This paper is about fastai v2. There is a PDF version of this paper available on arXiv; it has been peer reviewed and will be appearing in the open access journal Information. fastai v2 is currently in pre-release; we expect to release it officially around July 2020. The pre-release is feature complete, although the documentation isn’t complete. There is a dedicated forum available for discussing fastai v2. Jeremy will be teaching a course about deep learning with fastai v2 in San Francisco starting in March 2020. An O’Reilly book by us (Jeremy and Sylvain) about deep learning with fastai and PyTorch is available for pre-order, for expected delivery July 2020.
Abstract: fastai is a deep learning library which provides practitioners with high-level components that can quickly and easily provide state-of-the-art results in standard deep learning domains, and provides researchers with low-level components that can be mixed and matched to build new approaches. It aims to do both things without substantial compromises in ease of use, flexibility, or performance. This is possible thanks to a carefully layered architecture, which expresses common underlying patterns of many deep learning and data processing techniques in terms of decoupled abstractions. These abstractions can be expressed concisely and clearly by leveraging the dynamism of the underlying Python language and the flexibility of the PyTorch library. fastai includes:
- A new type dispatch system for Python along with a semantic type hierarchy for tensors
- A GPU-optimized computer vision library which can be extended in pure Python
- An optimizer which refactors out the common functionality of modern optimizers into two basic pieces, allowing optimization algorithms to be implemented in 4-5 lines of code
- A novel 2-way callback system that can access any part of the data, model, or optimizer and change it at any point during training
- A new data block API
- …and much more.
We have used this library to successfully create a complete deep learning course, which we were able to write more quickly than using previous approaches, and the code was more clear. The library is already in wide use in research, industry, and teaching.
Contents
Introduction
fastai is a modern deep learning library, available from GitHub as open source under the Apache 2 license, which can be installed directly using the conda or pip package managers. It includes complete documentation and tutorials, and is the subject of the book Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD (Howard and Gugger 2020).
fastai is organized around two main design goals: to be approachable and rapidly productive, while also being deeply hackable and configurable. Other libraries have tended to force a choice between conciseness and speed of development, or flexibility and expressivity, but not both. We wanted to get the clarity and development speed of Keras (Chollet and others 2015) and the customizability of PyTorch. This goal of getting the best of both worlds has motivated the design of a layered architecture. A high-level API powers ready-to-use functions to train models in various applications, offering customizable models with sensible defaults. It is built on top of a hierarchy of lower level APIs which provide composable building blocks. This way, a user wanting to rewrite part of the high-level API or add particular behavior to suit their needs doesn’t have to learn how to use the lowest level.
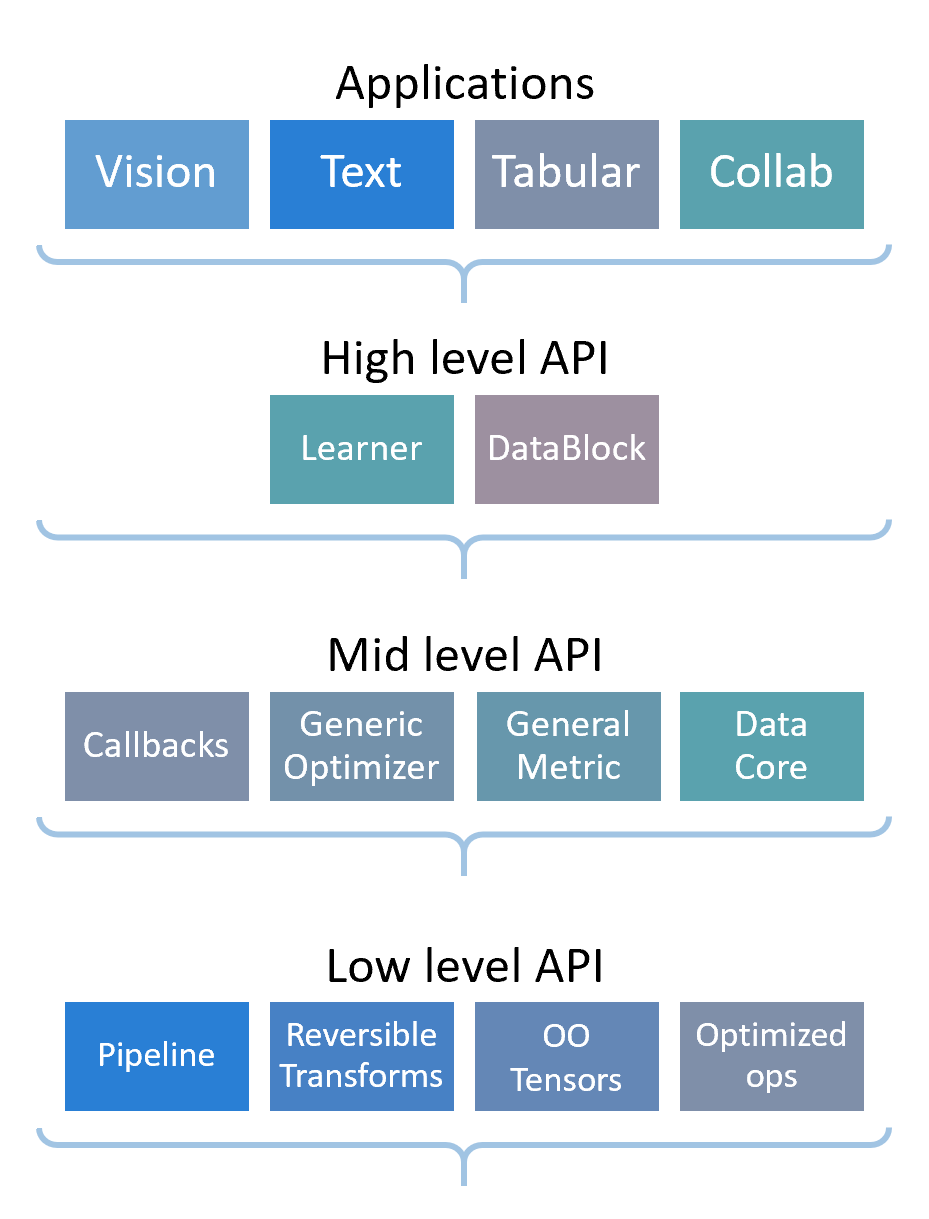
The high-level of the API is most likely to be useful to beginners and to practitioners who are mainly in interested in applying pre-existing deep learning methods. It offers concise APIs over four main application areas: vision, text, tabular and time-series analysis, and collaborative filtering. These APIs choose intelligent default values and behaviors based on all available information. For instance, fastai provides a single Learner class which brings together architecture, optimizer, and data, and automatically chooses an appropriate loss function where possible. Integrating these concerns into a single class enables fastai to curate appropriate default choices. To give another example, generally a training set should be shuffled, and a validation does not need to be. So fastai provides a single DataLoaders class which automatically constructs validation and training data loaders with these details already handled. This helps practitioners ensure that they don’t make mistakes such as failing to include a validation set. In addition, because the training set and validation set are integrated into a single class, fastai is able, by default, always to display metrics during training using the validation set.
This use of intelligent defaults–based on our own experience or best practices–extends to incorporating state-of-the-art research wherever possible. For instance, transfer learning is critically important for training models quickly, accurately, and cheaply, but the details matter a great deal. fastai automatically provides transfer learning optimised batch-normalization (Ioffe and Szegedy 2015) training, layer freezing, and discriminative learning rates (Howard and Ruder 2018). In general, the library’s use of integrated defaults means it requires fewer lines of code from the user to re-specify information or merely to connect components. As a result, every line of user code tends to be more likely to be meaningful, and easier to read.
The mid-level API provides the core deep learning and data-processing methods for each of these applications, and low-level APIs provide a library of optimized primitives and functional and object-oriented foundations, which allows the mid-level to be developed and customised. The library itself is built on top of PyTorch (Paszke et al. 2017), NumPy (Oliphant, n.d.), PIL (Clark and Contributors, n.d.), pandas (McKinney 2010), and various other libraries. In order to achieve its goal of hackability, the library does not aim to supplant or hide these lower levels or these foundation. Within a fastai model, one can interact directly with the underlying PyTorch primitives; and within a PyTorch model, one can incrementally adopt components from the fastai library as conveniences rather than as an integrated package.
We believe fastai meets its design goals. A user can create and train a state-of-the-art vision model using transfer learning with four understandable lines of code. Perhaps more tellingly, we have been able to implement recent deep learning research papers with just a couple of hours work, whilst matching the performance shown in the papers. We have also used the library for our winning entry in the DawnBench competition (Cody A. Coleman and Zahari 2017), training a ResNet-50 on ImageNet to accuracy in 18 minutes.
The following sections describe the main functionality of the various API levels in more detail and review prior related work. We chose to include a lot of code to illustrate the concepts we are presenting. While that code made change slightly as the library or its dependencies evolve (it is running against fastai v2.0.0), the ideas behind stay the same. The next section reviews the high-level APIs “out-of-the-box” applications for some of the most used deep learning domains. The applications provided are vision, text, tabular, and collaborative filtering.
