into fastai and he also developed an interactive notebook showing how to experiment with other related methods too. In essence, Smith showed that if we very slowly increase the learning rate during training, whilst at the same time decreasing momentum, we can train at extremely high learning rates, thus avoiding over-fitting, and training in far fewer epochs.
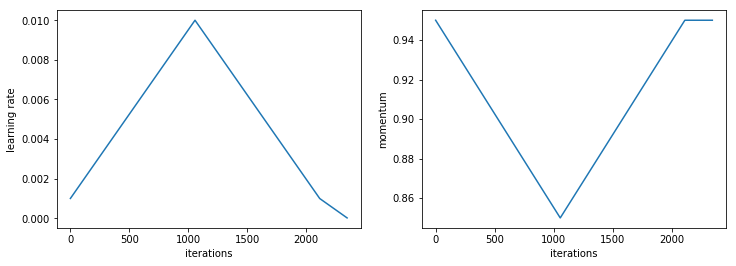
Such rapid turnaround of new algorithmic ideas is exactly where Pytorch and fastai shine. Pytorch allows for interactive debugging, and the use of standard Python coding methods, whilst fastai provides many building blocks and hooks (such as, in this case, callbacks to allow customization of training, and fastai.sgdr for building new learning rate annealing methods). Pytorch’s tensor library and CUDA allow for fast implementation of new algorithms for exploration.
We have an informal deep learning study group (free for anyone to join) that meets each day to work on projects together during the course, and we thought it would be interesting to see whether this newly contributed code would work as well as Smith claimed. We had heard that Stanford University was running a competition called DAWNBench, which we thought would be an interesting opportunity to test it out. The competition finished just 10 days from when we decided to enter, so timing was tight!

CIFAR 10
Both CIFAR 10 and Imagenet are image recognition tasks. For instance, imagine that we have a set of pictures of cats and dogs, and we want to build a tool to separate them automatically. We build a model and then train it on many pictures so that afterwards we can classify dog and cat pictures we haven’t seen before. Next, we can take our model and apply it to larger data sets like CIFAR, a collection of pictures of ten various objects like cats and dogs again as well as other animals/vehicles, for example frogs and airplanes. The images are small (32 pixels by 32 pixels) and so this dataset is small (160MB) and easy to work with. It is, nowadays, a rather under-appreciated dataset, simply because it’s older and smaller than the datasets that are fashionable today. However, it is very representative of the amount of data most organizations have in the real world, and the small image size makes it both challenging but also accessible.
When we decided to enter the competition, the current leader had achieved a result of 94% accuracy in a little over an hour. We quickly discovered that we were able to train a Resnet 50 model with super-convergence in around 15 minutes, which was an exciting moment! Then we tried some different architectures, and found that Resnet 18 (in its preactivation variant) achieved the same result in 10 minutes. We discussed this in class, and Ben Johnson independently further developed this by adding a method fast.ai developed called “concat pooling” (which concatenates max pooling and average pooling in the penultimate layer of the network) and got down to an extraordinary 6 minutes on a single NVIDIA GPU.
In the study group we decided to focus on multi-GPU training, in order to get the fastest result we could on a single machine. In general, our view is that training models on multiple machines adds engineering and sysadmin complexity that should be avoided where possible, so we focus on methods that work well on a single machine. We used a library from NVIDIA called NCCL that works well with Pytorch to take advantage of multiple GPUs with minimal overhead.
Most papers and discussions of multi-GPU training focus on the number of operations completed per second, rather than actually reporting how long it takes to train a network. However, we found that when training on multiple GPUs, our architectures showed very different results. There is clearly still much work to be done by the research community to really understand how to leverage multiple GPUs to get better end-to-end training results in practice. For instance, we found that training settings that worked well on single GPUs tended to lead to gradients blowing up on multiple GPUs. We incorporated all the recommendations from previous academic papers (which we’ll discuss in a future paper) and got some reasonable results, but we still weren’t really leveraging the full power of the machine.
In the end, we found that to really leverage the 8 GPUs we had in the machine, we actually needed to give it more work to do in each batch—that is, we increased the number of activations in each layer. We leveraged another of those under-appreciated papers from less well-known institutions: Wide Residual Networks, from Université Paris-Est, École des Ponts. This paper does an extensive analysis of many different approaches to building residual networks, and provides a rich understanding of the necessary building blocks of these architectures.
Another of our study group members, Brett Koonce, started running experiments with lots of different parameter settings to try to find something that really worked well. We ended up creating a “wide-ish” version of the resnet-34 architecture which, using Brett’s carefully selected hyper-parameters, was able to reach the 94% accuracy with multi-GPU training in under 3 minutes!
AWS and spot instances
We were lucky enough to have some AWS credits to use for this project (thanks Amazon!) We wanted to be able to run many experiments in parallel, without spending more credits than we had to, so study group member Andrew Shaw built out a python library which would allow us to automatically spin up a spot instance, set it up, train a model, save the results, and shut the instance down again, all automatically. Andrew even set things up so that all training occurred automatically in a tmux session so that we could log in to any instance and view training progress at any time.
Based on our experience with this competition, our recommendation is that for most data scientists, AWS spot instances are the best approach for training a large number of models, or for training very large models. They are generally about a third of the cost of on-demand instances. Unfortunately, the official DAWNBench results do not report the actual cost of training, but instead report the cost based on an assumption of on-demand pricing. We do not agree that this is the most useful approach, since in practice spot instance pricing is quite stable, and is the recommended approach for training models of this type.
