Our newest course is a code-first introduction to NLP, following the fast.ai teaching philosophy of sharing practical code implementations and giving students a sense of the “whole game” before delving into lower-level details. Applications covered include topic modeling, classfication (identifying whether the sentiment of a review is postive or negative), language modeling, and translation. The course teaches a blend of traditional NLP topics (including regex, SVD, naive bayes, tokenization) and recent neural network approaches (including RNNs, seq2seq, attention, and the transformer architecture), as well as addressing urgent ethical issues, such as bias and disinformation. Topics can be watched in any order.
All the code is in Python in Jupyter Notebooks, using PyTorch and the fastai library. You can find all code for the notebooks available on GitHub and all the videos of the lectures are in this playlist.
This course was originally taught in the University of San Francisco MS in Data Science program during May-June 2019. The USF MSDS has been around for 7 years (over 330 students have graduated and gone on to jobs as data scientists during this time!) and is now housed at the Data Institute in downtown SF. In previous years, Jeremy taught the machine learning course and I’ve taught a computational linear algebra elective as part of the program.
Highlights
Some highlights of the course that I’m particularly excited about:
- Transfer learning for NLP
- Tips on working with languages other than English
- Attention and the Transformer
- Text generation algorithms (including the implementation of a new paper from the Allen Institute)
- Issues of bias and some steps towards addressing them
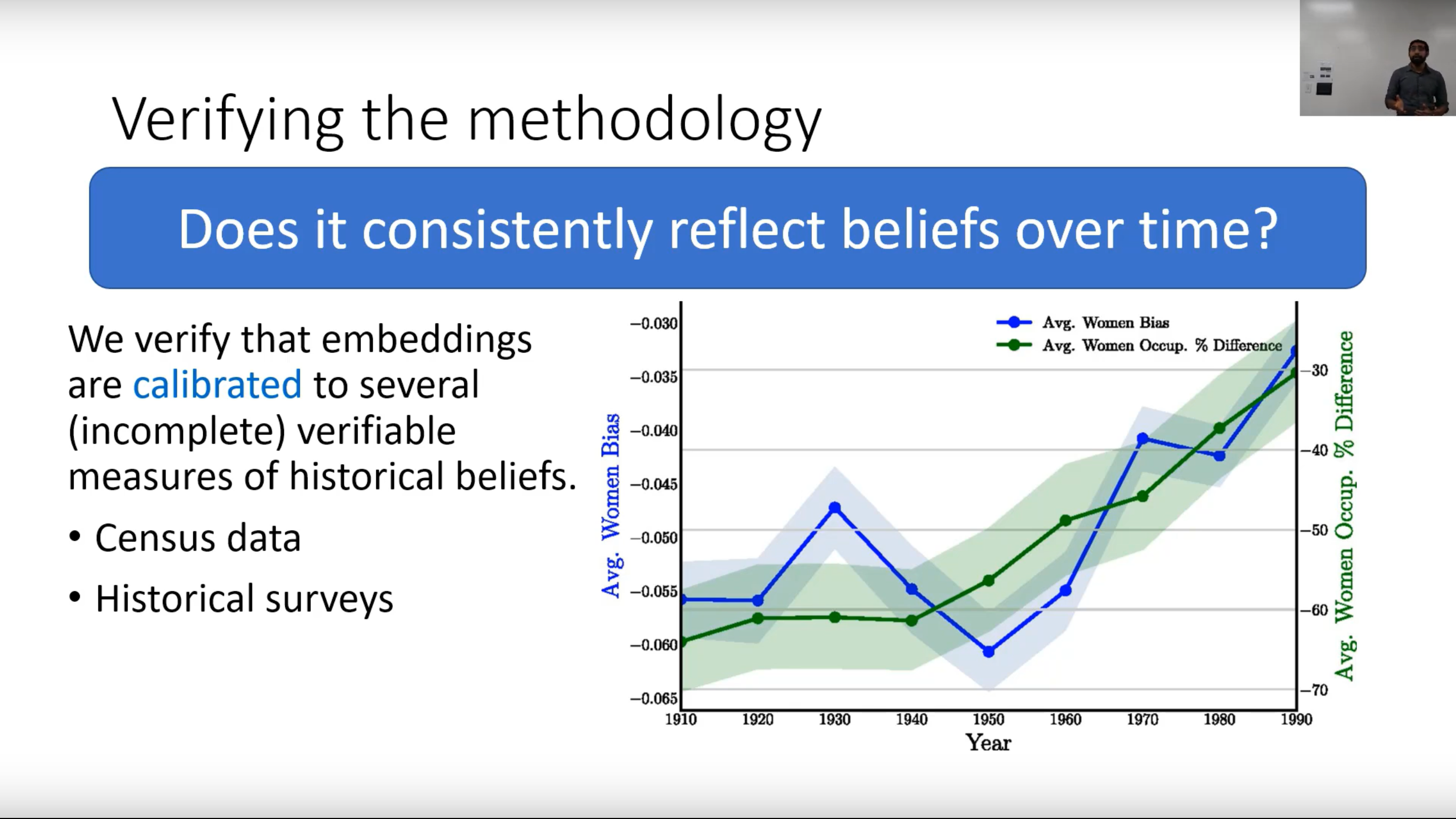
- A special guest lecture by Nikhil Garg on how word embeddings encode stereotypes (and how this has changed over the last 100 years)
- How NLP advances are heightening risks of disinformation

Most of the topics can stand alone, so no need to go through the course in order if you are only interested in particular topics (although I hope everyone will watch the videos on bias and disinformation, as these are important topics for everyone interested in machine learning). Note that videos vary in length between 20-90 minutes.
