This post extends the work described in a previous post, Training Imagenet in 3 hours for $25; and CIFAR10 for $0.26.
A team of fast.ai alum Andrew Shaw, DIU researcher Yaroslav Bulatov, and I have managed to train Imagenet to 93% accuracy in just 18 minutes, using 16 public AWS cloud instances, each with 8 NVIDIA V100 GPUs, running the fastai and PyTorch libraries. This is a new speed record for training Imagenet to this accuracy on publicly available infrastructure, and is 40% faster than Google’s DAWNBench record on their proprietary TPU Pod cluster. Our approach uses the same number of processing units as Google’s benchmark (128) and costs around $40 to run.
DIU and fast.ai will be releasing software to allow anyone to easily train and monitor their own distributed models on AWS, using the best practices developed in this project. The main training methods we used (details below) are: fast.ai’s progressive resizing for classification, and rectangular image validation; NVIDIA’s NCCL with PyTorch’s all-reduce; Tencent’s weight decay tuning; a variant of Google Brain’s dynamic batch sizes, gradual learning rate warm-up (Goyal et al 2018, and Leslie Smith 2018). We used the classic ResNet-50 architecture, and SGD with momentum.
Background
Four months ago, fast.ai (with some of the students from our MOOC and our in person course at the Data Instituate at USF) achieved great success in the DAWNBench competition, winning the competition for fastest training of CIFAR-10 (a small dataset of 25,000 32x32 pixel images) overall, and fastest training of Imagenet (a much larger dataset of over a million megapixel images) on a single machine (a standard AWS public cloud instance). We previously wrote about the approaches we used in this project. Google also put in a very strong showing, winning the overall Imagenet speed category using their “TPU Pod” cluster, which is not available to the public. Our single machine entry took around three hours, and Google’s cluster entry took around half an hour. Before this project, training ImageNet on the public cloud generally took a few days to complete.
We entered this competition because we wanted to show that you don’t have to have huge resources to be at the cutting edge of AI research, and we were quite successful in doing so. We particularly liked the headline from The Verge: “An AI speed test shows clever coders can still beat tech giants like Google and Intel.”
However, lots of people asked us – what would happen if you trained on multiple publicly available machines. Could you even beat Google’s impressive TPU Pod result? One of the people that asked this question was Yaroslav Bulatov, from DIU (the Department of Defense’s Silicon Valley-based experimental innovation unit.) Andrew Shaw (One of our DAWNBench team members) and I decided to team up with Yaroslav to see if we could achieve this very stretch goal. We were encouraged to see that recently AWS had managed to train Imagenet injust 47 minutes, and in their conclusion said: “A single Amazon EC2 P3 instance with 8 NVIDIA V100 GPUs can train ResNet50 with ImageNet data in about three hours [fast.ai] using Super-Convergence and other advanced optimization techniques. We believe we can further lower the time-to-train across a distributed configuration by applying similar techniques.” They were kind enough to share the code for this article as open source, where we found some helpful network configuration tips there to ensure we got the most out of the Linux networking stack and the AWS infrastructures.
Experiment infrastructure
Iterating quickly required solving challenges such as:
- How to easily run multiple experiments across multiple machines, without having a large pool of expensive instances running constantly?
- How to conveniently take advantage of AWS’s spot instances (which are around 70% cheaper than regular instances) but that need to be set up from scratch each time you want to use them?
fast.ai built a system for DAWNBench that included a Python API for launching and configuring new instances, running experiments, collecting results, and viewing progress. Some of the more interesting design decisions in the systems included:
- Not to use a configuration file, but instead configuring experiments using code leveraging a Python API. As a result, we were able to use loops, conditionals, etc to quickly design and run structured experiments, such as hyper-parameter searches
- Writing a Python API wrapper around tmux and ssh, and launching all setup and training tasks inside tmux sessions. This allowed us to later login to a machine and connect to the tmux session, to monitor its progress, fix problems, and so forth
- Keeping everything as simple as possible – avoiding container technologies like Docker, or distributed compute systems like Horovod. We did not use a complex cluster architecture with separate parameter servers, storage arrays, cluster management nodes, etc, but just a single instance type with regular EBS storage volumes.
Independently, DIU faced a similar set of challenges and developed a cluster framework, with analogous motivation and design choices, providing the ability to run many large scale training experiments in parallel. The solution, nexus-scheduler, was inspired by Yaroslav’s experience running machine learning experiments on Google’s Borg system.