Google’s TPU instances (now in beta) may also a good approach, as the results of this competition show, but be aware that the only way to use TPUs is if you accept lock-in to all of:
- Google’s hardware (TPU)
- Google’s software (Tensorflow)
- Google’s cloud platform (GCP).
More problematically, there is no ability to code directly for the TPU, which severely limits algorithmic creativity (which as we have seen, is the most important part of performance). Given the limited neural network and algorithm support on TPU (e.g. no support for recurrent neural nets, which are vital for many applications, including Google’s own language translation systems), this limits both what problems you can solve, and how you can solve them.
AWS, on the other hand, allows you to run any software, architecture, and algorithm, and you can then take the results of that code and run them on your own computers, or use a different cloud platform. The ability to use spot instances also means you we were able to save quite a bit of money compared to Google’s platform (Google has something similar in beta called “preemptible instances”, but they don’t seem to support TPUs, and automatically kill your job after 24 hours).
For single GPU training, another great option is Paperspace, which is the platform we use for our new courses. They are significantly less complex to set up than AWS instances, and have the whole fastai infrastructure pre-installed. On the other hand, they don’t have the features and flexibility of AWS. They are more expensive than AWS spot instances, but cheaper that AWS on-demand instances. We used a Paperspace instance to win the cost category of this competition, with a cost of just $0.26.
Half precision arithmetic
Another key to fast training was the use of half precision floating point. NVIDIA’s most recent Volta architecture contains tensor cores that only work with half-precision floating point data. However, successfully training with this kind of data has always been complex, and very few people have shown successful implementations of models trained with this data.
NVIDIA was kind enough to provide an open-source demonstration of training Imagenet using half-precision floating point, and Andrew Shaw worked to incorporate these ideas directly into fastai. We’ve now gotten it to a point where you simply write learn.half() in your code, and from there on all the necessary steps to train quickly and correctly with half-precision floating point are automatically done for you.
Imagenet
Imagenet is a different version of the same problem as CIFAR 10, but with larger images (224 pixels, 160GB) and more categories (1000). Smith showed super convergence on Imagenet in his paper, but he didn’t reach the same level of accuracy as other researchers had on this dataset. We had the same problem, and found that when training with really high learning rates that we couldn’t achieve the required 93% accuracy.
Instead, we turned to a method we’d developed at fast.ai, and teach in lessons 1 & 2 of our deep learning course: progressive resizing. Variations of this technique have shown up in the academic literature before (Progressive Growing of GANs and Enhanced Deep Residual Networks) but have never to our knowledge been applied to image classification. The technique is very simple: train on smaller images at the start of training, and gradually increase image size as you train further. It makes intuitive sense that you don’t need large images to learn the general sense of what cats and dogs look like (for instance), but later on when you’re trying to learn the difference between every breed of dog, you’ll often need larger images.
Many people incorrectly believe that networks trained on one size of images can’t be used for other sizes. That was true back in 2013 when the VGG architecture was tied to one specific size of image, but hasn’t been true since then, on the whole. One problem is that many implementations incorrectly used a fixed-size pooling layer at the end of the network instead of a global/adaptive pooling layer. For instance none of the official pytorch torchvision models use the correct adaptive pooling layer. This kind of issue is exactly why libraries like fastai and keras are important—libraries built by people who are committed to ensuring that everything works out-of-the-box and incorporates all relevant best practices. The engineers building libraries like pytorch and tensorflow are (quite rightly) focused on the underlying foundations, not on the end-user experience.
By using progressive resizing we were both able to make the initial epochs much faster than usual (using 128x128 images instead of the usual 224x224), but also make the final epochs more accurate (using 288x288 images for even higher accuracy). But performance was only half of the reason for this success; the other impact is better generalization performance. By showing the network a wider variety of image sizes, it helps it to avoid over-fitting.
A word on innovation and creativity
I’ve been working with machine learning for 25 years now, and throughout that time I’ve noticed that engineers are drawn to using the biggest datasets they can get, on the biggest machines they can access, like moths flitting around a bright light. And indeed, the media loves covering stories about anything that’s “biggest”. The truth though is that throughout this time the genuine advances consistently come from doings things differently, not doing things bigger. For instance, dropout allows us to train on smaller datasets without over-fitting, batch normalization lets us train faster, and rectified linear units avoid gradient explosions during training; these are all examples of thoughtful researchers thinking about doing things differently, and allowing the rest of us to train better networks, faster.
I worry when I talk to my friends at Google, OpenAI, and other well-funded institutions that their easy access to massive resources is stifling their creativity. Why do things smart when you can just throw more resources at them? But the world is a resource-constrained place, and ignoring that fact means that you will fail to build things that really help society more widely. It is hardly a new observation to point out that throughout history, constraints have been drivers of innovation and creativity. But it’s a lesson that few researchers today seem to appreciate.
Worse still are the people I speak to that don’t have access to such immense resources, and tell me they haven’t bothered trying to do cutting edge research because they assume that without a room full of GPUs, they’ll never be able to do anything of value. To me, they are thinking about the problem all wrong: a good experimenter with a slow computer should always be able to overtake a poor experimenter with a fast one.
We’re lucky that there folks like the Pytorch team that are building the tools that creative practitioners need to rapidly iterate and experiment. I hope that seeing that a small non-profit self-funded research lab and some part-time students can achieve these kinds of top-level results can help bring this harmful myth to an end.
Please read Now anyone can train Imagenet in 18 minutes for further breakthroughs.