Applications
Vision
Here is an example of how to fine tune an ImageNet (Deng et al. 2009) model on the Oxford IIT Pets dataset (Parkhi et al. 2012) and achieve close to state-of-the-art accuracy within a couple of minutes of training on a single GPU:
from fastai.vision.all import *
path = untar_data(URLs.PETS)
dls = ImageDataLoaders.from_name_re(path=path, bs=64,
fnames = get_image_files(path/"images"), pat = r'/([^/]+)_\d+.jpg$',
item_tfms=RandomResizedCrop(450, min_scale=0.75),
batch_tfms=[*aug_transforms(size=224, max_warp=0.), Normalize.from_stats(*imagenet_stats)])
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(4)This is not an excerpt; these are all of the lines of code necessary for this task. Each line of code does one important task, allowing the user to focus on what they need to do, rather than minor details. Let’s look at each line in turn:
This first line imports all the necessary pieces from the library. fastai is designed to be usable in a read–eval–print loop (REPL) environment as well as in a complex software system. Even if using the “import ” syntax is not generally recommended, REPL programmers generally prefer the symbols they need to be directly available to them, which is why fastai supports the ”import ” style. The library is carefully designed to ensure that importing in this way only imports the symbols that are actually likely to be useful to the user and avoids cluttering the namespace or shadowing important symbols.
The second line downloads a standard dataset from the fast.ai datasets collection (if not previously downloaded) to a configurable location (~/.fastai/data by default), extracts it (if not previously extracted), and returns a pathlib.Path object with the extracted location.
This line sets up the DataLoaders object. This is an abstraction that represents a combination of training and validation data and will be described more in a later section. DataLoaders can be flexibly defined using the data block API (see 3.1), or, as here, can be built for specific predefined applications using specific subclasses. In this case, the ImageDataLoaders subclass is created using a regular expression labeller. Many other labellers are provided, particularly focused on labelling based on different kinds of file and folder name patterns, which are very common across a wide range of datasets.
One interesting feature of this API, which is also shared by lower level fastai data APIs, is the separation of item level and batch level transforms. Item transforms are applied, in this case, to individual images on the CPU. Batch transforms, on the other hand, are applied to a mini batch, on the GPU if available. While fastai supports data augmentation on the GPU, images need to be of the same size before being batched. aug_transforms() selects a set of data augmentations that work well across a variety of vision datasets and problems and can be fully customized by providing parameters to the function. This is a good example of a simple “helper function”; it is not strictly necessary, because the user can list all the augmentations that they require using the individual data augmentation classes. However, by providing a single function which curates best practices and makes the most common types of customization available through a single function, users have fewer pieces to learn in order to get good results.
After defining a DataLoaders object the user can easily look at the data with a single line of code:

This fourth line creates a Learner, which provides an abstraction combining an optimizer, a model, and the data to train it – this will be described in more detail in 4.1. Each application has a customized function that creates a Learner, which will automatically handle whatever details it can for the user. For instance, in this case it will download an ImageNet-pretrained model, if not already available, remove the classification head of the model, replace it with a head appropriate for this particular dataset, and set appropriate defaults for the optimizer, weight decay, learning rate, and so forth (except where overridden by the user).
The fifth line fits the model. In this case, it is using the 1cycle policy (Smith 2018), which is a recent best practice for training and is not widely available in most deep learning libraries by default. It is annealing both the learning rates, and the momentums, printing metrics on the validation set, displaying results in an HTML table (if run in a Jupyter Notebook, or a console table otherwise), recording losses and metrics after every batch to allow plotting later, and so forth. A GPU will be used if one is available.
After training a model the user can view the results in various ways, including analysing the errors with show_results():

Here is another example of a vision application, this time for segmentation on the CamVid dataset (Brostow et al. 2008):
from fastai.vision.all import *
path = untar_data(URLs.CAMVID)
dls = SegmentationDataLoaders.from_label_func(path=path, bs=8,
fnames = get_image_files(path/"images"),
label_func = lambda o: path/'labels'/f'{o.stem}_P{o.suffix}',
codes = np.loadtxt(path/'codes.txt', dtype=str),
batch_tfms=[*aug_transforms(size=(360,480)), Normalize.from_stats(*imagenet_stats)])
learn = unet_learner(dls, resnet34, metrics=acc_segment)
learn.fit_one_cycle(8, pct_start=0.9)The lines of code to create and train this model are almost identical to those for a classification model, except for those necessary to tell fastai about the differences in the processing of the input data. The exact same line of code that was used for the image classification example can also be used to display the segmentation data:

Furthermore, the user can also view the results of the model, which again are visualized automatically in a way suitable for this task:

Text
In modern natural language processing (NLP), perhaps the most important approach to building models is through fine tuning pre-trained language models. To train a language model in fastai requires very similar code to the previous examples (here on the IMDb dataset (Maas et al. 2011)):
from fastai.text.all import *
path = untar_data(URLs.IMDB_SAMPLE)
df_tok,count = tokenize_df(pd.read_csv(path/'texts.csv'), ['text'])
dls_lm = TextDataLoaders.from_df(df_tok, path=path,
vocab=make_vocab(count), text_col='text', is_lm=True)
learn = language_model_learner(dls_lm, AWD_LSTM, metrics=Perplexity()])
learn.fit_one_cycle(1, 2e-2, moms=(0.8,0.7,0.8))Fine-tuning this model for classification requires the same basic steps:
The same API is also used to view the DataLoaders:

The biggest challenge with creating text applications is often the processing of the input data. fastai provides a flexible processing pipeline with predefined rules for best practices, such as handling capitalization by adding tokens. For instance, there is a compromise between lower-casing all text and losing information, versus keeping the original capitalisation and ending up with too many tokens in your vocabulary. fastai handles this by adding a special single token representing that the next symbol should be treated as uppercase or sentence case and then converts the text itself to lowercase. fastai uses a number of these special tokens. Another example is that a sequence of more than three repeated characters is replaced with a special repetition token, along with a number of repetitions and then the repeated character. These rules largely replicate the approaches discussed in (Howard and Ruder 2018) and are not normally made available as defaults in most NLP modelling libraries.
The tokenization is flexible and can support many different organizers. The default used is Spacy. A SentencePiece tokenizer (Kudo and Richardson 2018) is also provided by the library. Subword tokenization (Wu et al. 2016) (Kudo 2018), such as that provided by SentencePiece, has been used in many recent NLP breakthroughs (Radford et al. 2019) (Devlin et al. 2018).
Numericalization and vocabulary creation often requires many lines of code, and careful management here fails and caching. In fastai that is handled transparently and automatically. Input data can be provided in many different forms, including: a separate file on disk for each document, delimited files in various formats, and so forth. The API also allows for complete customisation. SentencePiece is particularly useful for handling multiple languages and was used in MultiFIT (Eisenschlos et al. 2019), along with fastai, for this purpose. This provided models and state-of-the-art results across many different languages using a single code base.
fastai’s text models are based on AWD-LSTM (Merity, Keskar, and Socher 2017). The user community have provided external connectors to the popular HuggingFace Transformers library (Wolf et al. 2019). The training of the models proceeds in the same way as for the vision examples with defaults appropriate for these models automatically selected. We are not aware of other libraries that provide direct support for transfer learning best practices in NLP, such as those shown in (Howard and Ruder 2018). Because the tokenisation is built on top of a layered architecture, users can replace the base tokeniser with their own choices and will automatically get support for the underlying parallel process model provided by fastai. It will also automatically handle serialization of intermediate outputs so that they can be reused in future processing pipelines.
The results of training the model can be visualised with the same API as used for image models, shown in a way appropriate for NLP:

Tabular
Tabular models have not been very widely used in deep learning; Gradient boosting machines and similar methods are more commonly used in industry and research settings. However, there have been examples of competition winning approaches and academic state-of-the-art results using deep learning (Brébisson et al. 2015). Deep learning models are particularly useful for datasets with high cardinality categorical variables because they provide embeddings that can be used even for non-deep learning models (Guo and Berkhahn 2016). One of the challenges is there has not been examples of libraries which directly support best practices for tabular modelling using deep learning.
The pandas library (McKinney 2010) already provides excellent support for processing tabular data sets, and fastai does not attempt to replace it. Instead, it adds additional functionality to pandas DataFrames through various pre-processing functions, such as automatically adding features that are useful for modelling with date data. fastai also provides features for automatically creating appropriate DataLoaders with separated validation and training sets, using a variety of mechanisms, such as randomly splitting rows, or selecting rows based on some column.
