This post is licensed under: Creative Commons Attribution-ShareAlike 4.0 International.
As we discussed in Designing Great Data Products, there’s a lot more to creating useful data projects than just training an accurate model! When I used to do consulting, I’d always seek to understand an organization’s context for developing data projects, based on these considerations:
- Strategy: What is the organization trying to do (objective) and what can it change to do it better (levers)?
- Data: Is the organization capturing necessary data and making it available?
- Analytics: What kinds of insights would be useful to the organization?
- Implementation: What organizational capabilities does it have?
- Maintenance: What systems are in place to track changes in the operational environment?
- Constraints: What constraints need to be considered in each of the above areas?
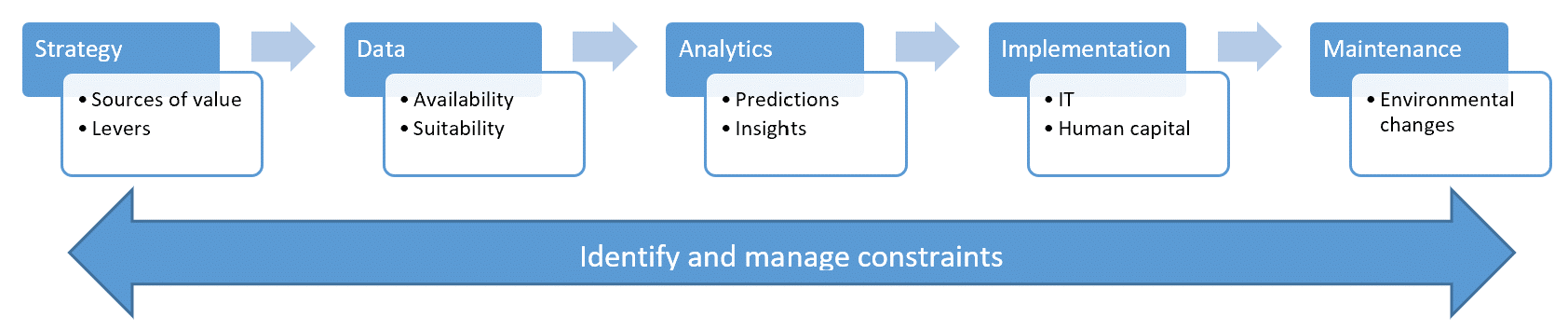
I developed a questionnaire that I had clients fill out before a project started, and then throughout the project I’d help them refine their answers. This questionnaire is based on decades of projects across many industries, including agriculture, mining, banking, brewing, telecoms, retail, and more. Here I am sharing it publicly for the first time.
Organizational
Data scientists
Data scientists should have a clear path to become senior executives, and there should also be hiring plans in place to bring data experts directly into senior executive roles. In a data-driven organization data scientists should be amongst the most well-paid employees. There should be systems in place to allow data scientists throughout the organization to collaborate and learn from each other.
- What data science skills are currently in the organization?
- How are data scientists being recruited?
- How are people with data science skills being identified within the organization?
- What skills are being looked for? How are they being judged? How were those skills selected as being important?
- What data science consulting is being used? In which situations is data science outsourced? How is this work transferred to the organization?
- How much are data scientists being paid? Who do they report to? How are their skills kept current?
- What is the career path for data scientists?
- How many executives have strong data analysis expertise?
- How is work for data scientists selected and allocated?
- What software and hardware do data scientists have access to?
Strategy
All data projects should be based on solving strategically important problems. Therefore, an understanding of business strategy must come first.
- What are the 5 most important strategic issues at the organization today?
- What data is available to help deal with these issues?
- Is a data driven approach being used for these issues? Are data scientists working on these?
- What are the profit drivers that the organization can most strongly impact?
