fast.ai is a self-funded research, software development, and teaching lab, focused on making deep learning more accessible. We make all of our software, research papers, and courses freely available with no ads. We pay all of our costs out of our own pockets, and take no grants or donations, so you can be sure we’re truly independent.
Today is fast.ai’s biggest day in our four year history. We are releasing:
- fastai v2: A complete rewrite of fastai which is faster, easier, and more flexible, implementing new approaches to deep learning framework design, as discussed in the peer reviewed fastai academic paper
- fastcore fastgpu: Foundational libraries used in fastai v2, and useful for many programmers and data scientists
- Practical Deep Learning for Coders (2020 course, part 1): Incorporating both an introduction to machine learning, and deep learning, and production and deployment of data products
- Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD: A book from O’Reilly, which covers the same material as the course (including the content planned for part 2 of the course)
Also, in case you missed it, earlier this week we released the Practical Data Ethics course, which focuses on topics that are both urgent and practical.
fastai v2
fastai is a deep learning library which provides practitioners with high-level components that can quickly and easily provide state-of-the-art results in standard deep learning domains, and provides researchers with low-level components that can be mixed and matched to build new approaches. It aims to do both things without substantial compromises in ease of use, flexibility, or performance. This is possible thanks to a carefully layered architecture, which expresses common underlying patterns of many deep learning and data processing techniques in terms of decoupled abstractions. These abstractions can be expressed concisely and clearly by leveraging the dynamism of the underlying Python language and the flexibility of the PyTorch library. fastai includes:
- A new type dispatch system for Python along with a semantic type hierarchy for tensors
- A GPU-optimized computer vision library which can be extended in pure Python
- An optimizer which refactors out the common functionality of modern optimizers into two basic pieces, allowing optimization algorithms to be implemented in 45 lines of code
- A novel 2-way callback system that can access any part of the data, model, or optimizer and change it at any point during training
- A new data block API
- And much more…
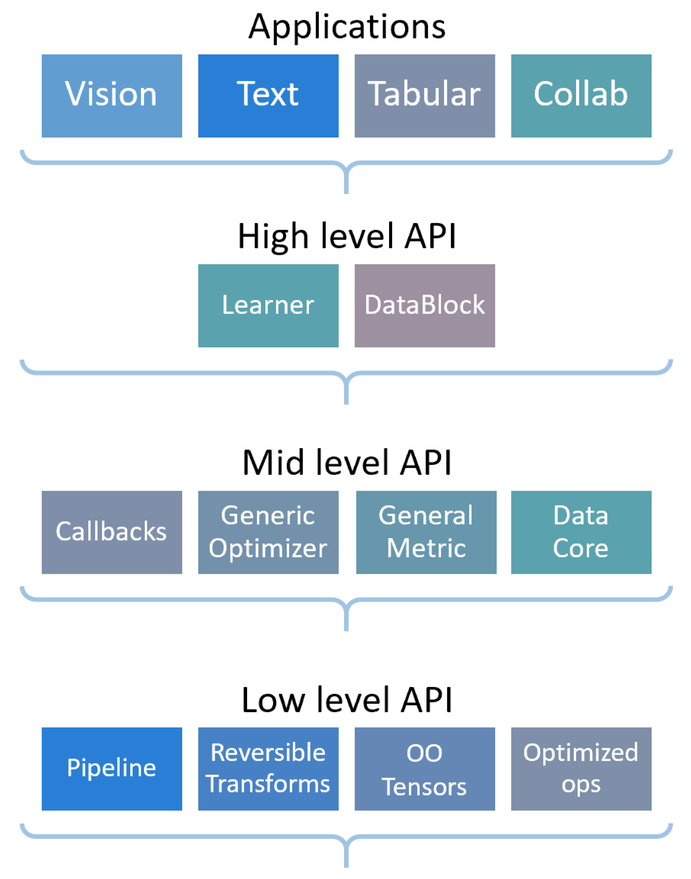
fastai is organized around two main design goals: to be approachable and rapidly productive, while also being deeply hackable and configurable. It is built on top of a hierarchy of lower-level APIs which provide composable building blocks. This way, a user wanting to rewrite part of the high-level API or add particular behavior to suit their needs does not have to learn how to use the lowest level.