The code to create and train a model suitable for this data should look familiar, there is just information specific to tabular data requires when building the DataLoaders object.
from fastai2.tabular.all import *
path = untar_data(URLs.ADULT_SAMPLE)
df = pd.read_csv(path/'adult.csv')
dls = TabularDataLoaders.from_df(df, path,
procs=[Categorify, FillMissing, Normalize],
cat_names=['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race'],
cont_names=['age', 'fnlwgt', 'education-num'],
y_names='salary', valid_idx=list(range(1024,1260)), bs=64)
learn = tabular_learner(dls, layers=[200,100], metrics=accuracy)
learn.fit_one_cycle(3)
As for every other application, dls.show_batch and learn.show_results will display a DataFrame with some samples.
fastai also integrates with NVIDIA’s cuDF library, providing end-to-end GPU optimized data processing and model training. fastai is the first deep learning framework to integrate with cuDF in this way.
Collaborative filtering
Collaborative filtering is normally modelled using a probabilistic matrix factorisation approach (Mnih and Salakhutdinov 2008). In practice however, a dataset generally has much more than just (for example) a user ID and a product ID, but instead has many characteristics of the user, product, time period, and so forth. It is quite standard to use those to train a model, therefore, fastai attempts to close the gap between collaborative filtering and tabular modelling. A collaborative filtering model in fastai can be simply seen as a tabular model with high cardinality categorical variables. A classic matrix factorisation model is also provided. Both are trained using the same steps that we’ve seen in the other applications, as in this example using the popular Movielens dataset (Harper and Konstan 2015):
Deployment
fastai is mostly focused on model training, but once this is done you can easily export the PyTorch model to serve it in production. The command Learner.export will serialize the model as well as the input pipeline (just the transforms, not the training data) to be able to apply the same to new data.
The library provides Learner.predict and Learner.get_preds to evaluate the model on on item or a new inference DataLoader. Such a DataLoader can easily be built from a set of items with the command test_dl.
High-level API design considerations
High-level API foundations
The high-level API is that which is used by people using these applications. All the fastai applications share some basic components. One such component is the visualisation API, which uses a small number of methods, the main ones being show_batch (for showing input data) and show_results (for showing model results). Different types of model and datasets are able to use this consistent API because of fastai’s type dispatch system, a lower-level component which will be discussed in 5.3. The transfer learning capability shared across the applications relies on PyTorch’s parameter groups, and fastai’s mid-level API then leverages these groups, such as the generic optimizer (see 4.3).
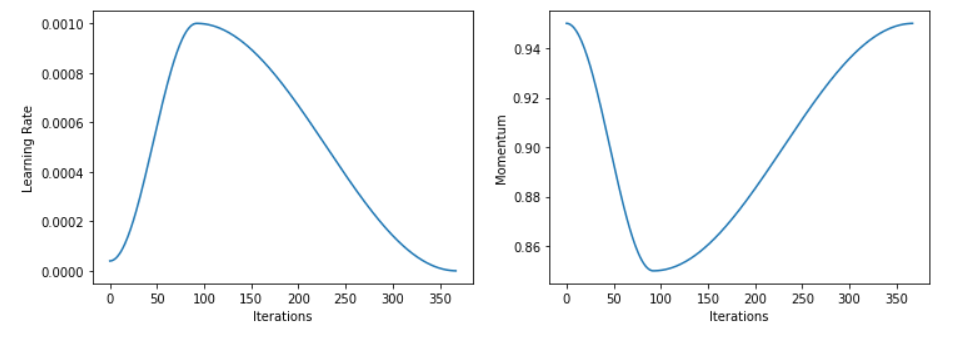
In all those applications, the Learner obtained gets the same functionality for the model training. The recommended way of training models using a variant of the 1cycle policy (Smith 2018) which uses a warm-up and annealing for the learning rate while doing the opposite with the momentum parameter:
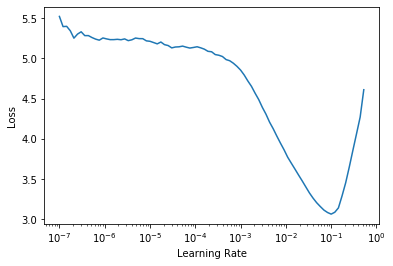
The learning rate is the most important hyper-parameter to tune (and very often the only one since the library sets proper defaults). Other libraries often provide help for grid search or AutoML to guess the best value, but the fastai library implements the learning rate finder (Smith 2015) which much more quickly provides the best value for this parameter after a mock training. The command learn.lr_find() will return a graph like this:
Another important high-level API component, which is shared across all of the applications, is the data block API. The data block API is an expressive API for data loading. It is the first attempt we are aware of to systematically define all of the steps necessary to prepare data for a deep learning model, and give users a mix and match recipe book for combining these pieces (which we refer to as data blocks). The steps that are defined by the data block API are:
- Getting the source items,
- Splitting the items into the training set and one or more validation sets,
- Labelling the items,
- Processing the items (such as normalization), and
- Optionally collating the items into batches.
Here is an example of how to use the data block API to get the MNIST dataset (LeCun, Cortes, and Burges 2010) ready for modelling:
In fastai v1 and earlier we used a fluent instead of a functional API for this (meaning the statements to execute those steps were chained one after the other). We discovered that this was a mistake; while fluent APIs are flexible in the order in which the user can define the steps, that order is very important in practice. With this functional DataBlock you don’t have to remember if you need to split before or after labelling your data, for instance. Also, fluent APIs, at least in Python, tend not to work well with auto completion technologies. The data processing can be defined using Transforms (see 5.2). Here is an example of using the data blocks API to complete the same segmentation seen earlier:
path = untar_data(URLs.CAMVID_TINY)
camvid = DataBlock(blocks=(ImageBlock, ImageBlock(cls=PILMask)),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=lambda o: path/'labels'/f'{o.stem}_P{o.suffix}')
dls = camvid.databunch(path/"images",
batch_tfms=[*aug_transforms(), Normalize.from_stats(*imagenet_stats)])Object detection can also be completed using the same functionality (here using the COCO dataset (Lin et al. 2014)):
coco_source = untar_data(URLs.COCO_TINY)
images, lbl_bbox = get_annotations(coco_source/'train.json')
lbl = dict(zip(images, lbl_bbox))
coco = DataBlock(blocks=(ImageBlock, BBoxBlock, BBoxLblBlock),
get_items=get_image_files,
splitter=RandomSplitter(),
getters=[noop, lambda o:lbl[o.name][0], lambda o:lbl[o.name][1]],
n_inp=1)
dls = coco.databunch(coco_source, item_tfms=Resize(128),
batch_tfms=[*aug_transforms(), Normalize.from_stats(*imagenet_stats)])In this case, the targets are a tuple of two things: a list of bounding boxes and a list of labels. This is why there are three blocks, a list of getters and an extra argument to specify how many of the blocks should be considered the input (the rest forming the target).
The data for language modeling seen earlier can also be built using the data blocks API:
We have heard from users that they find the data blocks API provides a good balance of conciseness and expressivity. Many libraries have provided various approaches to data processing. In the data science domain the scikit-learn (Pedregosa et al. 2011) pipeline approach is widely used. This API provides a very high level of expressivity, but is not opinionated enough to ensure that a user completes all of the steps necessary to get their data ready for modelling. As another example, TensorFlow (Abadi et al. 2015) provides the tf.data library, which does not as precisely map the steps necessary for users to complete their task to the functionality provided by the API. The Torchvision (Massa and Chintala, n.d.) library is a good example of an API which is highly specialised to a small subset of data processing tasks for a specific subdomain. fastai tries to capture the benefits of both extremes of the spectrum, without compromises; the data blocks API is how most users transform their data for use with the library.
Incrementally adapting PyTorch code
Users often need to use existing pure PyTorch code (i.e. code that doesn’t use fastai), such as their existing code-bases developed without fastai, or using third party code written in pure PyTorch. fastai supports incrementally adding fastai features to this code, without requiring extensive rewrites.
For instance, at the time of writing, the official PyTorch repository includes a MNIST training example1. In order to train this example using fastai’s Learner only two steps are required. First, the 30 lines in the example covering the test() and train() functions can be removed. Then, the 4 lines of the training loop is replaced with this code:
With no other changes, the user now has the benefit of all fastai’s callbacks, progress reporting, integrated schedulers such as 1cycle training, and so forth.
Consistency across domains
As the application examples have shown, the fastai library allows training a variety of kinds of application models, with a variety of kinds of datasets, using a very consistent API. The consistency covers not just the initial training, but also visualising and exploring the input data and model outputs. Such consistency helps students, both through having less to learn, and through showing the unifying concepts across different types of model. It also helps practitioners and researchers focus on their model development rather than learning incidental differences between APIs across domains. It is of particular benefit when, for instance, an NLP expert tries to bring their expertise across to a computer vision application.
There are many libraries that provide high level APIs to specific applications, such as Facebook’s Torchvision (Massa and Chintala, n.d.), Detectron (Girshick et al. 2018), and Fairseq (Ott et al. 2019). However, each library has a different API, input representation, and requires different assumptions about training details, all of which a user must learn from scratch each time. This means that there are many deep learning practitioners and researchers who become specialists in specific subfields, partially based on their understanding of the toiling of those subfields. By providing a consistent API fastai users are able to quickly move between different fields and reuse their expertise.