Course Topics
Overview
There have been many major advances in NLP in the last year, and new state-of-the-art results are being achieved every month. NLP is still very much a field in flux, with best practices changing and new standards not yet settled on. This makes for an exciting time to learn NLP. This course covers a blend of more traditional techniques, newer neural net approaches, and urgent issues of bias and disinformation.
Traditional NLP Methods
For the first third of the course, we cover topic modeling with SVD, sentiment classification via naive bayes and logisitic regression, and regex. Along the way, we learn crucial processing techniques such as tokenization and numericalizaiton.
Deep Learning: Transfer learning for NLP
Jeremy shares jupyter notebooks stepping through ULMFit, his groundbreaking work with Sebastian Ruder last year to successfully apply transfer learning to NLP. The technique involves training a language model on a large corpus, fine-tuning it for a different and smaller corpus, and then adding a classifier to the end. This work has been built upon by more recent papers such as BERT, GPT-2, and XLNet. In new material (accompanying updates to the fastai library), Jeremy shares tips and tricks to work with languages other than English, and walks through examples implementing ULMFit for Vietnamese and Turkish.
- Intro to Language Modeling
- Transfer learning (Jeremy Howard)
- ULMFit for non-English Languages (Jeremy Howard)
Deep Learning: Seq2Seq translation and the Transformer
We will dig into some underlying details of how simple RNNs work, and then consider a seq2seq model for translation. We build up our translation model, adding approaches such as teacher forcing, attention, and GRUs to improve performance. We are then ready to move on to the Transformer, exploring an implementation.
- Understanding RNNs
- Translation with Seq2Seq
- Text generation algorithms (Jeremy Howard)
- Implementing a GRU
- Introduction to the Transformer
- The Transformer for Language Translation
![]()
Ethical Issues in NLP
NLP raises important ethical issues, such as how stereotypes can be encoded in word embeddings and how the words of marginalized groups are often more likely to be classified as toxic. It was a special treat to have Stanford PhD student Nikhil Garg share his work which had been published in PNAS on this topic. We also learn about a framework for better understanding the causes of different types of bias, the importance of questioning what work we should avoid doing altogether, and steps towards addressing bias, such as Data Statements for NLP.
Bias is not the only ethical issue in NLP. More sophisticated language models can create compelling fake prose that may drown out real humans or manipulate public opinion. We cover dynamics of disinformation, risks of compelling computer generated text, OpenAI’s controversial decision of staged release for GPT-2, and some proposed steps towards solutions, such as systems for verification or digital signatures.
- Word embeddings quantify 100 years of gender & ethnic stereotypes (Nikhil Garg)
- Algorithmic Bias
- What you need to know about disinformation

We hope you will check out the course! All the code for the jupyter notebooks used in the class can be found on GitHub and a playlist of all the videos is available on YouTube.
Prerequisites
(Updated to add) Familiarity with working with data in Python, as well as with machine learning concepts (such as training and test sets) is a necessary prerequisite. Some experience with PyTorch and neural networks is helpful.
As always, at fast.ai we recommend learning on an as-needed basis (too many students feel like they need to spend months or even years on background material before they can get to what really interests them, and too often, much of that background material ends up not even being necessary). If you are interested in this course, but unsure whether you have the right background, go ahead and try the course! If you find necessary concepts that you are unfamiliar with, you can always pause and study up on them.
Also, please be sure to check out the fast.ai forums as a place to ask questions and share resources.