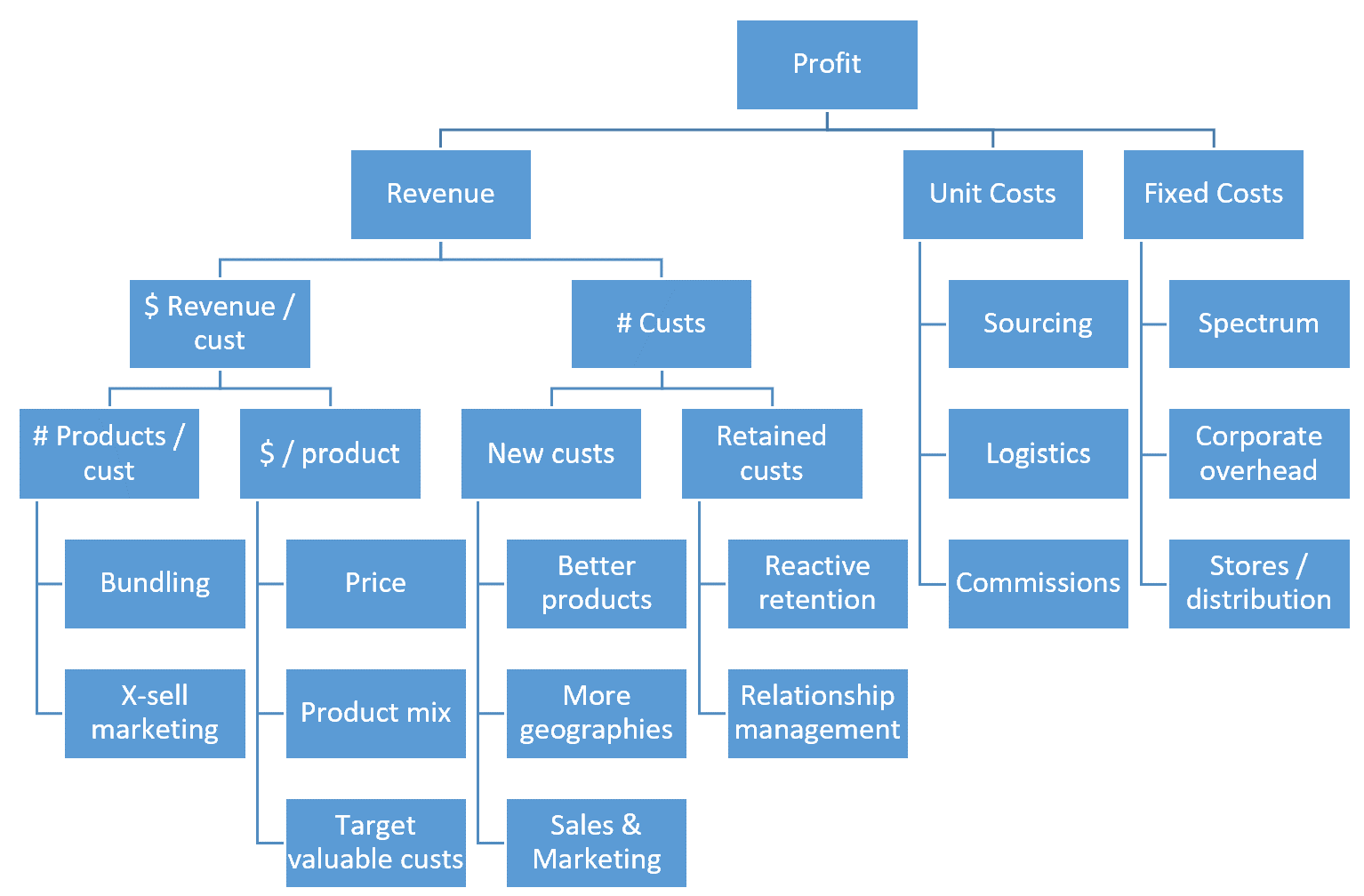
- For each of the most important profit drivers listed above, what are the specific actions and decisions that the organization can take that can influence that driver, including both operational actions (e.g. call customer) and strategic decisions (e.g. release new product)?
- For each of the most important actions and decisions above, what data could be available (either within the organization, or from a vendor, or that could be collected in the future) that may help to better target or optimize that decision?
- Based on the above analysis, what are the biggest opportunities for data-driven analysis within the organization?
- For each opportunity:
- What value driver it is designed to influence?
- What specific actions or decisions it will drive?
- How these actions and decisions will be connected to the results of the project?
- What is the estimated ROI of the impact of each project based on the above?
- What time constraints and deadlines, if any, may impact it?
Data
Without data, we can’t train models! Data also needs to be available, integrated, and verifiable.