Customizing the behaviour of predefined applications can be challenging, which means that researchers often end up “reinventing the wheel”, or, constraining themselves to the specific parts which there tooling allows them to customize. Because fastai provides a layered architecture, users of the software can customize every part, as they need. The layered architecture is also an important foundation in allowing PyTorch users to incrementally add fastai functionality to existing code bases. Furthermore, fastai’s layers are reused across all applications, so an investment in learning them can be leveraged across many different projects.
The approach of creating layered APIs has a long history in software engineering. Software engineering best practices involve building up decoupled components which can be tied together in flexible ways, and then creating increasingly less abstract and more customized layers on top of each part.
The layered API design is also important for researchers and practitioners aiming to create best in class results. As the field of deep learning matures, there are more and more architectures, optimizers, data processing pipelines, and other approaches that can be selected from. Trying to bring multiple approaches together into a single project can be extremely challenging, when each one is using a different, incompatible API, and has different expectations about how a model is trained. For instance, in the original mixup article (Zhang et al. 2017), the code provided by the researchers only works on one specific dataset, with one specific set of metrics, and with one specific optimizer. Attempting to combine the researchers’ mixup code with other training best practices, such as mixed precision training (Micikevicius et al. 2017), requires rewriting it largely from scratch. The next section will look at the mid-level API pieces that fastai provides, which can be mixed and matched together to allow custom approaches to be quickly and reliably created.
Mid-level APIs
Many libraries, including fastai version 1 or earlier, provide a high-level API to users, and a low-level API used internally for that functionality, but nothing in between. This has two problems: the first is that it becomes harder and harder to create additional high-level functionality, as the system becomes more sophisticated, because the low-level API becomes increasingly complicated and cluttered. The second problem is that for users of the system who want to customize and adapt it, they often have to rewrite significant parts of the high-level API, and understand the large surface area of the low-level API in order to do so. This tends to mean that only a small dedicated community of specialists can really customize the software.
These issues are common across nearly all software development, and many software engineers have worked hard to find ways to deal with this complexity and develop layered architectures. The issue in the deep learning community, however, is that these practices have not seemed to be widely understood or adopted. There are, however, exceptions; most relevant to this paper, the PyTorch library (Paszke et al. 2017) has a carefully layered design and is highly customizable.
Much of the innovation in fastai is in its new mid-level APIs. This section will look at the following mid-level APIs: data, callbacks, optimizer, model layers, and metrics. These APIs are what the four fastai applications are built with and are also fully documented and available to users so that they can build their own applications or customize the existing ones.
Learner
As already noted, a library can provide more appropriate defaults and user-friendly behaviour by ensuring that classes have all the information they need to make appropriate choices. One example of this is the DataLoaders class, which brings together all the information necessary for creating the data required for modelling. fastai also provides the Learner class, which brings together all the information necessary for training a model based on the data. The information which Learner requires, and is stored as state within a learner object, is: a PyTorch model, and optimizer, a loss function, and a DataLoaders object. Passing in the optimizer and loss function is optional, and in many situations fastai can automatically select appropriate defaults.
Learner is also responsible (along with Optimizer) for handling fastai’s transfer learning functionality. When creating a Learner the user can pass a splitter. This is a function that describes how to split the layers of a model into PyTorch parameter groups, which can then be frozen, trained with different learning rates, or more generally handled differently by an optimizer.
One area that we have found particularly sensitive in transfer learning is the handling of batch-normalization layers (Ioffe and Szegedy 2015). We tried a wide variety of approaches to training and updating the moving average statistics of those layers, and different configurations could often change the error rate by as much as 300%. There was only one approach that consistently worked well across all datasets that we tried, which is to never freeze batch-normalization layers, and never turn off the updating of their moving average statistics. Therefore, by default, Learner will bypass batch-normalization layers when a user asks to freeze some parameter groups. Users often report that this one minor tweak dramatically improves their model accuracy and is not something that is found in any other libraries that we are aware of.
DataLoaders and Learner also work together to ensure that model weights and input data are all on the same device. This makes working with GPUs significantly more straightforward and makes it easy to switch from CPU to GPU as needed.
Two-way callbacks
In fastai version 0.7, we repeatedly modified the training loop in Learner to support many different tweaks and customizations. Over time, however, this became unwieldy. We noticed that there was a core subset of functionality that appeared in every one of these tweaks, and that all the other changes that were required could be refactored into a specific set of customization points. In other words, a wide variety of training methods can be represented using a single, universal training system. Once we extracted those common pieces, we were left with the basic fastai training loop, and the customisation points that we call two-way callbacks.
The Learner class’s novel 2-way callback system allows gradients, data, losses, control flow, and anything else to be read and changed at any point during training. There is a rich history of using callbacks to allow for customisation of numeric software, and today nearly all modern deep learning libraries provide this functionality. However, fastai’s callback system is the first that we are aware of that supports the design principals necessary for complete two-way callbacks:
- A callback should be available at every single point that code can be run during training, so that a user can customise every single detail of the training method ;
- Every callback should be able to access every piece of information available at that stage in the training loop, including hyper-parameters, losses, gradients, input and target data, and so forth ;
This is the way callbacks are usually designed, but in addition, there is a key design principal:
- Every callback should be able to modify all these pieces of information, at any time before they are used, and be able to skip a batch, epoch, training or validation section, or cancel the whole training loop.
This is why we call these 2-way callbacks, as the information not only flows from the training loop to the callbacks, but on the other way as well. For instance, here is the code for training a single batch b in fastai:
try:
self._split(b); self.cb('begin_batch')
self.pred = self.model(*self.x); self.cb('after_pred')
if len(self.y) == 0: return
self.loss = self.loss_func(self.pred, *self.y); self.cb('after_loss')
if not self.training: return
self.loss.backward(); self.cb('after_back')
self.opt.step(); self.cb('after_step')
self.opt.zero_grad()
except CancelBatchException: self.cb('after_cancel')
finally: self.cb('after_batch')
This example clearly shows how every step of the process is associated with a callback (the calls to self.cb() and shows how exceptions are used as a flexible control flow mechanism for them.
In fastai v0.7, we did not follow these three design principles. As a result, we had to frequently change the training loop to support additional functionality, and new research papers. On the other hand, with this new callback system we have not had to change the training loop at all, and have used callbacks to implement mixup augmentation, generative adversarial networks, optimized mixed precision training, PyTorch hooks, the learning rate finder, and many more. Most importantly, we have not yet come across any cases where mixing and matching these callbacks has caused any problems. Therefore, users can use all the training features that they want, and can easily do ablation studies, adding, removing, and modifying techniques as needed.
Case study: generative adversarial network training using callbacks
A good example of a fastai callback is GANTrainer, which implements training of generative adversarial networks (Goodfellow et al. 2014). To do so, it must complete the following tasks:
-
Freeze the generator and train the critic for one (or more) step by:
- getting one batch of “real” images ;
- generating one batch of “fake” images;
- have the critic evaluate each batch and compute a loss function from that, which rewards positively the detection of real images and penalizes the fake ones;
- update the weights of the critic with the gradients of this loss.
-
Freeze the critic and train the generator for one (or more) step by:
- generating one batch of “fake” images;
- evaluate the critic on it;
- return a loss that rewards positively the critic thinking those are real images;
- update the weights of the generator with the gradients of this loss.
To do so, it relies on a GANModule that contains the generator and the critic, then delegates the input to the proper model depending on the value of a flag gen_mode and on a GANLoss that also has a generator or critic behavior and handles the evaluation mentioned earlier. Then, it defines the following callback methods:
-
begin_fit: Initialises the generator, critic, loss functions, and internal storage -
begin_epoch: Sets the critic or generator to training mode -
begin_validate: Switches to generator mode for showing results -
begin_batch: Sets the appropriate target depending on whether it is in generator or critic mode -
after_batch: Records losses to the generator or critic log -
after_epoch: Optionally shows a sample image
This callback is then customized with another callback, which defines at what point to switch from critic to generator and vice versa. fastai includes several possibilities for this purpose, such as an AdaptiveGANSwitcher, which automatically switches between generator and critic training based on reaching certain thresholds in their respective losses. This approach to training can allow models to be trained significantly faster and more easily than with standard fixed schedule approaches.
Generic optimizer
fastai provides a new generic optimizer foundation that allows recent optimization techniques to be implemented in a handful of lines of code, by refactoring out the common functionality of modern optimizers into two basic pieces:
- stats, which track and aggregate statistics such as gradient moving averages ;
- steppers, which combine stats and hyper-parameters to update the weights using some function.
