graph TB
subgraph "GPT-2 Architecture"
A[Raw Text: 'Hello world'] --> B[Tokenizer]
B --> C[Token Sequence: 15496, 995]
C --> D[Embedding Table<br/>50,257 rows × n_embed cols]
D --> E[Token Vectors]
E --> F[Transformer Attention Layer<br/>Context Window: 1,024 tokens]
F --> G[Each token attends to<br/>previous tokens in sequence]
G --> H[Output: Next Token Prediction]
end
style B fill:#e1f5ff
style D fill:#fff4e1
style F fill:#ffe1f5
note1[Vocabulary Size: 50,257 tokens]
note2[Context Size: 1,024 tokens]
note3[Tokens are the fundamental<br/>unit of LLMs]
B -.-> note1
F -.-> note2
C -.-> note3
18 months ago, Andrej Karpathy set a challenge: “Can you take my 2h13m tokenizer video and translate the video into the format of a book chapter”. We’ve done it, and the chapter is below, including key pieces of code inlined, and images from the video at key points (hyperlinked to the video timestamp). It’s a great video for learning this key piece of how LLMs work, and this new text version is great too.
To create it, we used the Solveit platform & approach. I.e: this isn’t auto-generated AI slop; it’s made by a human deeply engaged in the lesson, with AI help. So it was 10x faster than doing it manually, but the result is similar to a fully manual approach. We’ll post a full walk-through of how we did it next week. (We’ve written the chapter from the point of view of Andrej, but any omissions or errors are likely to be our fault! We have checked it carefully, but we might miss things.)
Introduction: Why Tokenization Matters
This tutorial covers the process of tokenization in large language models. Tokenization is one of the less enjoyable aspects of working with large language models, but it’s necessary to understand in detail. The process is complex, with many hidden pitfalls to be aware of. Much of the odd behavior in large language models can be traced back to tokenization.
Tokenization was covered in my earlier guide, Let’s build GPT from scratch, but using a naive, simple version. The accompanying notebook demonstrates loading the Shakespeare dataset as a training set. This dataset is simply a large Python string containing text. The core question becomes: how do we feed text into large language models?
In that simple example, we created a vocabulary of 65 possible characters that appeared in the string. These characters formed our vocabulary, with a lookup table converting each character (a small string piece) into a token (an integer). Tokenizing the string “hi there” produced a sequence of tokens. The first 1,000 characters of the dataset encoded into tokens. Since this was character-level tokenization, it produced exactly 1,000 tokens in sequence.
The character-level approach from that earlier guide worked as follows:
import torch
text = 'This is some text dataset hello, and hi some words!'
# get the unique characters that occur in this text
chars = sorted(list(set(text)))
vocab_size = len(chars)
print(''.join(chars))
print(vocab_size)Then we created a mapping from characters to integers:
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
print(encode("hii there"))
print(decode(encode("hii there")))Finally we encoded the entire text dataset and stored it into a torch.Tensor:
data = torch.tensor(encode(text), dtype=torch.long)
print(data.shape, data.dtype)
print(data[:1000]) # the first 1000 characters we'll look like thisTokenization is at the heart of many peculiar behaviors in large language models. Before diving into the technical details, it’s worth understanding why this seemingly mundane topic deserves careful attention.
Tokenization Issues in LLMs - Why you should care:
- Why can’t LLM spell words? Tokenization.
- Why can’t LLM do string processing tasks like reversing a string? Tokenization.
- Why is LLM bad at non-English languages? Tokenization.
- Why is LLM bad at simple arithmetic? Tokenization.
- Why did GPT-2 have more than necessary trouble coding in Python? Tokenization.
- Why did my LLM abruptly halt when it sees the string “<|endoftext|>”? Tokenization.
- Why should I prefer YAML over JSON with LLMs? Tokenization.
- What is the root of suffering? Tokenization.
We’ll return to these issues at the end, but first, consider the tiktokenizer web app. This tool runs tokenization live in your browser using JavaScript, allowing you to see the tokenization process in real-time as you type.
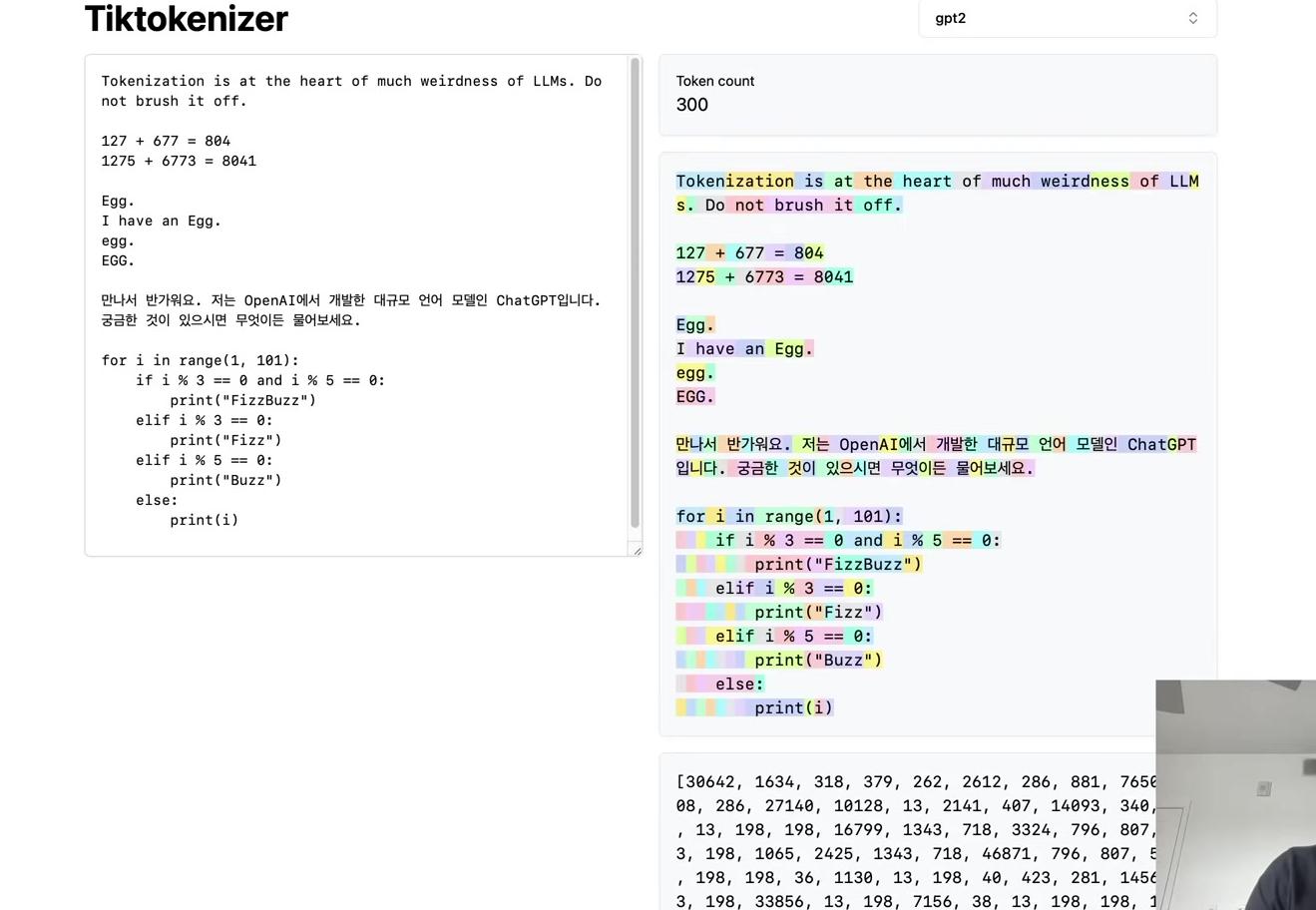
The left pane displays the input string, while the right pane shows the tokenization result using the GPT-2 tokenizer. The sample text tokenizes into 300 tokens, each shown in a different color. For instance, the word “Tokenization” splits into two tokens: token 30,642 and 1,634. The token ” is” becomes token 318. Note that the interface can show or hide whitespace characters for clarity, and spaces are often included as part of token chunks. The token ” at” is 379, and ” the” is 262.
The arithmetic examples reveal interesting patterns. The number 127 becomes a single token (token 127), followed by ” plus” and then ” 6” (token 77). However, the number 677 splits into two separate tokens. The large language model must account for this variability when processing numerical inputs through its network. Similarly, 804 splits into two tokens. This fragmentation is largely arbitrary: sometimes multiple digits form a single token, sometimes individual digits become separate tokens, depending on what the tokenizer learned during training.
The naive character-level tokenization from our earlier example isn’t sufficient for real LLMs. State-of-the-art language models use more sophisticated schemes for constructing token vocabularies. Rather than operating at the character level, these models work with character chunks constructed using algorithms such as byte-pair encoding, which we’ll explore in detail throughout this tutorial.
From Characters to Tokens: The Basics
Simple Character-Level Tokenization
The process of integrating these tokens into the language model relies on an embedding table. With 65 possible tokens, the embedding table contains 65 rows. Each token’s integer value serves as a lookup key into this table, retrieving the corresponding row. This row consists of trainable parameters that are optimized through backpropagation. The resulting vector feeds into the transformer, which is how the transformer perceives each token.
The character-level approach described earlier represents a naive tokenization process. State-of-the-art language models employ more sophisticated schemes for constructing token vocabularies. Instead of operating at the character level, these models work with character chunks constructed using algorithms such as byte-pair encoding, which this tutorial will explore in detail.
