Today we’re launching our newest (and biggest!) course, Introduction to Machine Learning for Coders. The course, recorded at the University of San Francisco as part of the Masters of Science in Data Science curriculum, covers the most important practical foundations for modern machine learning. There are 12 lessons, each of which is around two hours long—a list of all the lessons along with a screenshot from each is at the end of this post. They are all taught by me (Jeremy Howard); I’ve been studying and using machine learning for over 25 years, from when I started my career as an Analytical Specialist at McKinsey & Company, through to my time as President and Chief Scientist of Kaggle and founding CEO of Enlitic.
There are some excellent machine learning courses already, most notably the wonderful Coursera course from Andrew Ng. But that course is showing its age now, particularly since it uses Matlab for coursework. This new course uses modern tools and libraries, including python, pandas, scikit-learn, and pytorch. Unlike many educational materials in the field, our approach is “code first” rather than “math first”. It’s well suited to people who are writing code every day, but perhaps aren’t practicing their math chops quite as often (although we do cover all the necessary theory when appropriate). Perhaps most importantly, this course is very opinionated—rather than being a complete survey of every type of model, we focus on those that really matter in practice.
Two main types of models are covered: decision tree based models (particularly “forests” of bagged decision trees), and gradient descent based models (particularly logistic regression and its variants). Decision tree models build structures that look like this (in practice you’ll generally use much larger trees):

(The example above is from Professor Terence Parr and Prince Grover’s excellent discussion of tree visualization techniques, and uses his new animl visualization library. Terence and I are currently writing a book based on the material from this course, and a preview is available of the first chapters. So if you’re more of a book learner than a video learner, be sure to follow that!)
Decision tree methods are extremely flexible and easy to use, and when ensembled (using bagging or boosting) are the state of the art on many practical tasks. However, they can struggle with extrapolating to data outside of that they’re trained on, and are not very accurate for data types such as images, audio, and natural language. These problems are often best solved with gradient descent methods, and we’ll look at some of the most important of these in the second half of the course, closing with a simple deep learning neural network. (If you’ve already taken our Practical Deep Learning for Coders course, you’ll have a small amount of conceptual overlap here, but taught in a very different way.)
You’ll learn how to create a complete decision tree forest implementation from scratch, and write your your deep learning model and train it from scratch. Along the way, you’ll learn many important skills in data preparation, model testing, and product development (including ethical issues specific to data products).
Here’s a quick overview of each lesson, along with an example screenshot (you’ll find the same details on the course site):
Lesson 1 - Introduction to Random Forests
Lesson 1 will show you how to create a “random forest™” - perhaps the most widely applicable machine learning model - to create a solution to the “Bull Book for Bulldozers” Kaggle competition, which will get you in to the top 25% on the leader-board. You’ll learn how to use a Jupyter Notebook to build and analyze models, how to download data, and other basic skills you need to get started with machine learning in practice.
Lesson 2 - Random Forest Deep Dive
Today we start by learning about metrics, loss functions, and (perhaps the most important machine learning concept) over-fitting. We discuss using validation and test sets to help us measure over-fitting.
Then we’ll learn how random forests work - first, by looking at the individual trees that make them up, then by learning about “bagging”, the simple trick that lets a random forest be much more accurate than any individual tree. Next up, we look at some helpful tricks that random forests support for making them faster, and more accurate.
Lesson 3 - Performance, Validation and Model Interpretation
Today we’ll see how to read a much larger dataset - one which may not even fit in the RAM on your machine! And we’ll also learn how to create a random forest for that dataset. We also discuss the software engineering concept of “profiling”, to learn how to speed up our code if it’s not fast enough - especially useful for these big datasets.
Next, we do a deeper dive in to validation sets, and discuss what makes a good validation set, and we use that discussion to pick a validation set for this new data.
In the second half of this lesson, we look at “model interpretation” - the critically important skill of using your model to better understand your data. Today’s focus for interpretation is the “feature importance plot”, which is perhaps the most useful model interpretation technique.
Lesson 4 - Feature Importance, Tree Interpreter
Today we do a deep dive into feature importance, including ways to make your importance plots more informative, how to use them to prune your feature space, and the use of a “dendrogram” to understand feature relationships.
In the second half of the lesson we’ll learn about two more really important interpretation techniques: partial dependence plots, and the “tree interpreter”.