This has allowed us to implement every optimizer that we have attempted in fastai, without needing to extend or change this foundation. This has been very beneficial, both for research and development. As an example of a development improvement, here are the entire changes needed to make to support decoupled weight decay (also known as AdamW (Loshchilov and Hutter 2017)):
On the other hand, the implementation in the PyTorch library required creating an entirely new class, with over 50 lines of code. The benefit for research comes about because it it easy to rapidly implement new papers as they come out, recognise similarities and differences across techniques, and try out variants and combinations of these underlying differences, many of which have not yet been published. The resulting code tends to look a lot like the maths shown in the paper. For instance, here is the code in fastai, and the algorithm from the paper, for the LAMB optimizer (You et al. 2019):

The only difference between the code and the figure are:
- the means that update mt and vt don’t appear as this done in a separate function stat;
- the authors do not provide the full definition of the ϕ function they use (it depends on undefined parameters), the code below is based on the official TensorFlow implementation.
In order to support modern optimizers such as LARS fastai allows the user to choose whether to aggregate stats at model, layer, or per activation level.
Generalized metric API
Nearly all machine learning and deep learning libraries provide some support for metrics. These are generally defined as simple functions which take the mean, or in some cases a custom reduction function, across some measurement which is logged during training. However, some metrics cannot be correctly defined using this framework. For instance, the dice coefficient, which is widely used for measuring segmentation accuracy, cannot be directly expressed using a simple reduction.
In order to provide a more flexible foundation to support metrics like this fastai provides a Metric abstract class which defines three methods: reset, accumulate, and value (which is a property). Reset is called at the start of training, accumulate is called after each batch, and then finally value is called to calculate the final check. Whenever possible, we can thus avoid recording and storing all predictions in memory. For instance, here is the definition of the dice coefficient:
class Dice(Metric):
def __init__(self, axis=1): self.axis = axis
def reset(self): self.inter,self.union = 0,0
def accumulate(self, learn):
pred,targ = flatten_check(learn.pred.argmax(self.axis), learn.y)
self.inter += (pred*targ).float().sum().item()
self.union += (pred+targ).float().sum().item()
@property
def value(self): return 2. * self.inter/self.union if self.union>0 else None
The Scikit-learn library (Pedregosa et al. 2011) already provides a wide variety of useful metrics, so instead of reinventing them, fastai provides a simple wrapper function, skm_to_fastai, which allows them to be used in fastai, and can automatically add pre-processing steps such as sigmoid, argmax, and thresholding.
fastai.data.external
Many libraries have recently started integrating access to external datasets directly into their APIs. fastai builds on this trend, by curating and collecting a number of datasets (hosted by the AWS Public Dataset Program2) in a single place and making them available through the fastai.data.external module. fastai automatically downloads, extracts, and caches these datasets when they are first used. This is similar to functionality provided by Torchvision, TensorFlow datasets, and similar libraries, with the addition of closer integration into the fastai ecosystem. For instance, fastai provides cut-down “sample” versions of many of its datasets, which are small enough that they can be downloaded and used directly in documentation, continuous integration testing, and so forth. These datasets are also used in the documentation, along with examples showing users what they can expect when training models with his datasets. Because the documentation is written in interactive notebooks (as discussed in a later section) this also means that users can directly experiment with these datasets and models by simply running and modifying the documentation notebooks.
funcs_kwargs and DataLoader
Once a user has their data available, they need to get it into a form that can be fed to a PyTorch model. The most common class used to feed models directly is the DataLoader class in PyTorch. This class provides fast and reliable multi-threaded data-processing execution, with several points allowing customisation. However, we have found that it is not flexible enough to conveniently do some of the tasks that we have required, such as building a DataLoader for an NLP language model. Therefore, fastai includes a new DataLoader class on top of the internal classes that PyTorch uses. This combines the benefits of the fast and reliable infrastructure provided by PyTorch with a more flexible and expressive front-end for the user.
DataLoader provides 15 extension points via customizable methods, which can be replaced by the user as required. These customizable methods represent the 15 stages of data loading that we have identified, and which fit into three broad stages: sample creation, item creation, and batch creation. In contrast, in the standard PyTorch DataLoader class only a small subset of these stages is explicitly made available for customization by the user. Unless a user’s requirements are met by this subset, the user is forced to implement their own solution from scratch. The impact of this additional customizability can be quite significant. For instance, the fastai language model DataLoader went from 90 lines of code to 30 lines of code after adopting this approach.
What makes this flexibility possible is a Python decorator that is called funcs_kwargs. This decorator creates a class in which any method can be replaced by passing a new function to the constructor, or by replacing it through subclassing. This allows users to replace any part of the logic in the DataLoader class. In order to maximise the power of this, nearly every part of the fastai DataLoader is a method with a single line of code. Therefore, virtually every design choice can be adjusted by users.
fastai also provides a transformed DataLoader called TfmdDL, which subclasses DataLoader. In TfmdDL the callbacks and customization points execute Pipelines of Transforms. Both mechanisms are described in 5.2; this section provides a brief overview here. A Transform is simply a Python function, which can also include its inverse function – that is, the function which “undoes” the transform. Transforms can be composed using the Pipeline class, which then allows the entire function composition to be inverted as well. We refer to these two directions, the forward and inverse directions of the functions, as the Transforms’ encodes and decodes methods.
TfmdDL provides the foundations for the visualisation support discussed in the application section, having the basic template for showing a batch of data. In order to do this, it needs to decode any transforms in the pipeline, which it does automatically. For instance, an integer representing a level of a category will be converted back into the string that the integer represents.
fastai.data.core
When users who need to create a new kind of block for the data blocks API, or need a level of customization that even the data blocks API doesn’t support, they can use the mid-level components that the data block API is built on. These are a small number of simple classes which combine the transform pipelines functionality of fastai with Python’s collections interface.
The most basic class is transformed list, or TfmdLists, which lazily applies a transform pipeline to a collection, whilst providing a standard Python collection interface. This is an important foundational functionality for deep learning, such as the ability to index into a collection of filenames, and on demand read an image file then apply any processing, such as data augmentation and normalization, necessary for a model. TfmdLists also provides subset functionality, which allows the user to define subsets of the data, such as those representing training and validation sets. Information about what subset an item belongs to is passed down to transforms, so that they can ensure that they do the appropriate processing – for instance, data augmentation processing would be generally skipped for a validation set, unless doing test time augmentation.
Another important data class at this layer of the API is Datasets, which applies multiple transform pipelines in parallel to a single collection. Like TfmdLists, it provides a standard Python collection interface. Indexing into a Datasets object returns a couple containing the result of each transform pipeline on the input item. This is the class used by the data blocks API to return, for instance, a tuple of an image tensor, and a label for that image, both derived from the same input filename.
Layers and architectures
PyTorch (like many other libraries) provides a basic “sequential” layer object, which can be combined in sequence to form a component of a network. This represents simple composition of functions, where each layer’s output is the next layer’s input. However, many components in modern network architectures cannot be represented in this way. For instance, ResNet blocks (He et al. 2015), and any other block which requires a skip connection, are not compatible with sequential layers. The normal workaround for this in PyTorch is to write a custom forward function, effectively relying on the full flexibility of Python to escape the limits of composing these sequence layers.
However, there is a significant downside: the model is now no longer amenable to easy analysis and modification, such as removing the final few layers in order to do transfer learning. This also makes it harder to support automatic drawing graphs representing a model, printing a model summary, accurately reporting on model computation requirements by layer, and so forth.
Therefore, fastai attempts to provide the basic foundations to allow modern neural network architectures to be built by stacking a small number of predefined building blocks. The first piece of this system is the SequentialEx layer. This layer has the same basic API as PyTorch’s nn.Sequential, with one key difference: the original input value to the function is available to every layer in the block. Therefore, the user can, for instance, include a layer which adds the current value of the sequential block to the input value of the sequential block (such as is done in a ResNet).
To take full advantage of this capability, fastai also provides a MergeLayer class. This allows the user to pass any function, which will in turn be provided with the layer block input value, and the current value of the sequential block. For instance, if you pass in a simple add function, then MergeLayer provides the functionality of an identity connection in a standard resnet block. Or, if the user passes in a concatenation function, then it provides the basic functionality of a concatenating connection in a Densenet block (Huang, Liu, and Weinberger 2016). In this way, fastai provides primitives which allow representing modern network architecture out of predefined building blocks, without falling back to Python code in the forward function.
fastai also provides a general-purpose class for combining these layers into a wide range of modern convolutional neural network architectures. These are largely based on the underlying foundations from ResNet (He et al. 2015), and therefore this class is called XResNet. By providing parameters to this class, the user can customise it to create architectures that include squeeze and excitation blocks (Hu, Shen, and Sun 2017), grouped convolutions such as in ResNext (Xie et al. 2017), depth-wise convolutions such as in the Xception architecture (Chollet 2016), widening factors such as in Wide ResNets (Zagoruyko and Komodakis 2016), self-attention and symmetric self-attention functionality , custom activation functions, and more. By using this generic refactoring of these clusters of modern neural network architectures, we have been able to design and experiment with novel combinations very easily. It is also clearer to users exactly what is going on in their models, because the various specific architectures are clearly represented as changes to input parameters.