- What data platforms does the organization have, including data marts, OLAP cubes, data warehouses, Hadoop clusters, OLTP systems, departmental spreadsheets, and so forth
- Provide any information that has been collated that provides an overview of data availability at the organization, and current work and future plans for building data platforms
- What tools and processes are available to move data between systems and formats?
- How are the data sources accessed by different groups of users and admins?
- What data access tools (e.g. database clients, OLAP clients, in-house software, SAS, etc.) are available for the organization data scientists and for sysadmins? How many people use each of these tools, and what are they positions in the organization?
- How are users informed of new systems, changes to systems, new and changed data elements, and so forth? Provide examples
- How are decisions made regarding data access restrictions? How are requests to access secured data managed? By who? Based on what criteria? How long is the average time to respond? What % of requests are accepted? How is this tracked?
- How does the organization decide when to collect additional data or purchase external data? Provide examples
- What data has been used so far to analyze recent data-driven projects? What has been found to be most useful? What was not useful? How was this judged?
- What additional internal data may provide insights useful for data-driven decision making for proposed projects? External data?
- What are the possible constraints or challenges in accessing or incorporating this data?
- What changes to data collection, coding, integration, etc has occurred in the last 2 years that may impact the interpretation or availability of the collected data
Analytics
Data scientists need to be able to access up to date tools, based on their own particular needs. New tools should be regularly assessed to see if they significantly improve over current approaches.
- What analytics tools are used at the organization, by who? How are they selected, configured, and maintained?
- What is the process to get additional analytical tools set up on a client machine? What is the average time to complete this? What is the % requests accepted?
- How are analytical systems built by external consultants transferred to the organization? Are external contractors asked to restrict the systems used to ensure the results conform to internal infrastructure?
- In what situations has cloud processing been used? What are the plans for using the cloud?
- In what situations have external experts been used for specialist analytics? How has this been managed? How have the experts been identified and selected?
- What analytic tools have been tried for recent projects?
- What worked, and what didn’t? Why?
- Provide any outputs that are available from work done to date for these projects
- How have the results of this analysis been judged? What metrics? Compared to what benchmarks? How do you know whether a model is “good enough”?
- In what situations does the organization use visualization, vs. tabular reporting, vs. predictive modelling (and similar machine learning tools)? For more advanced modelling approaches, how are the models calibrated and tested? Provide examples
Implementation
IT constraints are often the downfall of data projects. Be sure to consider them up front!
- Provide some examples of past data-driven projects which have had successful, and unsuccessful implementations, and provide details on the IT integration and human capital challenges and how they were faced
- How are the validity of analytical models confirmed prior to implementation? How are they benchmarked?
- How are the performance requirements defined for analytical project implementations (in terms of speed and accuracy)?
- For the proposed projects provide information about:
- What IT systems will be used to support the data driven decisions and actions
- How this IT integration will be done
- What alternatives there are which may require less IT integration
- What jobs will be impacted by the data driven approaches
- How these staff will be trained, monitored, and supported
- What implementation challenges may occur
- Which stakeholders will be needed to ensure implementation success? How might they perceive these projects and their potential impact on them?
Maintenance
Unless you track your models carefully, you may find them leading you to disaster.
- How are analytical systems built by third parties maintained? When are they transferred to internal teams?
- How are the effectiveness of models tracked? When does the organization decide to rebuild models?
- How are data changes communicated internally, and how are they managed?
- How do data scientists work with software engineers to ensure algorithms are correctly implemented?
- When are test cases developed, and how are they maintained?
- When is refactoring performed on code? How is the correctness and performance of models maintained and validated during refactoring?
- How are maintenance and support requirements logged? How are these logs used?
Constraints
For each project being considered enumerate potential constraints that may impact the success of the project, e.g.:
- Will IT systems need to be modified or developed to use the results of the project? Are there simpler implementations that could avoid substantial IT changes? If so, would this simplified implementation result in a significant reduction in impact?
- What regulatory constraints exist on data collection, analysis, or implementation? Has the specific legislation and precedents been examined recently? What workarounds might exist?
- What organizational constraints exist, including culture, skills, or structure?
- What management constraints are there?
- Are there any past analytic projects which may impact how the organization resources would view data-driven approaches?