The set of tools developed by fast.ai focused on fast iteration with single-instance experiments, whilst the nexus-scheduler developed by DIU was focused on robustness and multi-machine experiments. Andrew Shaw merged parts of the fast.ai software into nexus-scheduler, so that we had the best pieces of each, and we used this for our experiments.
Using nexus-scheduler helped us iterate on distributed experiments, such as:
- Launching multiple machines for a single experiment, to allow distributed training. The machines for a distributed run are automatically put into a placement group, which results in faster network performance
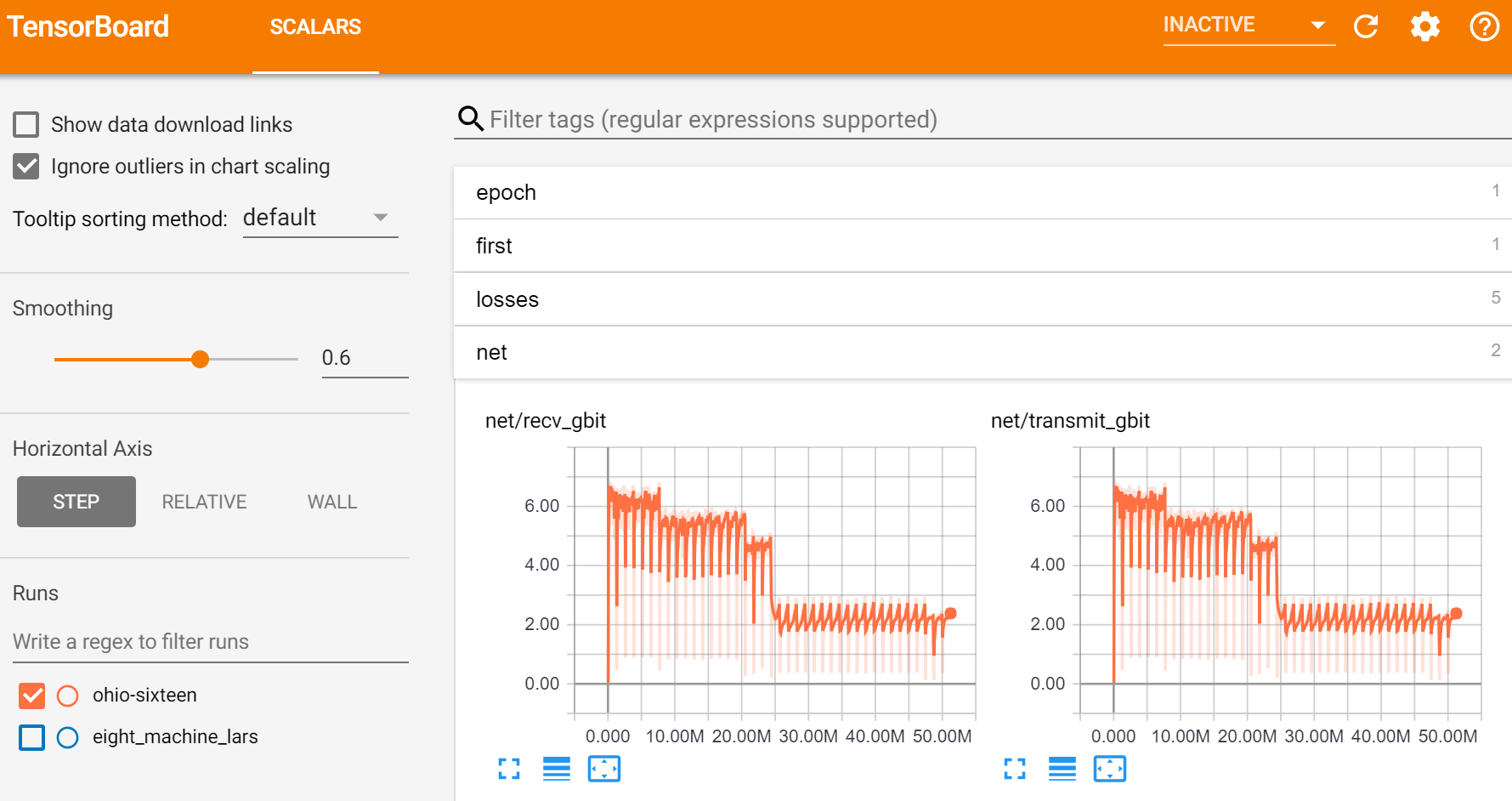
- Providing monitoring through Tensorboard (a system originally written for Tensorflow, but which now works with Pytorch and other libraries) with event files and checkpoints stored on a region-wide file system.
- Automating setup. Various necessary resources for distributed training, like VPCs, security groups, and EFS are transparently created behind the scenes.