One set of techniques that is extremely useful in practice are the tweaks to the ResNet architecture described in (He et al. 2018). These approaches are used by default in XResNet. Another architecture tweak which has worked well in many situations is the recently developed Mish activation function (Misra 2019). fastai includes an implementation of Mish which is optimised using PyTorch’s just-in-time compiler (JIT).
A similar approach has been used to refactor the U-Net architecture (Ronneberger, Fischer, and Brox 2015). Through looking at a range of competition winning and state-of-the-art papers in segmentation, we curated a set of approaches that work well together in practice. These are made available by default in fastai’s U-Net implementation, which also dynamically creates the U-Net cross connections for any given input size.
Low-level APIs
The layered approach of the fastai library has a specific meaning at the lower levels of it stack. Rather than treating Python (Python Core Team 2019) itself as the base layer of the computation, which the middle layer relies on, those layers rely on a set of basic abstractions provided by the lower layer. The middle layer is programmed in that set of abstractions. The low-level of the fastai stack provides a set of abstractions for:
- Pipelines of transforms: Partially reversible composed functions mapped and dispatched over elements of tuples
- Type-dispatch based on the needs of data processing pipelines
-
Attaching semantics to tensor objects, and ensuring that these semantics are maintained throughout a
Pipeline - GPU-optimized computer vision operations
- Convenience functionality, such as a decorator to make patching existing objects easier, and a general collection class with a NumPy-like API.
The rest of this section will explain how the transform pipeline system is built on top of the foundations provided by PyTorch, type dispatch, and semantic tensors, providing the flexible infrastructure needed for the rest of fastai.
PyTorch foundations
The main foundation for fastai is the PyTorch (Paszke et al. 2017) library. PyTorch provides a GPU optimised tensor class, a library of useful model layers, classes for optimizing models, and a flexible programming model which integrates these elements. fastai uses building blocks from all parts of the PyTorch library, including directly patching its tensor class, entirely replacing its library of optimizers, providing simplified mechanisms for using its hooks, and so forth. In earlier prototypes of fastai we used TensorFlow (Abadi et al. 2015) as our platform (and before that used (Theano Development Team 2016)), but switched to PyTorch because we found that it had a fast core, a simple and well curated API, and rapidly growing popularity in the research community. At this point most papers at the top deep learning conferences are implemented using PyTorch.
fastai builds on many other open source libraries. For CPU image processing fastai uses and extends the Python imaging library (PIL) (Clark and Contributors, n.d.), for reading and processing tabular data it uses pandas, for most of its metrics it uses Scikit-Learn (Pedregosa et al. 2011), and for plotting it uses Matplotlib (Hunter 2007). These are the most widely used libraries in the Python open source data science community and provide the features necessary for the fastai library.
Transforms and Pipelines
One key motivation is the need to often be able to undo some subset of transformations that are applied to create the data used to modelling. This strings that represent categories cannot be used in models directly and are turned into integers using some vocabulary. And pixel values for images are generally normalized. Neither of these can be directly visualized, and therefore at inference time we need to apply the inverse of these functions to get data that is understandable. Therefore, fastai introduces a Transform class, which provides callable objects, along with a decode method. The decode method is designed to invert the function provided by a transform; it needs to be implemented manually by the user ; it is similar to the inverse_transform you can provide in Scikit-Learn (Pedregosa et al. 2011) pipelines and transformers. By providing both the encode and decode methods in a single place, the user ends up with a single object which they can compose into pipelines, serialize, and so forth.
Another motivation for this part of the API is the insight that PyTorch data loaders provide tuples, and PyTorch models expect tuples as inputs. Sometimes these tuples should behave in a connected and dependent way, such as in a segmentation model, where data augmentation must be applied to both the independent and dependent variables in the same basic way. Sometimes, however, different implementations must be used for different types; for instance, when doing affine transformations to a segmentation mask nearest-neighbor interpolation is needed, but for an image generally a smoother interpolation function would be used.
In addition, sometimes transforms need to be able to opt out of processing altogether, depending on context. For instance, except when doing test time augmentation, data augmentation methods should not be applied to the validation set. Therefore, fastai automatically passes the current subset index to transforms, allowing them to modify their behaviour based on subset (for instance, training versus validation). This is largely hidden from the user, because base classes are provided which automatically do this context-dependent skipping. However, advanced users requiring complete customization can use this functionality directly.
Transforms in deep learning pipelines often require state, which can be dependent on the input data. For example, normalization statistics could be based on a sample of data batches, a categorization transform could get its vocabulary directly from the dependent variable, or an NLP numericalization transform could get its vocabulary from the tokens used in the input corpus. Therefore, fastai transforms and pipelines support a setup method, which can be used to create this state when setting up a Pipeline. When pipelines are set up, all previous transforms in the pipeline are run first, so that the transform being set up receives the same structure of data that it will when being called.
This is closely connected to the implementation of TfmdList. Because a TfmdList lazily applies a pipeline to a collection, fastai can automatically call the Pipeline setup method as soon as it is connected to the collection in a TfmdList.
Type dispatch
The fastai type dispatch system is like the functools.singledispatch system provided in the Python standard library while supporting multiple dispatch over two parameters. Dispatch over two parameters is necessary for any situation where the user wants to be able to customize behavior based on both the input and target of a model. For instance, fastai uses this for the show_batch and show_results methods. As shown in the application section, these methods automatically provide an appropriate visualisation of the input, target, and results of a model, which requires responding to the types of both parameters. In one example the input was an image, and the target was a segmentation mask, and the show results method automatically used a colour-coded overlay for the mask. On the other hand, for an image classification problem, the input would be shown as an image, the prediction and target would be shown as text labels, and color-coded based on whether they were correct.
It also provides a more expressive and yet concise syntax for registering additional dispatched functions or methods, taking advantage of Python’s recently introduced type annotations syntax. Here is an example of creating two different methods which dispatch based on parameter types:
Here f_td_test has a generic implementation for x of numeric types and all ys, then a specialized implementation when x is an int and y is a float.
Object-oriented semantic tensors
By using fastai’s transform pipeline functionality, which depends heavily on types, the mid and high-level APIs can provide a lot of power, conciseness, and expressivity for users. However, this does not work well with the types provided by PyTorch, since the basic tensor type does not have any subclasses which can be used for type dispatch. Furthermore, subclassing PyTorch tensors is challenging, because the basic functionality for instantiating the subclasses is not provided and doing any kind of tensor operation will strip away the subclass information.
Therefore, fastai provides a new tensor base class, which can be easily instantiated and subclass. fastai also patches PyTorch’s tensor class to attempt to maintain subclass information through operations wherever possible. Unfortunately, it is not possible to always perfectly maintain this information throughout every possible operation, and therefore all fastai Transform automatically maintain subclass types appropriately.
fastai also provides the same functionality for Python imaging library classes, along with some basic type hierarchies for Python built-in collection types, NumPy arrays, and so forth.
GPU-accelerated augmentation
The fastai library provides most data augmentation in computer vision on the GPU at the batch level. Historically, the processing pipeline in computer vision has always been to open the images and apply data augmentation on the CPU, using a dedicated library such as PIL (Clark and Contributors, n.d.) or OpenCV (Bradski 2000), then batch the results before transferring them to the GPU and using them to train the model. On modern GPUs however, architectures like a standard ResNet-50 are often CPU-bound. Therefore fastai implements most common functions on the GPU, using PyTorch’s implementation of grid_sample (which does the interpolation from the coordinate map and the original image).
Most data augmentations are random affine transforms (rotation, zoom, translation, etc), functions on a coordinates map (perspective warping) or easy functions applied to the pixels (contrast or brightness changes), all of which can easily be parallelized and applied to a batch of images. In fastai, we combine all affine and coordinate transforms in one step to only apply one interpolation, which results in a smoother result. Most other vision libraries do not do this and lose a lot of detail of the original image when applying several transformations in a row.

The type-dispatch system helps apply appropriate transforms to images, segmentation masks, key-points or bounding boxes (and users can add support for other types by writing their own functions).
Convenience functionality
fastai has a few more additions designed to make Python easier to use, including a NumPy-like API for lists called L, and some decorators to make delegation or patching easier.
Delegation is used when one function will call another and send it a bunch of keyword arguments with defaults. To avoid repeating those, they are often grouped into **kwargs. The problem is that they then disappear from the signature of the function that delegates, and you can’t use the tools from modern IDEs to get tab-completion for those delegated arguments or see them in its signature. To solve this, fastai provides a decorator called @delegates that will analyze the signature of the delegated function to change the signature of the original function. For instance the initialization of Learner has 11 keyword-arguments, so any function that creates a Learner uses this decorator to avoid mentioning them all. As an example, the function tabular_learner is defined like this:
but when you look at its signature, you will see the 11 additional arguments of Learner.__init__ with their defaults.