The GPT-2 paper introduced byte-pair encoding as a mechanism for tokenization in large language models. The “Input Representation” section discusses the properties desired in tokenization. The authors settled on a vocabulary of 50,257 possible tokens with a context size of 1,024 tokens. In the transformer’s attention layer, each token attends to the previous tokens in the sequence, examining up to 1,024 tokens. Tokens serve as the fundamental unit—the atom—of large language models. Everything operates in units of tokens. Tokenization is the process for translating text into sequences of tokens and vice versa.
The Llama 2 paper contains 63 mentions of “token,” highlighting the term’s ubiquity. The paper notes training on 2 trillion tokens of data. This tutorial will build a tokenizer from scratch. Fortunately, the byte-pair encoding algorithm is relatively straightforward and can be implemented without excessive complexity.
Before diving into code, it’s worth examining some of the complexities that arise from tokenization to understand why this topic deserves careful attention. Tokenization lies at the heart of many unexpected behaviors in large language models. Many issues that appear to stem from the neural architecture or the language model itself actually trace back to tokenization.
Large language models struggle with spelling tasks—this is typically due to tokenization. Simple string processing can be difficult for language models to perform natively. Non-English languages often work much worse, largely due to tokenization. Language models sometimes struggle with simple arithmetic, which can also be traced to tokenization. GPT-2 specifically had more difficulty with Python than later versions due to tokenization. Other issues include strange warnings about trailing whitespace—a tokenization issue. Earlier versions of GPT would behave erratically when asked about “SolidGoldMagikarp,” going off on completely unrelated tangents. The recommendation to use YAML over JSON with structured data relates to tokenization. Tokenization underlies many of these problems.
The Unicode and UTF-8 Foundation
The goal is to take strings and feed them into language models. This requires tokenizing strings into integers from a fixed vocabulary. These integers then serve as lookups into a table of vectors that feed into the transformer as input.
The challenge extends beyond supporting the simple English alphabet. Language models need to handle different languages, such as “annyeonghaseyo” (안녕하세요) in Korean, which means hello. They also need to support special characters found on the internet, including emoji. How can transformers process this text?
text = "안녕하세요 👋 hello world 🤗"
print(text)Python documentation defines strings as immutable sequences of Unicode code points. Unicode code points are defined by the Unicode Consortium as part of the Unicode standard. The standard defines roughly 150,000 characters across 161 scripts, specifying what these characters look like and what integers represent them. The standard continues to evolve—version 15.1 was released in September 2023.
Unicode, formally The Unicode Standard, is a text encoding standard maintained by the Unicode Consortium designed to support the use of text written in all of the world’s major writing systems. Version 15.1 of the standard defines 149,813 characters and 161 scripts used in various ordinary, literary, academic, and technical contexts.
The Unicode Wikipedia page provides comprehensive documentation of this standard, covering characters across different scripts.
Python’s ord function retrieves the Unicode code point for a single character. For example, the character ‘h’ has a Unicode code point of 104. This extends to arbitrarily complex characters: the hugging face emoji has a code point of 128,000, while the Korean character “안” has a code point of 50,000. The ord function only accepts single Unicode code point characters, not strings.
# Get Unicode code point for English character
print(f"ord('h') = {ord('h')}")
# Get Unicode code point for emoji
print(f"ord('🤗') = {ord('🤗')}")
# Get Unicode code point for Korean character
print(f"ord('안') = {ord('안')}")We can retrieve the code points for all characters in a string:
# Get Unicode code points for each character in the string
text = "안녕하세요 👋 hello world 🤗"
L([ord(x) for x in text])Given that raw code points already provide integers, why not use these directly as tokens without any additional tokenization?
One reason is vocabulary size. The Unicode vocabulary contains approximately 150,000 different code points. More concerning, the Unicode standard continues to evolve and change, making it potentially unstable as a direct representation for language models. These factors necessitate a better approach.
The solution lies in encodings. The Unicode Consortium defines three types of encodings: UTF-8, UTF-16, and UTF-32. These encodings translate Unicode text into binary data or byte strings. UTF-8 is by far the most common. The UTF-8 Wikipedia page explains that UTF-8 takes each code point and translates it to a byte string of variable length—between one to four bytes. Each code point produces between one to four bytes according to the encoding schema.
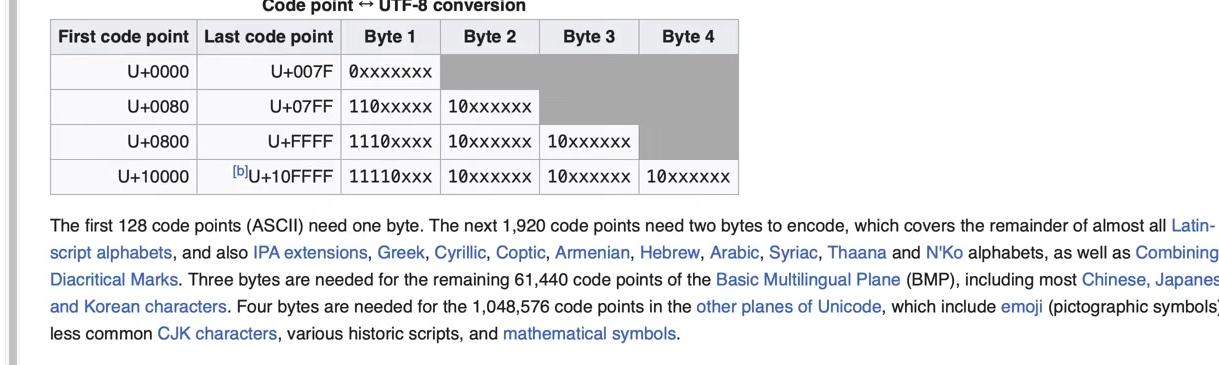
Among the three encodings, UTF-32 offers the advantage of fixed-length encoding rather than variable-length, but it comes with significant downsides. The full spectrum of trade-offs among these encodings extends beyond our scope here. For those interested in a deeper dive, this blog post provides valuable context, along with references including the “UTF-8 Everywhere Manifesto.” The manifesto explains why UTF-8 is significantly preferred over other encodings and why it dominates internet usage. One major advantage is that UTF-8 remains backward compatible with the simpler ASCII encoding of text, unlike the alternatives.
For our purposes, UTF-8 is the clear choice. We can examine what happens when encoding a string into UTF-8. Python’s string class provides an .encode() method that accepts an encoding parameter. Converting the bytes object to a list makes the raw bytes more readable, revealing the byte sequence that represents the string according to UTF-8 encoding.
text = "안녕하세요 👋 hello world 🤗"
# UTF-8 encoding
utf8_bytes = list(text.encode('utf-8'))
print(f"UTF-8: {utf8_bytes}")
# UTF-16 encoding
utf16_bytes = list(text.encode('utf-16'))
print(f"UTF-16: {utf16_bytes}")
# UTF-32 encoding
utf32_bytes = list(text.encode('utf-32'))
print(f"UTF-32: {utf32_bytes}")Comparing UTF-16 reveals one of its disadvantages. The pattern of repeated zeros (zero, zero something, zero something, zero something) demonstrates wasteful encoding. For simple ASCII or English characters, the structure consistently shows zero-something patterns. UTF-32 displays even more waste when expanded, with long sequences of zeros followed by single values. This inefficiency makes both alternatives undesirable for our purposes.
While UTF-8 is the preferred choice, using it naively presents a challenge. The byte streams imply a vocabulary of only 256 possible tokens. This vocabulary size is extremely small, resulting in text stretched across very long sequences of bytes.
A naive approach would create a tiny embedding table and a small prediction layer at the final stage, but at the cost of extremely long sequences. Transformers support only finite context length in their attention mechanism for computational reasons. Long sequences consume this limited context window inefficiently, preventing the model from attending to sufficiently long text for effective next-token prediction.
The solution requires supporting a larger, tunable vocabulary size while maintaining UTF-8 encoding compatibility. How can we achieve this balance?
The Byte Pair Encoding (BPE) Algorithm
Understanding BPE Fundamentals
The Byte Pair Encoding algorithm provides the answer, allowing us to compress byte sequences to a variable amount. Before exploring BPE in detail, it’s worth noting that feeding raw byte sequences directly into language models would be ideal. A paper from summer 2023 explores this possibility.
The challenge is that the transformer architecture requires modification to handle raw bytes. As mentioned earlier, attention becomes extremely expensive with such long sequences. The paper proposes a hierarchical structuring of the transformer that could accept raw bytes as input. The authors conclude: “Together, these results establish the viability of tokenization-free autoregressive sequence modeling at scale.” Tokenization-free modeling would be a significant advancement, allowing byte streams to feed directly into models. However, this approach hasn’t been validated by multiple groups at sufficient scale. Until such methods mature, we must compress byte sequences using the Byte Pair Encoding algorithm.
The Byte Pair Encoding algorithm is relatively straightforward, and the Wikipedia page provides a clear explanation of the basic concept. The algorithm operates on an input sequence—for example, a sequence containing only four vocabulary elements: a, b, c, and d. Rather than working with bytes directly, consider this simplified case with a vocabulary size of four.
When a sequence becomes too long and requires compression, the algorithm iteratively identifies the most frequently occurring pair of tokens. Once identified, that pair is replaced with a single new token appended to the vocabulary. For instance, if the byte pair ‘aa’ occurs most often, we create a new token (call it capital Z) and replace every occurrence of ‘aa’ with Z, resulting in two Z’s in the sequence.