Lesson 5 - Extrapolation and RF from Scratch
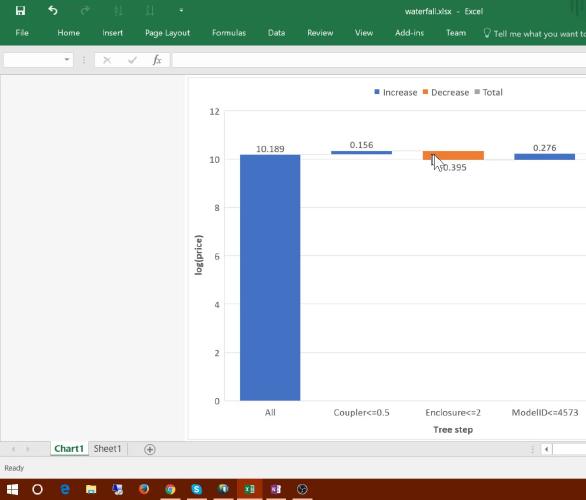
In today’s lesson we start by learning more about the “tree interpreter”, including the use of “waterfall charts” to analyze their output. Next up, we look into the subtle but important issue of extrapolation. This is the weak point of random forests - they can’t predict values outside the range of the input data. We study ways to identify when this problem happens, and how to deal with it.
In the second half of this lesson, we start writing our very own random forest from scratch!
Lesson 6 - Data Products
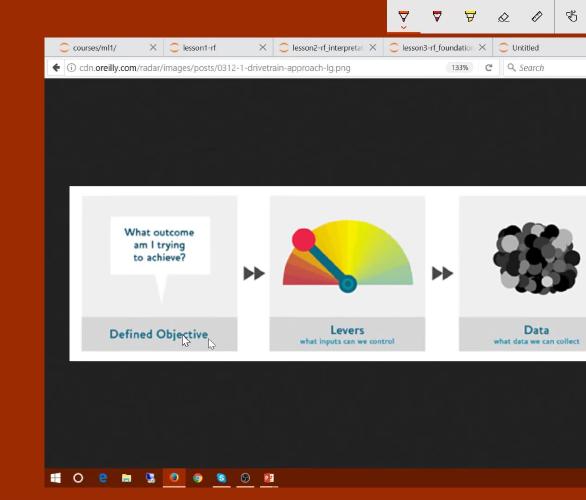
In the first half of today’s lesson we’ll learn about how to create “data products” using machine learning models, based on “The Drivetrain Method”, and in particular how model interpretation is an important part of this approach.
Next up, we’ll explore the issue of extrapolation more deeply, using a Live Coding approach - we’ll also take this opportunity to learn a couple of handy numpy tricks.
Lesson 7 - Random Forest from Scratch
Today we’ll finish off our “from scratch” random forest interpretation! We’ll also briefly look at the amazing “cython” library that you can use to get the same speed as C code with minimal changes to your python code.
Then we’ll start on the next stage of our journey - gradient descent based methods such as logistic regression and neural networks…
Lesson 8 - Gradient Descent and Logistic Regression
Today we start the second half of the course - we’re moving from decision tree based approaches like random forests, to gradient descent based approaches like deep learning.
Our first step in this journey will be to use Pytorch to help us implement logistic regression from scratch. We’ll be building a model for the classic MNIST dataset of hand-written digits.
Lesson 9 - Regularization, Learning Rates and NLP
Today we continue building our logistic regression from scratch, and we add the most important feature to it: regularization. We’ll learn about L1 vs L2 regularization, and how they can be implemented. We also talk more about how learning rates work, and how to pick one for your problem.
In the second half of the lesson, we start our discussion of natural language processing (NLP). We’ll build a “bag of words” representation of the popular IMDb text dataset, using sparse matrices to ensure good performance and reasonable memory use. We’ll build a number of models from this, including naive bayes and logistic regression, and will improve these models by adding ngram features.
Lesson 10 - More NLP, and Columnar Data
In today’s lesson we’ll further develop our NLP model by combining the strengths of naive bayes and logistic regression together, creating the hybrid “NB-SVM” model, which is a very strong baseline for text classification. To do this, we’ll create a new nn.Module class in pytorch, and look at what it’s doing behind the scenes.
In the second half of the lesson we’ll start our study of tabular and relational data using deep learning, by looking at the “Rossmann” Kaggle competition dataset. Today, we’ll start down the feature engineering path on this interesting dataset. We’ll look at continuous vs categorical variables, and what kinds of feature engineering can be done for each, with a particular focus on using embedding matrices for categorical variables.
Lesson 11 - Embeddings
Today, after a review of the math behind naive bayes, we’ll do a deep dive into embeddings - both as used for categorical variables in tabular data, and as used for words in NLP.
Lesson 12 - Complete Rossmann, Ethical Issues
In the first half of today’s class we’ll put everything we’ve learned together to create a complete model for the Rossmann dataset, including both categorical and continuous features, and careful feature engineering for all columns.
In the second half of the class we’ll study some ethical issues that arise when implementing machine learning models. We’ll see why they should matter to practitioners, and ways of thinking about them. Many students have told us they found this the most important part of the course!