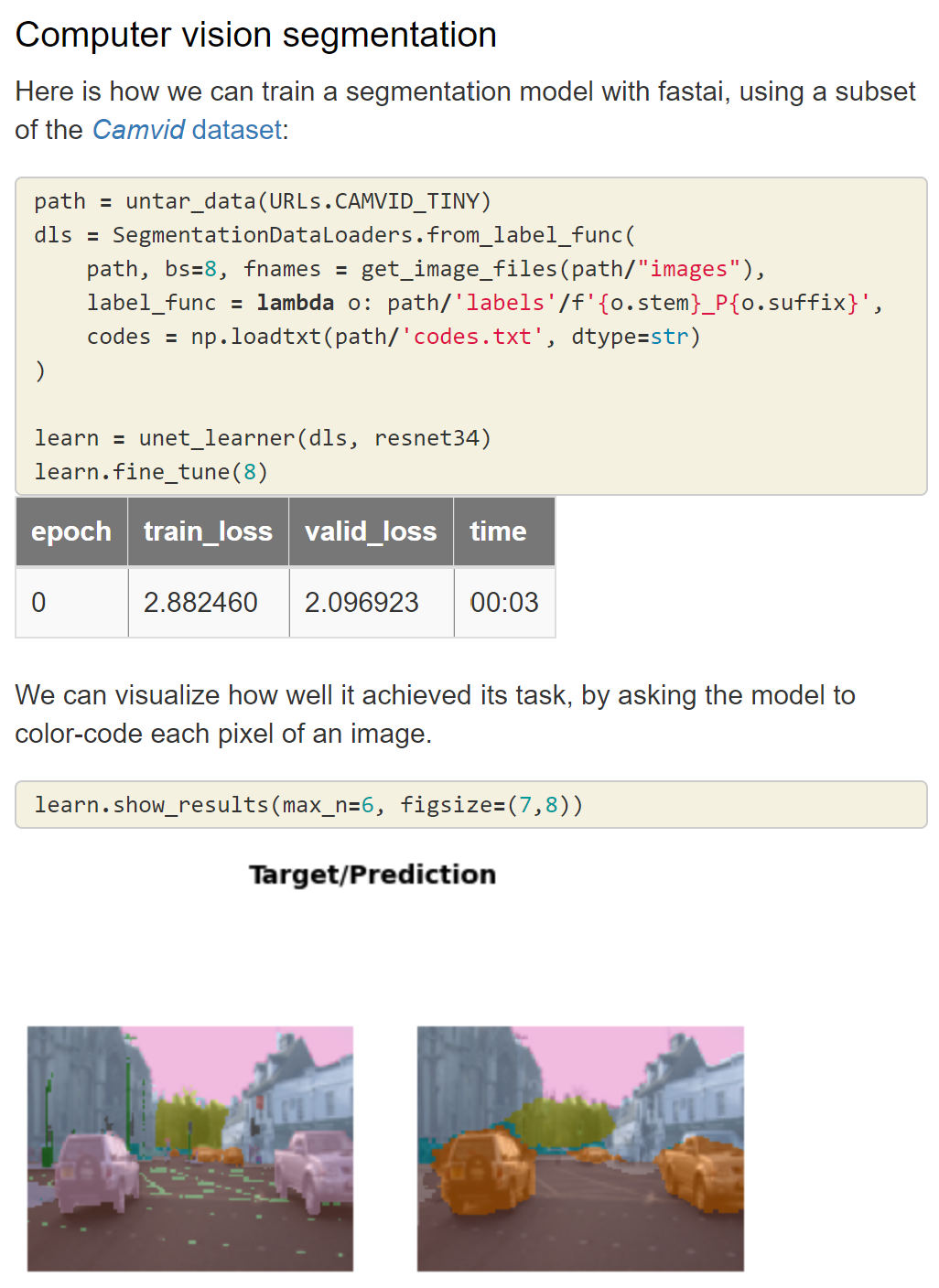
To see what’s possible with fastai, take a look at the Quick Start, which shows how to use around 5 lines of code to build an image classifier, an image segmentation model, a text sentiment model, a recommendation system, and a tabular model. For each of the applications, the code is much the same.