Step 1: Initial sequence
aaabdaaabacMost frequent pair: aa (occurs 2 times)
Replace aa with Z:
Zabdaabac → ZabdZabacThis transformation converts a sequence of 11 characters with vocabulary size four into a sequence of nine tokens with vocabulary size five. The fifth vocabulary element, Z, represents the concatenation of ‘aa’. The process repeats: examining the sequence to identify the most frequent token pair. If ‘ab’ is now most frequent, we create a new token Y to represent ‘ab’, replacing every occurrence.
Step 2: Continue compression
ZabdZabacMost frequent pair: ab (occurs 2 times)
Replace ab with Y:
ZYdZYacThe sequence now contains seven characters with a vocabulary of six elements. In the final round, the pair ‘ZY’ appears most commonly, prompting creation of token X to represent ‘ZY’. Replacing all occurrences produces the final sequence.
Step 3: Final merge
ZYdZYacMost frequent pair: ZY (occurs 2 times)
Replace ZY with X:
XdXacFinal result: XdXac
Final vocabulary: {a, b, c, d, Z=aa, Y=ab, X=ZY}
Original length: 11 tokens → Compressed length: 5 tokens
After completing this process, the sequence has transformed from 11 tokens with vocabulary length four to 5 tokens with vocabulary length seven. The algorithm iteratively compresses the sequence while minting new tokens. The same approach applies to byte sequences: starting with 256 vocabulary size, we identify the most common byte pairs and iteratively mint new tokens, appending them to the vocabulary and performing replacements. This produces a compressed training dataset along with an algorithm for encoding arbitrary sequences using this vocabulary and decoding them back to strings.
To implement this algorithm, the following example uses the first paragraph from this blog post, copied as a single long line of text.
To obtain the tokens, we encode the text into UTF-8. The tokens at this point are raw bytes in a single stream. For easier manipulation in Python, we convert the bytes object to a list of integers for better visualization and handling. The output shows the original paragraph and its length of 533 code points. The UTF-8 encoded bytes have a length of 608 bytes (or 608 tokens). This expansion occurs because simple ASCII characters become a single byte, while more complex Unicode characters become multiple bytes, up to four.
# Step 1: Get the sample text from Nathan Reed's blog post
text = """Unicode! 🅤🅝🅘🅒🅞🅓🅔‽ 🇺🇳🇮🇨🇴🇩🇪! 😄 The very name strikes fear and awe into the hearts of programmers worldwide. We all know we ought to "support Unicode" in our software (whatever that means—like using wchar_t for all the strings, right?). But Unicode can be abstruse, and diving into the thousand-page Unicode Standard plus its dozens of supplementary annexes, reports, and notes can be more than a little intimidating. I don't blame programmers for still finding the whole thing mysterious, even 30 years after Unicode's inception."""
print(f"Text: {text}")
print(f"Length in characters: {len(text)}")# Step 2: Encode the text to UTF-8 bytes and convert to list of integers
tokens = list(text.encode("utf-8"))
print(f"UTF-8 encoded bytes: {tokens[:50]}...") # Show first 50 bytes
print(f"Length in bytes: {len(tokens)}")The first step of the algorithm requires iterating over the bytes to find the most frequently occurring pair, which we’ll then merge. The following implementation uses a function called get_stats to find the most common pair. Multiple approaches exist, but this one uses a dictionary to track counts. The iteration over consecutive elements uses a Pythonic pattern with zip(ids, ids[1:]). The function increments the count for each pair encountered.
def get_stats(ids, counts=None):
"""
Given a list of integers, return a dictionary of counts of consecutive pairs
Example: [1, 2, 3, 1, 2] -> {(1, 2): 2, (2, 3): 1, (3, 1): 1}
Optionally allows to update an existing dictionary of counts
"""
counts = {} if counts is None else counts
for pair in zip(ids, ids[1:]): # iterate consecutive elements
counts[pair] = counts.get(pair, 0) + 1
return countsThe zip(ids, ids[1:]) pattern for consecutive pairs works as follows:
# Step 3a: Understand how zip(ids, ids[1:]) works for consecutive pairs
sample_list = [1, 2, 3, 4, 5]
consecutive_pairs = list(zip(sample_list, sample_list[1:]))
print(f"Sample list: {sample_list}")
print(f"Consecutive pairs: {consecutive_pairs}")
print("This is the 'Pythonic way' Andrej mentions for iterating consecutive elements")Calling get_stats on the tokens produces a dictionary where the keys are tuples of consecutive elements, and the values are their counts:
# Step 3: Find the most common consecutive pair using get_stats
stats = get_stats(tokens)
print(f"Total number of unique pairs: {len(stats)}")
# Show top 10 most frequent pairs
top_pairs = sorted([(count, pair) for pair, count in stats.items()], reverse=True)[:10]
print("\nTop 10 most frequent pairs:")
for count, pair in top_pairs:
print(f" {pair}: {count} times")To display the results more clearly, we can iterate over the dictionary items (which return key-value pairs) and create a value-key list instead. This allows us to call sort() on it, since Python defaults to sorting by the first element in tuples. Using reverse=True produces descending order.
The results show that the pair (101, 32) occurs most frequently, appearing 20 times. Searching for all occurrences of 101, 32 in the token list confirms these 20 instances.
# Step 4: Get the most frequent pair using max() function
most_frequent_pair = max(stats, key=stats.get)
print(f"Most frequent pair: {most_frequent_pair}")
print(f"Occurs {stats[most_frequent_pair]} times")
# Convert bytes back to characters to see what this pair represents
char1 = chr(most_frequent_pair[0])
char2 = chr(most_frequent_pair[1])
print(f"This represents: '{char1}' + '{char2}'")To examine what this pair represents, we use chr, which is the inverse of ord in Python. Given the Unicode code points 101 and 32, we find this represents ‘e’ followed by a space. Many words in the text end with ‘e’, accounting for the frequency of this pair.
We can verify the most frequent pair by finding its occurrences in the text:
# Step 4a: Verify the most frequent pair by finding its occurrences in the text
pair_to_find = most_frequent_pair # (101, 32) which is 'e' + ' '
# Find all positions where this pair occurs
occurrences = []
for i in range(len(tokens) - 1):
if tokens[i] == pair_to_find[0] and tokens[i + 1] == pair_to_find[1]:
occurrences.append(i)
print(f"Found {len(occurrences)} occurrences of pair {pair_to_find} ('e' + ' ') at positions:")
print(f"Positions: {occurrences}")Having identified the most common pair, the next step is to iterate over the sequence and mint a new token with ID 256. Current tokens range from 0 to 255, making 256 the next available ID. The algorithm will iterate over the entire list, replacing every occurrence of (101, 32) with 256.
# Step 5: Prepare to merge - create new token ID
# Current tokens are 0-255 (256 possible values), so new token will be 256
new_token_id = 256
print(f"Will replace pair {most_frequent_pair} with new token ID: {new_token_id}")
print(f"Ready to implement merge function...")Python provides an elegant way to obtain the highest-ranking pair using max() on the stats dictionary. This returns the maximum key. The ranking function is specified with key=stats.get, which returns the value for each key. This ranks by value and returns the key with the maximum value: (101, 32).
Having identified the most common pair, the next step is to iterate over the sequence and mint a new token with ID 256. Current tokens range from 0 to 255, making 256 the next available ID. The algorithm iterates over the entire list, replacing every occurrence of (101, 32) with 256.
# Step 6: Implement the merge function
def merge(ids, pair, idx):
"""
In the list of integers (ids), replace all consecutive occurrences
of pair with the new integer token idx
Example: ids=[1, 2, 3, 1, 2], pair=(1, 2), idx=4 -> [4, 3, 4]
"""
newids = []
i = 0
while i < len(ids):
# if not at the very last position AND the pair matches, replace it
if ids[i] == pair[0] and i < len(ids) - 1 and ids[i+1] == pair[1]:
newids.append(idx)
i += 2 # skip over the pair
else:
newids.append(ids[i])
i += 1
return newidsTesting with a simple example first demonstrates the merge function’s behavior:
# Test with simple example
test_ids = [5, 6, 6, 7, 9, 1]
result = merge(test_ids, (6, 7), 99)
print(f"Original: {test_ids}")
print(f"After merging (6, 7) -> 99: {result}")Applying the merge to the actual tokens:
# Step 7: Apply merge to our actual tokens
# Merge the most frequent pair (101, 32) with token ID 256
tokens2 = merge(tokens, most_frequent_pair, new_token_id)
print(f"Original length: {len(tokens)}")
print(f"After merge length: {len(tokens2)}")
print(f"Reduction: {len(tokens) - len(tokens2)} tokens")
# Verify the merge worked
print(f"\nOccurrences of new token {new_token_id}: {tokens2.count(new_token_id)}")
print(f"Occurrences of old pair in original: {sum(1 for i in range(len(tokens)-1) if (tokens[i], tokens[i+1]) == most_frequent_pair)}")
# Verify old pair is gone
old_pair_count = sum(1 for i in range(len(tokens2)-1) if (tokens2[i], tokens2[i+1]) == most_frequent_pair)
print(f"Occurrences of old pair in new tokens: {old_pair_count}")The BPE algorithm proceeds iteratively: find the most common pair, merge it, and repeat.