AWS provides a really useful API that allowed us to build everything we needed quickly and easily. For distributed computation we used NVIDIA’s excellent NCCL library, which implements ring-style collectives that are integrated with PyTorch’s all-reduce distributed module. We found that AWS’s instances were very reliable and provided consistent performance, which was very important for getting best results from the all-reduce algorithm.
The first official release of nexus-scheduler, including the features merged from the fast.ai tools, is planned for Aug 25th.
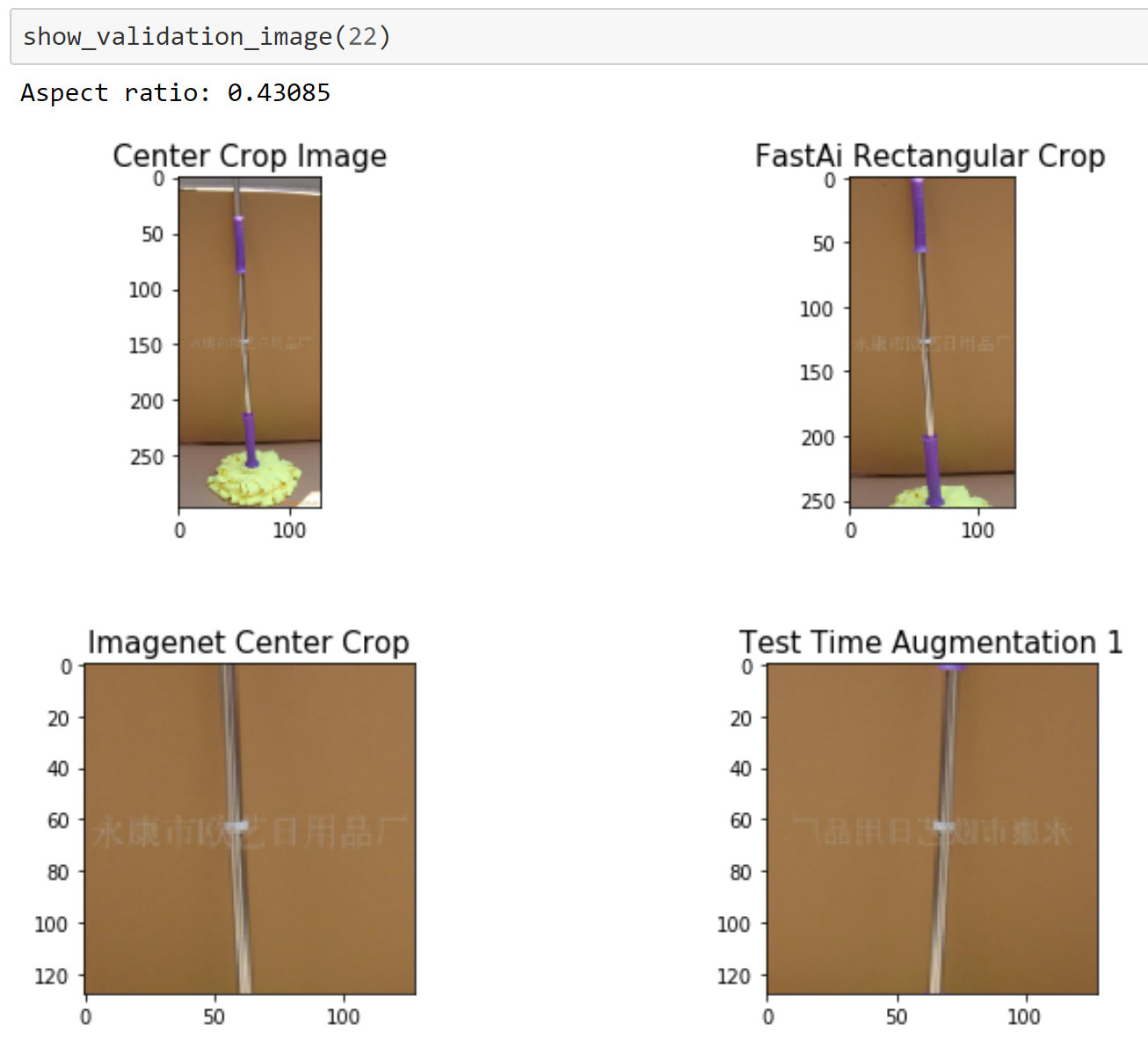
A simple new training trick: rectangles!