Monkey-patching is an important functionality of the Python language when you want to add functionality to existing objects. fastai makes it easier and more concise with a @patch decorator, using Python’s type-annotation system. For instance, here is how fastai adds the read() method to the pathlib.Path class:
Lastly, inspired by the NumPy (Oliphant, n.d.) library, fastai provides a collection type, called L, that supports fancy indexing and has a lot of methods that allow users to write simple expressive code. For example, the code below takes a list of pairs, selects the second item of each pair, takes its absolute value, filters items greater than 4, and adds them up:
L uses context-dependent functionality to simplify user code. For instance, the sorted method can take any of the following as a key: a callable (sorts based on the value of calling the key with the item), a string (used as an attribute name), or an int (used as an index).
nbdev
In order to assist in developing this library, we built a programming environment called nbdev, which allows users to create complete Python packages, including tests and a rich documentation system, all in Jupyter Notebooks (Kluyver et al. 2016). nbdev is a system for exploratory programming. Exploratory programming is based on the observation that most developers spend most of their time as coders exploring and experimenting. Exploration is easiest developing on the prompt (or REPL), or using a notebook-oriented development system like Jupyter Notebooks. But these systems are not as strong for the “programming” part, since they’re missing features provided by IDEs and editors like good documentation lookup, good syntax highlighting, integration with unit tests, and (most importantly) the ability to produce final, distributable source code files.
nbdev is built on top of Jupyter Notebook and adds the following critically important tools for software development:
-
Python modules are automatically created, following best practices such as automatically defining
allwith exported functions, classes, and variables - Navigate and edit code in a standard text editor or IDE, and export any changes automatically back into your notebooks
- Automatically create searchable, hyperlinked documentation from your code (as seen in figure [fig:nbdev]; any word surrounded in backticks will by hyperlinked to the appropriate documentation, a sidebar is created in the documentation site with links to each of module, and more
- Pip installers (uploaded to pypi automatically)
- Testing (defined directly in notebooks, and run in parallel)
- Continuous integration
- Version control conflict handling
We plan to provide more information about the features, benefits, and history behind nbdev in a future paper.
Related work
There has been a long history of high-level APIs for deep learning in Python, and this history has been a significant influence on the development of fastai. The first example of a Python library for deep learning that we have found is Calysto/conx, which implemented back propagation in Python in 2001. Since that time there have been dozens of approaches to high level APIs with perhaps the most significant, in chronological order, being Lasagne (Dieleman et al. 2015) (begun in 2013), Fuel/Blocks (begun in 2014), and Keras (Chollet and others 2015) (begun in 2015). There have been other directions as well, such as the configuration-based approach popularized by Caffe (Jia et al. 2014), and lower-level libraries such as Theano (Theano Development Team 2016), TensorFlow (Abadi et al. 2015) and PyTorch (Paszke et al. 2017).
APIs from general machine learning libraries have also been an important influence on fastai. SPSS and SAS provided many utilities for data processing and analysis since the early days of statistical computing. The development of the S language was a very significant advance, which led directly to projects such as R (R Core Team 2017), SPLUS, and xlisp-stat (Luke Tierney 1989). The direction taken by R for both data processing (largely focused on the “Tidyverse” (Wickham et al. 2019)) and model building (built on top of R’s rich “formula” system) shows how a very different set of design choices can result in a very different (and effective) user experience. Scikit-learn (Pedregosa et al. 2011), Torchvision (Massa and Chintala, n.d.), and pandas (McKinney 2010) are examples of libraries which provide a function composition abstraction that (like fastai’s Pipeline) are designed to help users process their data into the format they need (Scikit-Learn also being able to perform learning and predictions on that processed data). There are also projects such as MLxtend (Raschka 2018) that provide a variety of utilities building on the functionality of their underlying programming languages (Python, in the case of MLxtend).
The most important influence on fastai is, of course, PyTorch (Paszke et al. 2017); fastai would not have been possible without it. The PyTorch API is extensible and flexible, and the implementation is efficient. fastai makes heavy use of torch.Tensor and torch.nn (including torch.nn.functional). On the other hand, fastai does not make much use of PyTorch’s higher level APIs, such as nn.optim and annealing, instead independently creating overlapping functionality based on the design approaches and goals described above.
Results and conclusion
Early results from using fastai are very positive. We have used the fastai library to rewrite the entire fast.ai course “Practical Deep Learning for Coders”, which contains 14 hours of material, across seven modules, and covers all the applications described in this paper (and some more). We found that we were able to replicate or improve on all the results in previous versions of the material and were able to create the data pipelines and models needed much more quickly and easily than we could before. We have also heard from early adopters of pre-release versions of the library that they have been able to more quickly and easily write deep learning code and build models than with previous versions. fastai has already been selected as part of the official PyTorch Ecosystem3. According to the 2019 Kaggle ML & DS Survey4, 10% of data scientists in the Kaggle community are already using fastai. Many researchers are using fastai to support their work (e.g. (Revay and Teschke 2019) (Koné and Boulmane 2018) (Elkins, Freitas, and Sanz 2019) (Anand et al. 2019)).
Based on our experience with fastai, we believe that using a layered API in deep learning has very significant benefits for researchers, practitioners, and students. Researchers can see links across different areas more easily, rapidly combine and restructure ideas, and run experiments on top of strong baselines. Practitioners can quickly build prototypes, and then build on and optimize those prototypes by leveraging fastai’s PyTorch foundations, without rewriting code. Students can experiment with models and try out variations, without being overwhelmed by boilerplate code when first learning ideas.
The basic ideas expressed in fastai are not limited to use in PyTorch, or even Python. There is already a partial port of fastai to Swift, called SwiftAI (Jeremy Howard, Sylvain Gugger, and contributors 2019), and we hope to see similar projects for more languages and libraries in the future.
Acknowledgements
We would like to express our deep appreciation to Alexis Gallagher, who was instrumental throughout the paper-writing process, and who inspired the functional-style data blocks API. Many thanks also to Sebastian Raschka for commissioning this paper and acting as the editor for the special edition of Information that it appears in, to the Facebook PyTorch team for all their support throughout fastai’s development, to the global fast.ai community who through forums.fast.ai have contributed many ideas and pull requests that have been invaluable to the development of fastai, to Chris Lattner and the Swift for TensorFlow team who helped develop the Swift courses at course.fast.ai and SwiftAI, to Andrew Shaw for contributing to early prototypes of showdoc in nbdev, to Stas Bekman for contributing to early prototypes of the git hooks in nbdev and to packaging and utilities, and to the developers of the Python programming language, which provides such a strong foundation for fastai’s features.
References
Abadi, Martı́n, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, et al. 2015. “TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems.” https://www.tensorflow.org/.
Anand, Sarthak, Debanjan Mahata, Kartik Aggarwal, Laiba Mehnaz, Simra Shahid, Haimin Zhang, Yaman Kumar, Rajiv Ratn Shah, and Karan Uppal. 2019. “Suggestion Mining from Online Reviews Using Ulmfit.”
Bradski, G. 2000. “The OpenCV Library.” Dr. Dobb’s Journal of Software Tools.
Brébisson, Alexandre de, Étienne Simon, Alex Auvolat, Pascal Vincent, and Yoshua Bengio. 2015. “Artificial Neural Networks Applied to Taxi Destination Prediction.” CoRR abs/1508.00021. http://arxiv.org/abs/1508.00021.
Brostow, Gabriel J., Jamie Shotton, Julien Fauqueur, and Roberto Cipolla. 2008. “Segmentation and Recognition Using Structure from Motion Point Clouds.” In ECCV (1), 44–57.
Chollet, François. 2016. “Xception: Deep Learning with Depthwise Separable Convolutions.” CoRR abs/1610.02357. http://arxiv.org/abs/1610.02357.
Chollet, François, and others. 2015. “Keras.” https://keras.io.
Clark, Alex, and Contributors. n.d. “Python Imaging Library (Pillow Fork).” https://github.com/python-pillow/Pillow.
Cody A. Coleman, Daniel Kang, Deepak Narayanan, and Matei Zahari. 2017. “DAWNBench: An End-to-End Deep Learning Benchmark and Competition.” NIPS ML Systems Workshop, 2017.
Deng, J., W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. 2009. “ImageNet: A Large-Scale Hierarchical Image Database.” In CVPR09.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” CoRR abs/1810.04805. http://arxiv.org/abs/1810.04805.
Dieleman, Sander, Jan Schlüter, Colin Raffel, Eben Olson, Søren Kaae Sønderby, Daniel Nouri, Daniel Maturana, et al. 2015. “Lasagne: First Release.” https://doi.org/10.5281/zenodo.27878.
Eisenschlos, Julian, Sebastian Ruder, Piotr Czapla, Marcin Kadras, Sylvain Gugger, and Jeremy Howard. 2019. “MultiFiT: Efficient Multi-Lingual Language Model Fine-Tuning.” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). https://doi.org/10.18653/v1/d19-1572.
Elkins, Andrew, Felipe F. Freitas, and Veronica Sanz. 2019. “Developing an App to Interpret Chest X-Rays to Support the Diagnosis of Respiratory Pathology with Artificial Intelligence.”