# Step 8: Iterate the BPE algorithm
# Now we repeat: find most common pair, merge it, repeat...
# Let's do a few more iterations
current_tokens = tokens2
vocab_size = 257 # Started with 256, now have 257
print("BPE Training Progress:")
print(f"Step 0: {len(tokens)} tokens, vocab size: 256")
print(f"Step 1: {len(current_tokens)} tokens, vocab size: {vocab_size}")
# Do a few more iterations
for step in range(2, 6): # Steps 2-5
# Find most common pair
stats = get_stats(current_tokens)
if not stats: # No more pairs to merge
break
most_frequent_pair = max(stats, key=stats.get)
# Merge it
current_tokens = merge(current_tokens, most_frequent_pair, vocab_size)
print(f"Step {step}: {len(current_tokens)} tokens, vocab size: {vocab_size + 1}")
print(f" Merged pair: {most_frequent_pair} -> {vocab_size}")
vocab_size += 1
print(f"\nFinal: {len(current_tokens)} tokens, vocab size: {vocab_size}")Tracking the merges reveals what the tokenizer learned:
# Track the merges we made
merges = {
256: (101, 32), # 'e' + ' '
257: (100, 32), # 'd' + ' '
258: (116, 101), # 't' + 'e'
259: (115, 32), # 's' + ' '
260: (105, 110) # 'i' + 'n'
}
for token_id, (byte1, byte2) in merges.items():
char1, char2 = chr(byte1), chr(byte2)
print(f"Token {token_id}: ({byte1}, {byte2}) -> '{char1}' + '{char2}' = '{char1}{char2}'")This completes the fundamentals of BPE. The algorithm iteratively finds the most frequent byte pairs and merges them into new tokens, gradually building up a vocabulary that efficiently represents the text.
Building the Core Functions
Having understood the BPE algorithm conceptually, we can now build the complete tokenizer with training, encoding, and decoding functions. To get more representative statistics for byte pairs and produce sensible results, we’ll use the entire blog post as our training text rather than just the first paragraph. The raw text is encoded into bytes using UTF-8 encoding, then converted into a list of integers in Python for easier manipulation.
# text = full blog post text copied from the colab notebook
tokens = list(text.encode("utf-8"))
print(f"UTF-8 encoded bytes: {tokens[:50]}...") # Show first 50 bytes
print(f"Length in bytes: {len(tokens)}")The merging loop uses the same two functions defined earlier (get_stats and merge), repeated here for reference. The new code begins by setting the final vocabulary size—a hyperparameter that you adjust depending on best performance. Using 276 as the target vocabulary size means performing exactly 20 merges, since we start with 256 tokens for the raw bytes.
# BPE training
vocab_size = 276 # hyperparameter: the desired final vocabulary size
num_merges = vocab_size - 256
tokens = list(text.encode("utf-8"))
for i in range(num_merges):
# count up all the pairs
stats = get_stats(tokens)
# find the pair with the highest count
pair = max(stats, key=stats.get)
# mint a new token: assign it the next available id
idx = 256 + i
# replace all occurrences of pair in tokens with idx
tokens = merge(tokens, pair, idx)
# print progress
print(f"merge {i+1}/{num_merges}: {pair} -> {idx} ({stats[pair]} occurrences)")Wrapping the tokens list in list() creates a copy of the list in Python. The merges dictionary maintains the mapping from child pairs to new tokens, building up a binary forest of merges. This structure differs from a tree because we start with the leaves at the bottom (the individual bytes as the starting 256 tokens) and merge two at a time, creating multiple roots rather than a single root.
For each of the 20 merges, the algorithm finds the most commonly occurring pair, mints a new token integer (starting with 256 when i is zero), and replaces all occurrences of that pair with the newly minted token. The merge is recorded in the dictionary. Running this produces the output showing all 20 merges.
The first merge matches our earlier example: tokens (101, 32) merge into new token 256. Note that individual tokens 101 and 32 can still occur in the sequence after merging—only consecutive occurrences become 256. Newly minted tokens are also eligible for merging in subsequent iterations. The 20th merge combines tokens 256 and 259 into 275, demonstrating how replacement makes tokens eligible for merging in the next round. This builds up a small binary forest rather than a single tree.
The compression ratio achieved can be calculated from the token counts. The original text contained 24,000 bytes, which after 20 merges reduced to 19,000 tokens. The compression ratio of approximately 1.27 comes from dividing these two values. More vocabulary elements would increase the compression ratio further.
This process represents the training of the tokenizer. The tokenizer is a completely separate object from the large language model itself—this entire discussion concerns only tokenizer training, not the LLM. The tokenizer undergoes its own preprocessing stage, typically separate from the LLM.
graph TB
subgraph "Stage 1: Tokenizer Training"
A[Raw Text Documents<br/>Tokenizer Training Set] --> B[BPE Algorithm]
B --> C[Vocabulary + Merges<br/>e.g., 50,000 tokens]
C --> D[Trained Tokenizer]
end
subgraph "Stage 2: LLM Training"
E[Raw Text Documents<br/>LLM Training Set] --> D
D --> F[Token Sequences<br/>e.g., 1,2,45,678,...]
F --> G[Transformer Model]
G --> H[Trained LLM]
end
style A fill:#e1f5ff
style C fill:#90EE90
style E fill:#ffe1f5
style H fill:#FFD700
note1[Different datasets!<br/>Tokenizer may train on<br/>more diverse languages]
note2[Completely separate<br/>training stages]
A -.-> note1
B -.-> note2
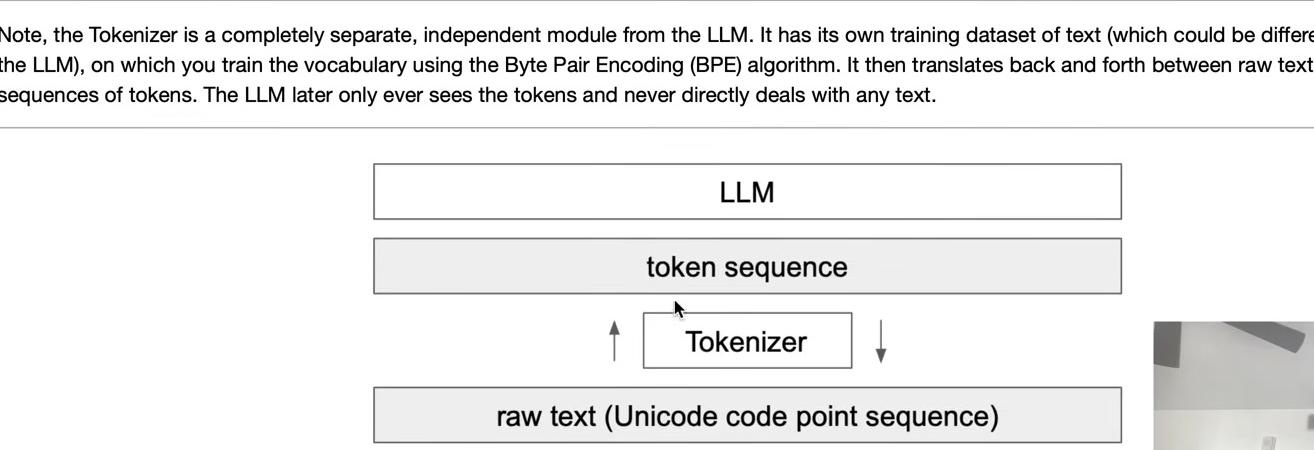
The tokenizer has its own training set of documents, potentially different from the LLM’s training set. Training the tokenizer uses the Byte Pair Encoding algorithm to create the vocabulary. Once trained with its vocabulary and merges, the tokenizer can perform both encoding and decoding—translating between raw text (sequences of Unicode code points) and token sequences in both directions.
With a trained tokenizer that has the merges, we can now implement the encoding and decoding steps. Given text, the tokenizer produces tokens; given tokens, it produces text. This translation layer sits between the two realms.
The language model is trained as a separate second step. In state-of-the-art applications, all training data for the language model typically runs through the tokenizer first, translating everything into a massive token sequence. The raw text can then be discarded, leaving only the tokens stored on disk for the large language model to read during training. This represents one approach using a single massive preprocessing stage.
The key point is that tokenizer training is a completely separate stage with its own training set. The training sets for the tokenizer and the large language model may differ intentionally. For example, tokenizer training should account for performance across many different languages, not just English, as well as code versus natural language. Different mixtures of languages and varying amounts of code in the tokenizer training set determine how many merges occur for each type of content, which affects the density of representation in the token space.
Intuitively, including substantial Japanese data in the tokenizer training set results in more Japanese token merges, producing shorter token sequences for Japanese text. This benefits the large language model, which operates with finite context length in token space.
With the tokenizer trained and the merges determined, we can now turn to implementing encoding and decoding.
Decoding: From Tokens Back to Text
The decoding function translates a token sequence back into a Python string object (raw text). The goal is to implement a function that takes a list of integers and returns a Python string. This is a good exercise to try yourself before looking at the solution.
Here’s one implementation approach. First, create a preprocessing variable called vocab—a dictionary mapping token IDs to their corresponding bytes objects. Start with the raw bytes for tokens 0 to 255, then populate the vocab dictionary by iterating through all merges in order. Each merged token’s bytes representation is the concatenation of its two child tokens’ bytes.
# Track the merges we made
merges = {
(101, 32) : 256, # 'e' + ' '
(100, 32) : 257, # 'd' + ' '
(116, 101) : 258, # 't' + 'e'
(115, 32) : 259, # 's' + ' '
(105, 110): 260 # 'i' + 'n'
}
# given ids (list of integers), return Python string
vocab = {idx: bytes([idx]) for idx in range(256)}
for (p0, p1), idx in merges.items():
vocab[idx] = vocab[p0] + vocab[p1]
def decode(ids):
# given ids, get tokens
tokens = b"".join(vocab[idx] for idx in ids)
# convert from bytes to string
text = tokens.decode("utf-8")
return textOne important detail: iterating through the dictionary with .items() requires that the iteration order match the insertion order of items into the merges dictionary. Starting with Python 3.7, this is guaranteed, but earlier versions may have iterated in a different order, potentially causing issues.