Read through the Tutorials to learn how to train your own models on your own datasets. Use the navigation sidebar to look through the fastai documentation. Every class, function, and method is documented here. To learn about the design and motivation of the library, read the peer reviewed paper, or watch this presentation summarizing some of the key design points.
All fast.ai projects, including fastai, are built with nbdev, which is a full literate programming environment built on Jupyter Notebooks. That means that every piece of documentation can be accessed as interactive Jupyter notebooks, and every documentation page includes a link to open it directly on Google Colab to allow for experimentation and customization.
It’s very easy to migrate from plain PyTorch, Ignite, or any other PyTorch-based library, or even to use fastai in conjunction with other libraries. Generally, you’ll be able to use all your existing data processing code, but will be able to reduce the amount of code you require for training, and more easily take advantage of modern best practices. Here are migration guides from some popular libraries to help you on your way: Plain PyTorch; Ignite; Lightning; Catalyst. And because it’s easy to combine and part of the fastai framework with your existing code and libraries, you can just pick the bits you want. For instance, you could use fastai’s GPU-accelerated computer vision library, along with your own training loop.
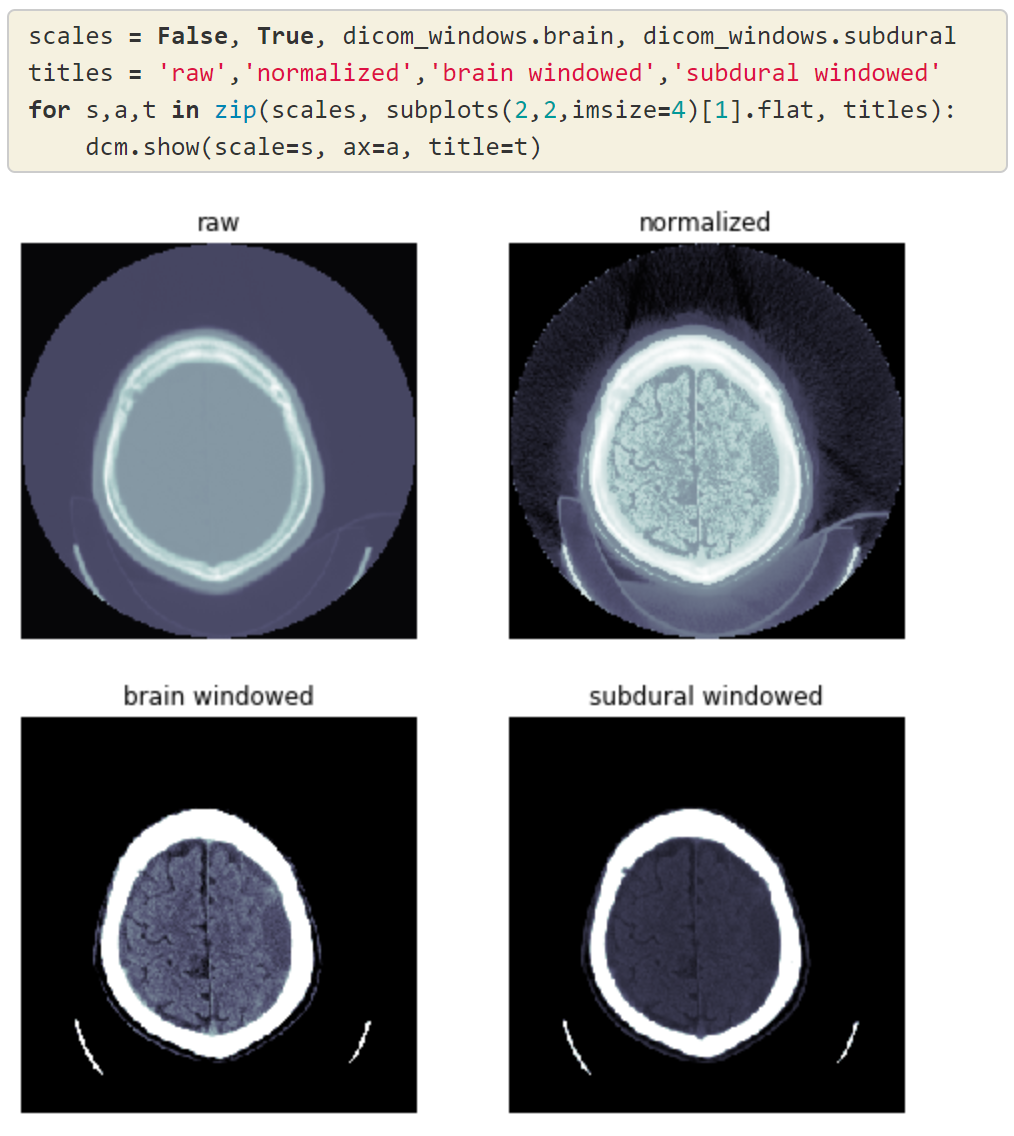
fastai includes many modules that add functionality, generally through callbacks. Thanks to the flexible infrastructure, these all work together, so you can pick and choose what you need (and add your own), including: mixup and cutout augmentation, a uniquely flexible GAN training framework, a range of schedulers (many of which aren’t available in any other framework) including support for fine tuning following the approach described in ULMFiT, mixed precision, gradient accumulation, support for a range of logging frameworks like Tensorboard (with particularly strong support for Weights and Biases, as demonstrated here), medical imaging, and much more. Other functionality is added through the fastai ecosystem, such as support for HuggingFace Transformers (which can also be done manually, as shown in this tutorial), audio, accelerated inference, and so forth.
There’s already some great learning material made available for fastai v2 by the community, such as the “Zero to Hero” series by Zach Mueller: part 1; part 2.
Practical Deep Learning for Coders, the course