Girshick, Ross, Ilija Radosavovic, Georgia Gkioxari, Piotr Dollár, and Kaiming He. 2018. “Detectron.” https://github.com/facebookresearch/detectron.
Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. “Generative Adversarial Nets.” In Advances in Neural Information Processing Systems 27, edited by Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, 2672–80. Curran Associates, Inc. http://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf.
Guo, Cheng, and Felix Berkhahn. 2016. “Entity Embeddings of Categorical Variables.” CoRR abs/1604.06737. http://arxiv.org/abs/1604.06737.
Harper, F. Maxwell, and Joseph A. Konstan. 2015. “The Movielens Datasets: History and Context.” ACM Trans. Interact. Intell. Syst. 5 (4): 19:1–19:19. https://doi.org/10.1145/2827872.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. “Deep Residual Learning for Image Recognition.” CoRR abs/1512.03385. http://arxiv.org/abs/1512.03385.
He, Tong, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. 2018. “Bag of Tricks for Image Classification with Convolutional Neural Networks.” CoRR abs/1812.01187. http://arxiv.org/abs/1812.01187.
Howard, Jeremy, and Sylvain Gugger. 2020. Deep Learning for Coders with Fastai and Pytorch: AI Applications Without a Phd. 1st ed. O’Reilly Media, Inc.
Howard, Jeremy, and Sebastian Ruder. 2018. “Fine-Tuned Language Models for Text Classification.” CoRR abs/1801.06146. http://arxiv.org/abs/1801.06146.
Hu, Jie, Li Shen, and Gang Sun. 2017. “Squeeze-and-Excitation Networks.” CoRR abs/1709.01507. http://arxiv.org/abs/1709.01507.
Huang, Gao, Zhuang Liu, and Kilian Q. Weinberger. 2016. “Densely Connected Convolutional Networks.” CoRR abs/1608.06993. http://arxiv.org/abs/1608.06993.
Hunter, John D. 2007. “Matplotlib: A 2D Graphics Environment.” Computing in Science & Engineering 9 (3): 90.
Ioffe, Sergey, and Christian Szegedy. 2015. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.” CoRR abs/1502.03167. http://arxiv.org/abs/1502.03167.
Jeremy Howard, Sylvain Gugger, and contributors. 2019. SwiftAI. fast.ai, Inc. https://github.com/fastai/swiftai.
Jia, Yangqing, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. 2014. “Caffe: Convolutional Architecture for Fast Feature Embedding.” arXiv Preprint arXiv:1408.5093.
Kluyver, Thomas, Benjamin Ragan-Kelley, Fernando Pérez, Brian Granger, Matthias Bussonnier, Jonathan Frederic, Kyle Kelley, et al. 2016. “Jupyter Notebooks – a Publishing Format for Reproducible Computational Workflows.” Edited by F. Loizides and B. Schmidt. IOS Press.
Koné, Ismaël, and Lahsen Boulmane. 2018. “Hierarchical Resnext Models for Breast Cancer Histology Image Classification.” CoRR abs/1810.09025. http://arxiv.org/abs/1810.09025.
Kudo, Taku. 2018. “Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates.” CoRR abs/1804.10959. http://arxiv.org/abs/1804.10959.
Kudo, Taku, and John Richardson. 2018. “SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing.” CoRR abs/1808.06226. http://arxiv.org/abs/1808.06226.
LeCun, Yann, Corinna Cortes, and CJ Burges. 2010. “MNIST Handwritten Digit Database.” AT&T Labs [Online]. Available: Http://Yann. Lecun. Com/Exdb/Mnist 2: 18.
Lin, Tsung-Yi, Michael Maire, Serge J. Belongie, Lubomir D. Bourdev, Ross B. Girshick, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. “Microsoft COCO: Common Objects in Context.” CoRR abs/1405.0312. http://arxiv.org/abs/1405.0312.
Loshchilov, Ilya, and Frank Hutter. 2017. “Fixing Weight Decay Regularization in Adam.” CoRR abs/1711.05101. http://arxiv.org/abs/1711.05101.
Luke Tierney. 1989. “XLISP-STAT: A Statistical Environment Based on the XLISP Language (Version 2.0).” 28. School of Statistics, University of Minnesota.
Maas, Andrew L., Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. “Learning Word Vectors for Sentiment Analysis.” In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, 142–50. Portland, Oregon, USA: Association for Computational Linguistics. http://www.aclweb.org/anthology/P11-1015.
Massa, Francisco, and Soumith Chintala. n.d. “Torchvision.” https://github.com/pytorch/vision/tree/master/torchvision.
McKinney, Wes. 2010. “Data Structures for Statistical Computing in Python.” In Proceedings of the 9th Python in Science Conference, edited by Stéfan van der Walt and Jarrod Millman, 51–56.
Merity, Stephen, Nitish Shirish Keskar, and Richard Socher. 2017. “Regularizing and Optimizing LSTM Language Models.” CoRR abs/1708.02182. http://arxiv.org/abs/1708.02182.
Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, et al. 2017. “Mixed Precision Training.” http://arxiv.org/abs/1710.03740.
Misra, Diganta. 2019. “Mish: A Self Regularized Non-Monotonic Neural Activation Function.” http://arxiv.org/abs/1908.08681.
Mnih, Andriy, and Ruslan R Salakhutdinov. 2008. “Probabilistic Matrix Factorization.” In Advances in Neural Information Processing Systems, 1257–64.
Oliphant, Travis. n.d. “NumPy: A Guide to NumPy.” USA: Trelgol Publishing. http://www.numpy.org/.
Ott, Myle, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. 2019. “Fairseq: A Fast, Extensible Toolkit for Sequence Modeling.” In Proceedings of Naacl-Hlt 2019: Demonstrations.
Parkhi, Omkar M., Andrea Vedaldi, Andrew Zisserman, and C. V. Jawahar. 2012. “Cats and Dogs.” In IEEE Conference on Computer Vision and Pattern Recognition.
Paszke, Adam, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. 2017. “Automatic Differentiation in PyTorch.” In NIPS Autodiff Workshop.
Pedregosa, F., G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, et al. 2011. “Scikit-learn: Machine Learning in Python.” Journal of Machine Learning Research 12: 2825–30.
Python Core Team. 2019. Python: A dynamic, open source programming language. Python Software Foundation. https://www.python.org/.
Radford, Alec, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. “Language Models Are Unsupervised Multitask Learners.”
Raschka, Sebastian. 2018. “MLxtend: Providing Machine Learning and Data Science Utilities and Extensions to Python’s Scientific Computing Stack.” The Journal of Open Source Software 3 (24). https://doi.org/10.21105/joss.00638.
R Core Team. 2017. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
Revay, Shauna, and Matthew Teschke. 2019. “Multiclass Language Identification Using Deep Learning on Spectral Images of Audio Signals.”
Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. 2015. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” CoRR abs/1505.04597. http://arxiv.org/abs/1505.04597.
Smith, Leslie N. 2015. “No More Pesky Learning Rate Guessing Games.” CoRR abs/1506.01186. http://arxiv.org/abs/1506.01186.
Smith, Leslie N. 2018. “A Disciplined Approach to Neural Network Hyper-Parameters: Part 1 - Learning Rate, Batch Size, Momentum, and Weight Decay.” CoRR abs/1803.09820. http://arxiv.org/abs/1803.09820.
Theano Development Team. 2016. “Theano: A Python framework for fast computation of mathematical expressions.” arXiv E-Prints abs/1605.02688 (May). http://arxiv.org/abs/1605.02688.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019. “Welcome to the tidyverse.” Journal of Open Source Software 4 (43): 1686. https://doi.org/10.21105/joss.01686.
Wolf, Thomas, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, et al. 2019. “HuggingFace’s Transformers: State-of-the-Art Natural Language Processing.” ArXiv abs/1910.03771.
Wu, Yonghui, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, et al. 2016. “Google’s Neural Machine Translation System: Bridging the Gap Between Human and Machine Translation.” CoRR abs/1609.08144. http://arxiv.org/abs/1609.08144.
Xie, Saining, Ross Girshick, Piotr Dollar, Zhuowen Tu, and Kaiming He. 2017. “Aggregated Residual Transformations for Deep Neural Networks.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July. https://doi.org/10.1109/cvpr.2017.634.
You, Yang, Jing Li, Jonathan Hseu, Xiaodan Song, James Demmel, and Cho-Jui Hsieh. 2019. “Reducing BERT Pre-Training Time from 3 Days to 76 Minutes.” CoRR abs/1904.00962. http://arxiv.org/abs/1904.00962.
Zagoruyko, Sergey, and Nikos Komodakis. 2016. “Wide Residual Networks.” CoRR abs/1605.07146. http://arxiv.org/abs/1605.07146.
Zhang, Hongyi, Moustapha Cissé, Yann N. Dauphin, and David Lopez-Paz. 2017. “Mixup: Beyond Empirical Risk Minimization.” CoRR abs/1710.09412. http://arxiv.org/abs/1710.09412.