The decode function first converts IDs to tokens by looking up each ID in the vocab dictionary and concatenating all bytes together. These tokens are raw bytes that must be decoded using UTF-8 to convert back into Python strings. This reverses the earlier .encode() operation: instead of calling encode on a string object to get bytes, we call decode on the bytes object to get a string.
Testing the function:
print(decode([97])) # Should work fineHowever, this implementation has a potential issue that could throw an error with certain unlucky ID sequences. Decoding token 97 works fine, returning the letter ‘a’. But attempting to decode token 128 as a single element produces an error:
try:print(decode([128])) # This will cause UnicodeDecodeError
except Exception as e: print(str(e))The error message reads: “UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x80 in position 0: invalid start byte.”
This error relates to the UTF-8 encoding schema. UTF-8 bytes follow a specific format, particularly for multi-byte characters. The binary representation of 128 is one followed by all zeros (10000000). This doesn’t conform to UTF-8 rules—a byte starting with ‘1’ must be followed by another ‘1’, then a ‘0’, then the Unicode content. The single ‘1’ followed by zeros is an invalid start byte.
Not every byte sequence represents valid UTF-8. If a large language model predicts tokens in an invalid sequence, decoding will fail. The solution is to use the errors parameter in the bytes.decode function. By default, errors is set to ‘strict’, which throws an error for invalid UTF-8 byte encodings. Python provides many error handling options. Changing to errors="replace" substitutes a replacement character (�) for invalid sequences:
def decode(ids):
# given ids (list of integers), return Python string
tokens = b"".join(vocab[idx] for idx in ids)
text = tokens.decode("utf-8", errors="replace")
return texttry:print(decode([128])) # This should now print the replacement character without error
except Exception as e: print(str(e))The standard practice is to use errors="replace", which is also found in the OpenAI code release. Whenever you see the replacement character (�) in output, it indicates the LLM produced an invalid token sequence.
Encoding: From Text to Tokens
The encoding function performs the reverse operation: converting a string into tokens. The function signature takes text input and returns a list of integers representing the tokens. This is another good exercise to attempt yourself before reviewing the solution.
Here’s one implementation approach. First, encode the text into UTF-8 to get the raw bytes, then convert the bytes object to a list of integers. These starting tokens represent the raw bytes of the sequence.
def encode(text):
# given a string, return list of integers (the tokens)
tokens = list(text.encode("utf-8"))
while True:
stats = get_stats(tokens)
pair = min(stats, key=lambda p: merges.get(p, float("inf")))
if pair not in merges:
break # nothing else can be merged
idx = merges[pair]
tokens = merge(tokens, pair, idx)
return tokensAccording to the merges dictionary, some bytes may be merged. Recall that merges was built from top to bottom in the order items were inserted. We must apply merges in this order—from top to bottom—because later merges depend on earlier ones. For example, a later merge might rely on token 256, which was created by an earlier merge.
Since multiple merges are expected, the function uses a while loop. The goal is to find consecutive byte pairs that are allowed to merge according to the merges dictionary. To reuse existing functionality, the get_stats function counts how many times each pair occurs in the token sequence and returns this as a dictionary mapping byte pairs to their occurrence counts. For this implementation, only the keys of this dictionary matter—we only need the set of possible merge candidates, not their frequencies.
Testing the encoding:
print(encode("hello world!"))and both together:
print(decode(encode("hello world!")))The next step is identifying which pair to merge in each loop iteration. We want the pair with the lowest index in the merges dictionary, ensuring early merges occur before later ones. The implementation uses Python’s min function over an iterator. When calling min on a dictionary, Python iterates over the keys—in this case, all the consecutive pairs. The key parameter specifies the function that returns the value for comparison. Here, we use merges.get(p, float("inf")) to retrieve each pair’s index in the merges dictionary.
Handling Edge Cases
The current implementation needs refinement to handle a special case. Attempting to encode a single character produces an error because when the token list contains only one element or is empty, the stats dictionary is empty, causing min to fail. The solution is to check if the token list has at least two elements before proceeding with merges. If fewer than two tokens exist, there’s nothing to merge, so the function returns immediately.
try: print(encode('h'))
except Exception as e: print(e)def encode(text):
# given a string, return list of integers (the tokens)
tokens = list(text.encode("utf-8"))
while True:
stats = get_stats(tokens)
if len(tokens) < 2:
break # nothing to merge
pair = min(stats, key=lambda p: merges.get(p, float("inf")))
if pair not in merges:
break # nothing else can be merged
idx = merges[pair]
tokens = merge(tokens, pair, idx)
return tokensencode('h')Testing the encode-decode cycle reveals an important property. Encoding a string and then decoding it back should return the same string:
# Test that encode/decode is identity for training text
text2 = decode(encode(text))
test_eq(text, text2)# Test on new validation text
valtext = "Many common characters, including numerals, punctuation, and other symbols, are unified within the standard"
test_eq(decode(encode(valtext)), valtext)This holds true in general, but the reverse is not guaranteed. Not all token sequences represent valid UTF-8 byte streams, making some sequences undecodable. The identity property only works in one direction. Testing with the training text confirms that encoding and decoding returns the original text. Testing with validation data—text grabbed from this web page that the tokenizer has not seen—also works correctly, giving confidence in the implementation.
These are the fundamentals of the byte-pair encoding algorithm. The process takes a training set and trains a tokenizer, where the parameters are simply the merges dictionary. This creates a binary forest on top of raw bytes. With this merges table, we can encode and decode between raw text and token sequences.
This represents the simplest tokenizer setting. The next step is examining state-of-the-art large language models and their tokenizers. The picture becomes significantly more complex. The following sections explore these complexities one at a time.
GPT-2 and GPT-4 Tokenizers
Regex-Based Pre-tokenization
The GPT-2 paper from 2019 provides insight into the tokenization approach used in the GPT series. The “Input Representation” section motivates the use of the byte-pair encoding algorithm on the byte level representation of UTF-8 encoding, discussing vocabulary sizes and implementation details.
The paper covers concepts consistent with the fundamentals discussed earlier, but introduces an important divergence. The authors don’t apply the naive BPE algorithm directly. Consider a motivating example: common words like “dog” occur frequently in text alongside various punctuation marks—“dog.”, “dog!”, “dog?”, etc. The naive BPE algorithm could merge these into single tokens, resulting in numerous tokens that combine the same word with different punctuation. This clusters elements that shouldn’t be clustered, mixing semantics with punctuation.
The paper acknowledges this suboptimality:
“We observed BPE includes many versions of common words like ‘dog’ since they occur in many contexts (e.g., ‘dog.’, ‘dog!’, ‘dog?’, etc.). This results in a sub-optimal allocation of limited vocabulary slots and model capacity. To avoid this, we prevent BPE from merging across character categories for any byte sequence.”
To address this, the authors manually enforce rules preventing certain character types from merging together, imposing constraints on top of the byte-pair encoding algorithm.
The GPT-2 repository on GitHub contains the implementation in encoder.py. (The filename is somewhat misleading since this is the tokenizer, which handles both encoding and decoding.) The core mechanism for enforcing merge rules is a complex regex pattern:
# GPT-2 Encoder with regex pattern
class Encoder:
def __init__(self, encoder, bpe_merges, errors='replace'):
self.encoder = encoder
self.decoder = {v:k for k,v in self.encoder.items()}
self.bpe_merges = dict(zip(bpe_merges, range(len(bpe_merges))))
self.cache = {}
self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")Note that the import uses import regex as re rather than the standard Python re module. The regex package (installable via pip install regex) extends the standard re module with additional functionality.
import regex as repat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")Testing this pattern reveals its behavior. The code calls re.findall with this pattern on input strings intended for encoding into tokens:
# Test the regex pattern on simple text
text = "Hello world"
matches = pat.findall(text)
print(f"Text: '{text}'")
print(f"Matches: {matches}")
print(f"Number of chunks: {len(matches)}")The function re.findall matches the pattern against the string from left to right, collecting all occurrences into a list. The pattern is a raw string (indicated by the r prefix) using triple quotes, with the pattern itself consisting of multiple alternatives separated by vertical bars (ors in regex).
Matching proceeds by attempting each alternative in order. For “hello”, the first several alternatives don’t match, but ?\p{L}+ does. The \p{L} pattern matches a letter from any language. The sequence “hello” consists of letters, matching as an optional space followed by one or more letters. The match ends at the whitespace following “hello” since whitespace isn’t a letter. Matching resumes from the space, eventually matching ” world” (space followed by letters).