I mentioned to Andrew after DAWNBench finished that I thought deep learning practitioners (including us!) were doing something really dumb: we were taking rectangular images (such as those used in Imagenet) and cropping out just the center piece when making predictions. Or a (very slow) alternative widely used is to pick 5 crops (top and bottom left and right, plus center) and average the predictions. Which leaves the obvious question: why not just use the rectangular image directly?
A lot of people mistakenly believe that convolutional neural networks (CNNs) can only work with one fixed image size, and that that must be rectangular. However, most libraries support “adaptive” or “global” pooling layers, which entirely avoid this limitation. It doesn’t help that some libraries (such as Pytorch) distribute models that do not use this feature – it means that unless users of these libraries replace those layers, they are stuck with just one image size and shape (generally 224x224 pixels). The fastai library automatically converts fixed-size models to dynamically sized models.
I’ve never seen anyone try to train with rectangular images before, and haven’t seen them mentioned in any research papers yet, and none of the standard deep learning libraries I’ve found support this. So Andrew went away and figured out how to make it work with fastai and Pytorch for predictions.
The result was amazing – we saw an immediate speedup of 23% in the amount of time it took to reach the benchmark accuracy of 93%. You can see a comparison of the different approaches in this notebook, and compare the accuracy of them in this notebook.
Progressive resizing, dynamic batch sizes, and more
One of our main advances in DAWNBench was to introduce progressive image resizing for classification – using small images at the start of training, and gradually increasing size as training progresses. That way, when the model is very inaccurate early on, it can quickly see lots of images and make rapid progress, and later in training it can see larger images to learn about more fine-grained distinctions.
In this new work, we additionally used larger batch sizes for some of the intermediate epochs – this allowed us to better utilize the GPU RAM and avoid network latency.
Recently, Tencent published a very nice paper showing <7 minute training of Imagenet on 2,048 GPUs. They mentioned a trick we hadn’t tried before, but makes perfect sense: removing weight decay from batchnorm layers. That allowed us to trim another couple of epochs from our training time. (The Tencent paper also used a dynamic learning rate approach developed by NVIDIA research, called LARS, which we’ve also been developing for fastai, but is not included yet in these results.)
The results
When we put all this together, we got a training time of 18 minutes on 16 AWS instances, at a total compute cost (including the cost of machine setup time) of around $40. The benefits of being able to train on datasets of >1 million images are significant, such as:
- Organizations with large image libraries, such as radiology centers, car insurance companies, real estate listing services, and e-commerce sites, can now create their own customized models. Whilst with transfer learning using so many images is often overkill, for highly specialized image types or fine-grained classification (as is common in medical imaging) using larger volumes of data may give even better results
- Smaller research labs can experiment with different architectures, loss functions, optimizers, and so forth, and test on Imagenet, which many reviewers expect to see in published papers
- By allowing the use of standard public cloud infrastructure, no up-front capital expense is required to get started on cutting-edge deep learning research.
Next steps
Unfortunately, big companies using big compute tend to get far more than their fair share of publicity. This can lead to AI commentators coming to the conclusion that only big companies can compete in the most important AI research. For instance, following Tencent’s recent paper, OpenAI’s Jack Clark claimed “for all the industries talk about democratization it’s really the case that advantages accrue to people with big computers”. OpenAI (and Jack Clark) are working to democratize AI, such as through the excellent OpenAI Scholars program and Jack’s informative Import AI newsletter; however, this misperception that success in AI comes down to having bigger computers can distort the research agenda.
I’ve seen variants of the “big results need big compute” claim continuously over the last 25 years. It’s never been true, and there’s no reason that will change. Very few of the interesting ideas we use today were created thanks to people with the biggest computers. Ideas like batchnorm, ReLU, dropout, adam/adamw, and LSTM were all created without any need for large compute infrastructure. And today, anyone can access massive compute infrastructure on demand, and pay for just what they need. Making deep learning more accessible has a far higher impact than focusing on enabling the largest organizations - because then we can use the combined smarts of millions of people all over the world, rather than being limited to a small homogeneous group clustered in a couple of geographic centers.
We’re in the process of incorporating all of the best practices used in this project directly into the fastai library, including automating the selection of hyper-parameters for fast and accurate training.
And we’re not even done yet - we have some ideas for further simple optimizations which we’ll be trying out. We don’t know if we’ll hit the sub seven minute mark of Tencent, since they used a faster network than AWS provides, but there’s certainly plenty of room to go faster still.
Special thanks to the AWS and PyTorch teams who helped us by patiently answering our questions throughout this project, and for the wonderfully pragmatic products that they’ve made available for everyone to use!
You may also be interested in our post, Training Imagenet in 3 hours for $25; and CIFAR10 for $0.26.