Previous fast.ai courses have been studied by hundreds of thousands of students, from all walks of life, from all parts of the world. Many students have told us about how they’ve become multiple gold medal winners of international machine learning competitions, received offers from top companies, and having research papers published. For instance, Isaac Dimitrovsky told us that he had “been playing around with ML for a couple of years without really grokking it… [then] went through the fast.ai part 1 course late last year, and it clicked for me”. He went on to achieve first place in the prestigious international RA2-DREAM Challenge competition! He developed a multistage deep learning method for scoring radiographic hand and foot joint damage in rheumatoid arthritis, taking advantage of the fastai library.
This year’s course takes things even further. It incorporates both machine learning and deep learning in a single course, covering topics like random forests, gradient boosting, test and validation sets, and p values, which previously were in a separate machine learning course. In addition, production and deployment are also covered, including material on developing a web-based GUI for our own deep learning powered apps. The only prerequisite is high-school math, and a year of coding experience (preferably in Python). The course was recorded live, in conjunction with the Data Institute at the University of San Francisco.
After finishing this course you will know:
- How to train models that achieve state-of-the-art results in:
- Computer vision, including image classification (e.g.,classifying pet photos by breed), and image localization and detection (e.g.,finding where the animals in an image are)
- Natural language processing (NLP), including document classification (e.g.,movie review sentiment analysis) and language modeling
- Tabular data (e.g.,sales prediction) with categorical data, continuous data, and mixed data, including time series
- Collaborative filtering (e.g.,movie recommendation)
- How to turn your models into web applications, and deploy them
- Why and how deep learning models work, and how to use that knowledge to improve the accuracy, speed, and reliability of your models
- The latest deep learning techniques that really matter in practice
- How to implement stochastic gradient descent and a complete training loop from scratch
- How to think about the ethical implications of your work, to help ensure that you’re making the world a better place and that your work isn’t misused for harm
We care a lot about teaching, using a whole game approach. In this course, we start by showing how to use a complete, working, very usable, state-of-the-art deep learning network to solve real-world problems, using simple, expressive tools. And then we gradually dig deeper and deeper into understanding how those tools are made, and how the tools that make those tools are made, and so on. We always teach through examples. We ensure that there is a context and a purpose that you can understand intuitively, rather than starting with algebraic symbol manipulation. We also dive right into the details, showing you how to build all the components of a deep learning model from scratch, including discussing performance and optimization details.