Breaking down the pattern components:
Pattern: 's|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+
Components:
's|'t|'re|'ve|'m|'ll|'d→ Common contractions?\p{L}+→ Optional space + one or more letters?\p{N}+→ Optional space + one or more numbers?[^\s\p{L}\p{N}]+→ Optional space + punctuation/symbols\s+(?!\S)|\s+→ Whitespace handling
# Test with more complex text including punctuation
text2 = "Hello world how are you?"
matches2 = pat.findall(text2)
print(f"Text: '{text2}'")
print(f"Matches: {matches2}")
print(f"Number of chunks: {len(matches2)}")The regex pattern ensures BPE merging respects natural language boundaries by splitting text into these categories:
What it captures:
- Contractions - Common English contractions like “don’t”, “we’re”, “I’ll” are kept as single units
- Words - Letters from any language (including accented characters) are grouped together, optionally preceded by a space
- Numbers - Digits are grouped together, optionally preceded by a space
- Punctuation & Symbols - Non-letter, non-digit characters are grouped together, optionally preceded by a space
- Whitespace - Handles various whitespace patterns
Why this matters:
- Prevents “dog” + “.” from merging into a single token
- Keeps semantic meaning (words) separate from punctuation
- Allows BPE to work within each category, but not across categories
- Results in more meaningful token boundaries that respect language structure
pat.findall("I'll go! I don't know 123? ")This splitting mechanism processes text by first dividing it into a list of chunks. Each chunk is tokenized independently, with the results concatenated. For “Hello world how are you?”, the five list elements are each converted from text to a token sequence, then joined. This approach restricts merges to within chunks—elements from different chunks can never merge. The ‘e’ at the end of “Hello” cannot merge with the space beginning ” world” because they belong to separate chunks.
The \p{N} pattern matches numeric characters in any script. Letters and numbers are separated:
# Step 1: Show how letters and numbers are separated
text = "Hello world123 how are you?"
matches = pat.findall(text)
print(f"Text: '{text}'")
print(f"Matches: {matches}")
print("Notice: 'world' and '123' are separate chunks")In “Hello world123 how are you?”, “world” stops matching at ‘1’ since digits aren’t letters, but the numbers match as a separate group.
The apostrophe handling shows some limitations. The pattern includes specific apostrophe contractions. With “how’s”, the 's matches the pattern:
# Step 2: Show how contractions work with standard apostrophes
text = "how's it going"
matches = pat.findall(text)
print(f"Text: '{text}'")
print(f"Matches: {matches}")
print("Notice: Standard apostrophe 's' is kept with the word")However, Unicode apostrophes behave differently:
# Step 3: Show the Unicode apostrophe problem
text = "how\u2019s it going" # Unicode apostrophe (different from standard ')
matches = pat.findall(text)
print(f"Text: '{text}'")
print(f"Matches: {matches}")
print("Notice: Unicode apostrophe becomes its own separate chunk!")The pattern hardcodes the standard apostrophe character, causing Unicode variants to become separate tokens. The GPT-2 documentation acknowledges another issue: “should have added re.ignorecase so BPE merges can happen for capitalized versions of contractions.” Because the pattern uses lowercase letters without case-insensitive matching, uppercase contractions behave inconsistently:
pat.findall("HOW'S it going?")With “HOW’S” in uppercase, the apostrophe becomes its own token. This creates inconsistent tokenization between uppercase and lowercase text. These apostrophe patterns also appear language-specific, potentially causing inconsistent tokenization across languages.
After attempting to match apostrophe expressions, letters, and numbers, the pattern falls back to ?[^\s\p{L}\p{N}]+, which matches an optional space followed by characters that are not letters, numbers, or spaces. This captures punctuation:
pat.findall("you!!!??")The punctuation characters match this group and become a separate chunk.
The whitespace handling uses a negative lookahead assertion: \s+(?!\S). This matches whitespace up to but not including the last whitespace character. This subtle distinction matters because spaces are typically included at the beginning of words (like ” r”, ” u”). With multiple consecutive spaces, all spaces except the last are captured by this pattern, allowing the final space to join with the following word. This ensures “space + you” remains a common token pattern whether preceded by one space or many:
pat.findall(" you")The GPT-2 tokenizer consistently prepends spaces to letters or numbers. The final fallback pattern \s+ catches any trailing spaces not matched by previous patterns.
A real-world example using Python code demonstrates the splitting behavior:
example = """
for i in range(1, 101):
if i % 3 == 0 and i % 5 == 0:
print("FizzBuzz")
elif i % 3 == 0:
print("Fizz")
elif i % 5 == 0:
print("Buzz")
else:
print(i)
"""
print(pat.findall(example))The output contains many elements because splitting occurs frequently when categories change. Merges can only happen within individual elements.
The training process for the GPT-2 tokenizer differs from simply chunking text and applying BPE to each chunk. Notice that spaces appear as separate elements in the chunk list, but OpenAI never merges these spaces. Testing the same Python code in the tiktokenizer shows all spaces remain independent as token 220:

OpenAI appears to have enforced additional rules preventing space merges. The training code for the GPT-2 tokenizer was never released—only the inference code shown above. This code applies existing merges to new text but cannot train a tokenizer from scratch. The exact training procedure OpenAI used remains unclear, though it involved more than simple chunking and BPE application.
The tiktoken Library
The tiktoken library from OpenAI provides the official implementation for tokenization. After installation via pip install tiktoken, the library enables tokenization inference. Note that this is inference code only, not training code.
The usage is straightforward, producing either GPT-2 or GPT-4 tokens depending on which encoding is selected:
import tiktoken# Compare GPT-2 vs GPT-4 tokenization
enc_gpt2 = tiktoken.get_encoding("gpt2")
enc_gpt4 = tiktoken.get_encoding("cl100k_base")
tokens_gpt2 = enc_gpt2.encode(example)
tokens_gpt4 = enc_gpt4.encode(example)
print(f"GPT-2 tokens: {len(tokens_gpt2)}")
print(f"GPT-4 tokens: {len(tokens_gpt4)}")A notable difference appears in whitespace handling. The GPT-2 tokenizer leaves whitespace unmerged, while GPT-4 merges consecutive spaces:
decoded_gpt4 = [enc_gpt4.decode([token]) for token in tokens_gpt4]
for i, token_str in enumerate(decoded_gpt4):
if token_str.strip() == '': print(f"Token {i}: {repr(token_str)} (all whitespace)")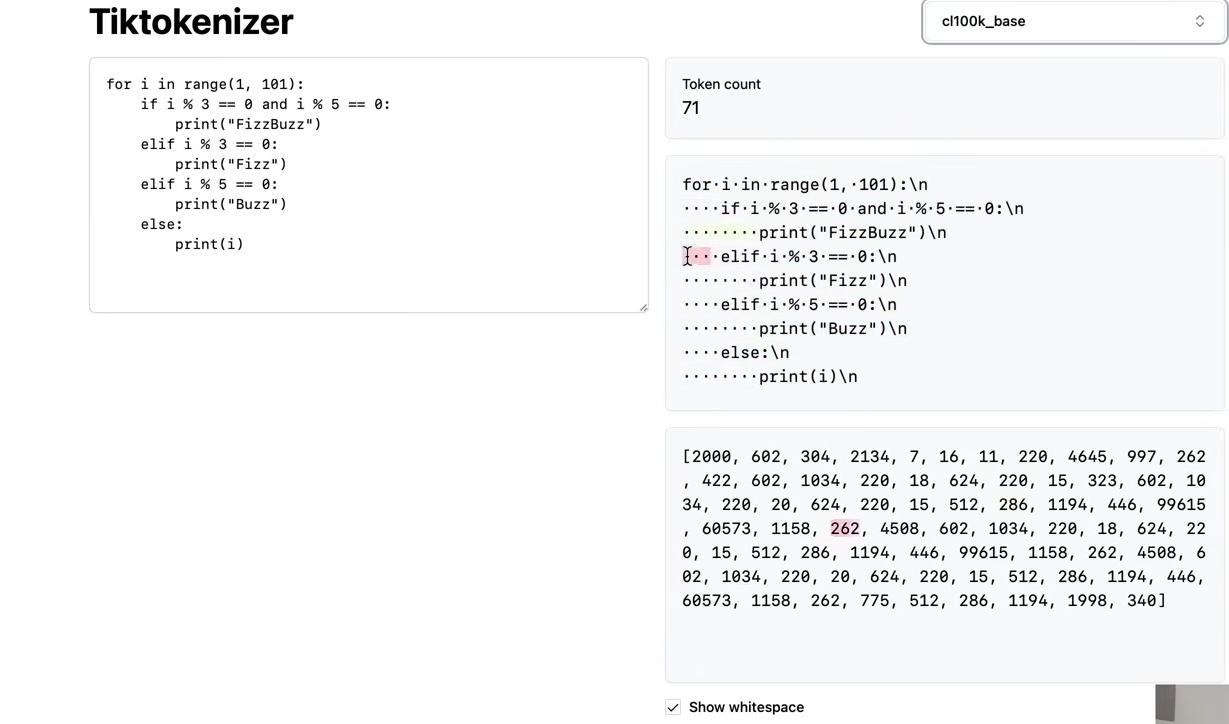
The GPT-4 tokenizer uses a different regular expression for chunking text. The openai_public.py file in the tiktoken library defines all the tokenizers OpenAI maintains. To perform inference, these details must be published. The GPT-2 pattern appears with a slight modification that executes faster while remaining functionally equivalent:
# GPT-2 tokenizer pattern from tiktoken openai_public.py
def gpt2():
mergeable_ranks = data_gym_to_mergeable_bpe_ranks(
vocab_bpe_file="https://openaipublic.blob.core.windows.net/gpt-2/encodings/main/vocab.bpe",
encoder_json_file="https://openaipublic.blob.core.windows.net/gpt-2/encodings/main/encoder.json",
vocab_bpe_hash="1ce1664773c50f3e0cc8842619a93edc4624525b728b188a9e0be33b7726adc5",
encoder_json_hash="196139668be63f3b5d6574427317ae82f612a97c5d1cdaf36ed2256dbf636783",
)
return {
"name": "gpt2",
"explicit_n_vocab": 50257,
# The pattern in the original GPT-2 release is:
# r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
# This is equivalent, but executes faster:
"pat_str": r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}++| ?\p{N}++| ?[^\s\p{L}\p{N}]++|\s++$|\s+(?!\S)|\s""",
"mergeable_ranks": mergeable_ranks,
"special_tokens": {"<|endoftext|>": 50256},
}Special tokens will be covered in detail later. The cl100k definition further down in the file reveals the GPT-4 tokenizer with its modified pattern—the main change besides additional special tokens:
# GPT-4 tokenizer pattern from tiktoken openai_public.py
def cl100k_base():
mergeable_ranks = load_tiktoken_bpe(
"https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken"
)
special_tokens = {
"<|endoftext|>": 100257,
"<|fim_prefix|>": 100258,
"<|fim_middle|>": 100259,
"<|fim_suffix|>": 100260,
"<|endofprompt|>": 100276
}
return {
"name": "cl100k_base",
"explicit_n_vocab": 100277,
# Different pattern from GPT-2 - handles whitespace better
"pat_str": r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{2,}|[^\r\n\p{L}\p{N}]?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+""",
"mergeable_ranks": mergeable_ranks,
"special_tokens": special_tokens,
}The full details of the pattern change are complex enough to warrant using ChatGPT and regex documentation to step through carefully. The major changes include case-insensitive matching (indicated by (?i:...)), which addresses the earlier comment about uppercase handling. Apostrophe contractions (’s, ’d, ’m, etc.) now match consistently in both lowercase and uppercase. Various whitespace handling improvements exist that won’t be detailed exhaustively here. One notable change: numbers match only with two or more digits (\p{N}{2,}), preventing very long number sequences from merging into single tokens.
The lack of documentation means the reasoning behind these choices remains unclear—only the pattern itself is available. The vocabulary size also increased from approximately 50,000 to approximately 100,000.
The GPT-4 pattern: r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{2,}|[^\r\n\p{L}\p{N}]?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+"""
Breaking it down:
(?i:'s|'t|'re|'ve|'m|'ll|'d)- Case-insensitive contractions (fixes the uppercase problem!)[^\r\n\p{L}\p{N}]?\p{L}+- Optional non-letter/non-digit/non-newline + letters
\p{N}{2,}- Numbers with 2+ digits (changed from 1+ in GPT-2)[^\r\n\p{L}\p{N}]?[^\s\p{L}\p{N}]+[\r\n]*- Punctuation/symbols with optional newlines\s*[\r\n]+- Newline handling with optional spaces\s+(?!\S)|\s+- Whitespace handling (similar to GPT-2)
Key improvements over GPT-2:
- Case-insensitive contractions (
(?i:...)) - Better newline handling
- Numbers require 2+ digits (prevents single digit tokens)
- More sophisticated whitespace merging
Testing these differences reveals the improvements:
# Step 1: Test case-insensitive contractions (GPT-4 vs GPT-2)
gpt4_pat = re.compile(r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{2,}|[^\r\n\p{L}\p{N}]?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+""")
# Test uppercase contractions
test_text = "HOW'S IT GOING? how's it going?"
gpt2_result = pat.findall(test_text)
gpt4_result = gpt4_pat.findall(test_text)
print(f"Text: '{test_text}'")
print(f"GPT-2: {gpt2_result}")
print(f"GPT-4: {gpt4_result}")
print("Notice: GPT-4 keeps 'HOW'S' together, GPT-2 splits it!")# Step 2: Test number handling (2+ digits requirement)
test_numbers = "I have 1 apple, 12 oranges, and 123 bananas."
gpt2_result = pat.findall(test_numbers)
gpt4_result = gpt4_pat.findall(test_numbers)
print(f"Text: '{test_numbers}'")
print(f"GPT-2: {gpt2_result}")
print(f"GPT-4: {gpt4_result}")
print("Notice: GPT-4 drops single digits entirely (1 is missing), only captures multi-digits (12, 123)")# Step 3: Test newline and whitespace handling
test_newlines = "Hello\nworld\n\n \ntest"
gpt2_result = pat.findall(test_newlines)
gpt4_result = gpt4_pat.findall(test_newlines)
print(f"Text: {repr(test_newlines)}")
print(f"GPT-2: {gpt2_result}")
print(f"GPT-4: {gpt4_result}")
print("Notice: GPT-4 merges more newline sequences together")Building Your Own Tokenizer
The minbpe Exercise
At this point, you have everything needed to build your own GPT-4 tokenizer. The minbpe repository provides a complete implementation for reference.
The minbpe repository will likely continue evolving beyond its current state. The exercise.md file breaks down the implementation into four progressive steps that build toward a complete GPT-4 tokenizer. Follow these steps with the guidance provided, referencing the minbpe repository whenever you get stuck.
Build your own GPT-4 Tokenizer!
This exercise progression will guide you through building a complete GPT-4 style tokenizer step by step. Each step builds upon the previous one, gradually adding complexity until you have a fully functional tokenizer that matches OpenAI’s tiktoken library.
Step 1: Basic BPE Implementation
Write the BasicTokenizer class with the following three core functions:
def train(self, text, vocab_size, verbose=False)def encode(self, text)def decode(self, ids)
Your Task:
- Train your tokenizer on whatever text you like and visualize the merged tokens
- Do they look reasonable?
- One default test you may wish to use is the text file
tests/taylorswift.txt
What you’re building: The simplest possible BPE tokenizer that works directly on raw text without any preprocessing.
# Do your work in solveit hereStep 2: Add Regex Preprocessing (GPT-2/GPT-4 Style)
Convert your BasicTokenizer into a RegexTokenizer that:
- Takes a regex pattern and splits the text exactly as GPT-4 would
- Processes the parts separately as before, then concatenates the results
- Retrain your tokenizer and compare the results before and after
Use the GPT-4 pattern:
GPT4_SPLIT_PATTERN = r"""'(?i:[sdmt]|ll|ve|re)|[^\r\n\p{L}\p{N}]?+\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]++[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+"""Expected Result: You should see that you will now have no tokens that go across categories (numbers, letters, punctuation, more than one whitespace).
# Do your work in solveit hereStep 3: Load GPT-4 Merges
Loading the GPT-4 tokenizer merges allows you to exactly reproduce the GPT-4 tokenizer. This step is the most complex because recovering the original merges from the GPT-4 tokenizer requires handling a byte permutation.
The Challenge:
- GPT-4 applies a byte permutation to the raw bytes before BPE
- We need to “recover” the original merges from the final tokenizer
- Use the
recover_merges()function to extract merges from tiktoken
Your Task:
- Load the GPT-4 tokenizer using tiktoken
- Recover the merges and handle the byte shuffle
- Verify your tokenizer matches tiktoken exactly on test cases
Expected Result: Your RegexTokenizer should now tokenize exactly like GPT-4’s cl100k_base encoding.
# Do your work in solveit hereStep 4: Handle Special Tokens (Optional)
Add support for special tokens like <|endoftext|> to match tiktoken’s behavior completely.
Your Task:
- Extend your tokenizer to handle special tokens
- Implement the
allowed_specialparameter - Test with GPT-4’s special tokens:
<|endoftext|>,<|fim_prefix|>, etc.
Key Features:
- Special tokens bypass normal BPE processing
- They get assigned specific token IDs outside the regular vocabulary
- Handle the
allowed_specialanddisallowed_specialparameters
Expected Result: Your tokenizer can now handle special tokens exactly like tiktoken, including proper error handling for disallowed special tokens.
# Do your work in solveit hereStep 5: Advanced - Explore SentencePiece (Stretch Goal)
This is the most advanced step - understanding how other tokenizers like Llama 2 work differently from GPT’s byte-level BPE.
The Key Difference:
- GPT-style: Byte-level BPE (works on UTF-8 bytes)
- Llama-style: Unicode code point BPE (works on Unicode characters)
Your Challenge:
- Study how SentencePiece tokenization differs from byte-level BPE
- Understand why Llama 2 can handle non-English languages more efficiently
- (Optional) Try implementing a SentencePiece-style tokenizer
Learning Goals:
- Appreciate the trade-offs between different tokenization approaches
- Understand why different models make different tokenization choices
- See how tokenization affects model performance on different languages
Resources: Check the SentencePiece paper and the Llama 2 tokenizer for reference.
# Do your work in solveit hereThe tests and minbpe repository both serve as useful references. The code is kept fairly clean and understandable for easy reference when you get stuck.
Once complete, you should be able to reproduce tiktoken’s behavior. Using the GPT-4 tokenizer, you can encode a string to get tokens, then encode and decode the same string to recover it. The implementation should also include a train function, which the tiktoken library doesn’t provide—tiktoken is inference-only code. Writing your own train function (as minbpe does) enables training custom token vocabularies.
The minbpe repository visualizes the token vocabularies you might obtain. On the left, the GPT-4 merges show the first 256 raw individual bytes, followed by the merges GPT-4 performed during training. The very first merge combined two spaces into a single token (token 256).
This represents the order in which merges occurred during GPT-4 training. The visualization also shows the merge order obtained in minbpe by training a tokenizer on the Wikipedia page for Taylor Swift—chosen because it’s one of the longest available Wikipedia pages.
Comparing the two vocabularies reveals interesting patterns. GPT-4 merged “I” and “M” to create “in” (similar to token 259 in the custom training). The merge of space and “T” to create “spaceT” also appears in both, though at different positions. These differences stem from the training sets. The heavy whitespace presence in GPT-4’s merges suggests substantial Python code in its training set. The Wikipedia page naturally shows less whitespace merging. Despite these differences, both vocabularies look broadly similar because they use the same algorithm.