The whole course can be completed for free without any installation, by taking advantage of the guides for the Colab and Gradient platforms, which provide free, GPU-powered Notebooks.
Deep Learning for Coders with fastai and PyTorch, the book
To understand what the new book is about, and who it’s for, let’s see what others have said about it… Soumith Chintala, the co-creator of PyTorch, said in the foreword to Deep Learning for Coders with fastai and PyTorch:
But unlike me, Jeremy and Sylvain selflessly put a huge amount of energy into making sure others don’t have to take the painful path that they took. They built a great course called fast.ai that makes cutting-edge deep learning techniques accessible to people who know basic programming. It has graduated hundreds of thousands of eager learners who have become great practitioners.
In this book, which is another tireless product, Jeremy and Sylvain have constructed a magical journey through deep learning. They use simple words and introduce every concept. They bring cutting-edge deep learning and state-of-the-art research to you, yet make it very accessible.
You are taken through the latest advances in computer vision, dive into natural language processing, and learn some foundational math in a 500-page delightful ride. And the ride doesn’t stop at fun, as they take you through shipping your ideas to production. You can treat the fast.ai community, thousands of practitioners online, as your extended family, where individuals like you are available to talk and ideate small and big solutions, whatever the problem may be.
Peter Norvig, Director of Research at Google (and author of the definitive text on AI) said:
“Deep Learning is for everyone” we see in Chapter 1, Section 1 of this book, and while other books may make similar claims, this book delivers on the claim. The authors have extensive knowledge of the field but are able to describe it in a way that is perfectly suited for a reader with experience in programming but not in machine learning. The book shows examples first, and only covers theory in the context of concrete examples. For most people, this is the best way to learn.The book does an impressive job of covering the key applications of deep learning in computer vision, natural language processing, and tabular data processing, but also covers key topics like data ethics that some other books miss. Altogether, this is one of the best sources for a programmer to become proficient in deep learning.
Curtis Langlotz, Director, Center for Artificial Intelligence in Medicine and Imaging at Stanford University said:
Gugger and Howard have created an ideal resource for anyone who has ever done even a little bit of coding. This book, and the fast.ai courses that go with it, simply and practically demystify deep learning using a hands on approach, with pre-written code that you can explore and re-use. No more slogging through theorems and proofs about abstract concepts. In Chapter 1 you will build your first deep learning model, and by the end of the book you will know how to read and understand the Methods section of any deep learning paper.
fastcore and fastgpu
fastcore
Python is a powerful, dynamic language. Rather than bake everything into the language, it lets the programmer customize it to make it work for them. fastcore uses this flexibility to add to Python features inspired by other languages we’ve loved, like multiple dispatch from Julia, mixins from Ruby, and currying, binding, and more from Haskell. It also adds some “missing features” and cleans up some rough edges in the Python standard library, such as simplifying parallel processing, and bringing ideas from NumPy over to Python’s list type.
fastcore contains many features. See the docs for all the details, which cover the modules provided:
test: Simple testing functionsfoundation: Mixins, delegation, composition, and moreutils: Utility functions to help with functional-style programming, parallel processing, and moredispatch: Multiple dispatch methodstransform: Pipelines of composed partially reversible transformations
fastgpu
fastgpu provides a single command, fastgpu_poll, which polls a directory to check for scripts to run, and then runs them on the first available GPU. If no GPUs are available, it waits until one is. If more than one GPU is available, multiple scripts are run in parallel, one per GPU. It is the easiest way we’ve found to run ablation studies that take advantage of all of your GPUs, result in no parallel processing overhead, and require no manual intervention.
Acknowledgements
Many thanks to everyone who helped bring these projects to fruition, most especially to Sylvain Gugger, who worked closely with me over the last two years at fast.ai. Thanks also to all the support from the Data Institute at the University of San Francisco, and to Rachel Thomas, co-founder of fast.ai, who (amongst other things) taught the data ethics lesson and developed much of the data ethics material in the book. Thank you to everyone from the fast.ai community for all your wonderful contributions.