Key Insights from the minbpe Exercise:
What You Should Be Able to Do:
- Reproduce tiktoken behavior exactly - Your tokenizer should encode/decode strings identically to GPT-4’s cl100k_base
- Implement your own training function - Unlike tiktoken (inference-only), you can train custom vocabularies
- Compare different training datasets - See how training data affects the learned merges
Vocabulary Comparison Insights:
Looking at the side-by-side comparison in the visualization:
Left (GPT-4 Official):
- First 256 tokens: Raw individual bytes
- Token 256: Two spaces merged (indicates lots of code/structured text in training)
- Shows heavy whitespace merging patterns
Right (Taylor Swift Wikipedia):
- Same algorithm, different training data
- Less whitespace merging (typical prose text)
- Similar patterns but different priorities
Key Observations:
- Same algorithm, different results - BPE produces vocabularies that reflect the training data
- Training data matters - GPT-4’s heavy whitespace merging suggests Python code in training set
- Merge order reveals priorities - Most frequent patterns get merged first
- Reproducible patterns - Both show similar merges like “IM” → “in” and “space+T” → “space+T”
The Power of Custom Training:
Training tokenizers optimized for specific domains—whether code, medical text, or specialized content—becomes possible with this approach.
SentencePiece and Alternative Approaches
How SentencePiece Differs
Moving beyond tiktoken and OpenAI’s tokenization approach, we’ll examine another commonly used library for working with tokenization in LLMs: SentencePiece. Unlike tiktoken, SentencePiece handles both training and inference efficiently. It supports multiple algorithms for training vocabularies, including the byte-pair encoding algorithm covered earlier.
The Llama and Mistral series use SentencePiece, along with many other models. The library is available on GitHub at google/sentencepiece.
The major difference with SentencePiece lies in the order of operations. For tiktoken, the process is straightforward: take code points in a string, encode them using UTF-8 to bytes, then merge bytes.
SentencePiece works directly at the level of code points themselves. It examines the code points available in your training set, then merges those code points. The BPE algorithm runs on the code point level. When rare code points appear—rarity determined by the character coverage hyperparameter—they either map to a special unknown token (unk) or, if byte fallback is enabled, encode using UTF-8. The individual bytes of that encoding then translate into special byte tokens added to the vocabulary. This means BPE operates on code points with a fallback to bytes for rare characters. Personally, the tiktoken approach seems significantly cleaner, though this represents a subtle but major difference in how they handle tokenization.
tiktoken vs SentencePiece: The Key Difference
tiktoken (GPT approach):
- Text → UTF-8 bytes → BPE on bytes
- Always works on byte level (0-255)
SentencePiece (Llama approach):
- Text → Unicode code points → BPE on code points
- Falls back to bytes only for rare characters
graph TB
subgraph "tiktoken (GPT approach)"
A1[Text: '안녕하세요'] --> A2[Unicode Code Points<br/>U+C548 U+B155 U+D558 U+C138 U+C694]
A2 --> A3[UTF-8 Bytes<br/>EC 95 88 EB 85 95...]
A3 --> A4[BPE on Bytes<br/>256 base tokens]
A4 --> A5[Final Tokens<br/>Always works on bytes]
end
subgraph "SentencePiece (Llama approach)"
B1[Text: '안녕하세요'] --> B2[Unicode Code Points<br/>U+C548 U+B155 U+D558 U+C138 U+C694]
B2 --> B3{Code point<br/>in vocab?}
B3 -->|Yes| B4[BPE on Code Points<br/>Merge whole characters]
B3 -->|No - Rare| B5[Byte Fallback<br/>UTF-8 bytes → byte tokens]
B4 --> B6[Final Tokens<br/>More efficient for non-English]
B5 --> B6
end
style A3 fill:#e1f5ff
style A4 fill:#fff4e1
style B4 fill:#d4f1d4
style B5 fill:#ffe1e1
note1[Always byte-level<br/>Universal but less efficient]
note2[Character-level first<br/>Falls back to bytes for rare chars]
A4 -.-> note1
B4 -.-> note2
Why it matters:
- tiktoken: Handles all languages equally but may be less efficient for non-English
- SentencePiece: More efficient for languages with many unique characters (Chinese, Japanese)
A concrete example clarifies this distinction. Here’s how to import SentencePiece and create a toy dataset. SentencePiece prefers working with files, so this creates a toy.txt file with sample content.
# Compare tiktoken vs SentencePiece on Chinese text
chinese_text = "你好世界" # "Hello World" in Chinese
print(f"Text: {chinese_text}")
print(f"UTF-8 bytes: {chinese_text.encode('utf-8')}")
print(f"Unicode code points: {[ord(c) for c in chinese_text]}")
# tiktoken approach: work on bytes
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
tiktoken_tokens = enc.encode(chinese_text)
print(f"tiktoken tokens: {tiktoken_tokens} (count: {len(tiktoken_tokens)})")# SentencePiece approach: work on code points (if we had it installed)
# !pip install sentencepiece # Uncomment to install
# For comparison, let's see the difference in approach:
print("tiktoken approach:")
print("1. Characters → UTF-8 bytes → BPE merges bytes")
for char in chinese_text:
utf8_bytes = char.encode('utf-8')
print(f" '{char}' → {utf8_bytes} → separate tokens for each byte")
print("\nSentencePiece approach:")
print("2. Characters → Unicode code points → BPE merges code points")
for char in chinese_text:
code_point = ord(char)
print(f" '{char}' → U+{code_point:04X} → can merge whole characters")SentencePiece provides extensive configuration options. This stems from its longevity and effort to handle diverse use cases, though this comes with accumulated historical complexity. The library includes numerous configuration arguments—more than shown here.
The complete set of training options is documented on GitHub. The raw protobuf used to represent the trainer spec also contains useful documentation. Many options are irrelevant for byte-pair encoding. For example, --shrinking_factor applies only to different training algorithms, not BPE.
Key SentencePiece Options for BPE Training:
Essential BPE Parameters:
--model_type=bpe- Use byte-pair encoding (default is “unigram”)--vocab_size=8000- Final vocabulary size (e.g., 8000, 16000, 32000)--input=file.txt- Training text file--model_prefix=model_name- Output model prefix (creates .model and .vocab files)
Important for Different Languages:
--character_coverage=0.9995- For languages with rich character sets (Japanese/Chinese)--character_coverage=1.0- For languages with small character sets (English/European)
Special Tokens:
--bos_id=1- Beginning of sentence token ID--eos_id=2- End of sentence token ID
--unk_id=0- Unknown token ID--pad_id=-1- Padding token ID (-1 disables)
Advanced Options:
--byte_fallback=true- Use byte fallback for rare characters--split_digits=true- Split numbers into individual digits--user_defined_symbols=["<mask>"]- Add custom special tokens
Note: Many options (like --shrinking_factor) apply only to other algorithms (unigram) and are irrelevant for BPE training.
The following configuration attempts to match how Llama 2 trained their tokenizer. This was accomplished by examining the tokenizer.model file that Meta released, opening it using protobuf, inspecting all the options, and copying those that appeared relevant.
The configuration starts with input specification—raw text in a file—followed by output configuration with prefix tok400.model and .vocab. The BPE algorithm is specified with a vocabulary size of 400. Extensive configurations follow for preprocessing and normalization rules. Normalization was prevalent before LLMs in natural language processing tasks like machine translation and text classification. The goal was to normalize and simplify text: convert everything to lowercase, remove double whitespace, etc.
In language models, the preference is to avoid this preprocessing. As a deep learning practitioner, my preference is not to touch the data. Keep the raw data in as raw a form as possible. The configuration attempts to disable much of this normalization.
SentencePiece also operates with a concept of sentences. This dates back to earlier development when the assumption was that tokenizers trained on independent sentences. This introduces concepts like how many sentences to train on, maximum sentence length, and sentence shuffling. Sentences serve as individual training examples.
In the context of LLMs, this distinction feels spurious. Sentences exist in raw datasets, but many edge cases arise. Defining what exactly constitutes a sentence becomes difficult upon closer examination, with potentially different concepts across languages. Why introduce this concept at all? Treating a file as a giant stream of bytes seems preferable.
The configuration includes treatment for rare characters—more accurately, rare code points. It also includes rules for splitting digits, handling whitespace and numbers, and similar concerns. This resembles how tiktoken uses regular expressions to split categories. SentencePiece provides equivalent functionality where you can split up digits and apply similar rules.
Additional settings handle special tokens. The configuration hardcodes the unk token, beginning of sentence, end of sentence, and pad token. The unk token must exist, while others are optional. System settings complete the configuration. Training produces tok400.model and tok400.vocab files. The model file can then be loaded to inspect the vocabulary.
Training Configuration
Training a SentencePiece model with these configuration options begins with creating training data:
# Create toy training data
with open("toy.txt", "w", encoding="utf-8") as f:
f.write("SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabulary size is predetermined prior to the neural model training. SentencePiece implements subword units (e.g., byte-pair-encoding (BPE) [Sennrich et al.]) and unigram language model [Kudo.]) with the extension of direct training from raw sentences. SentencePiece allows us to make a purely end-to-end system that does not depend on language-specific pre/postprocessing.")# pip install sentencepiece# NOTE: after pip install sentencepiece can't be imported, requires a restarting the dialogue env
import sentencepiece as spmThe training configuration matches settings used for Llama 2:
# Train a SentencePiece BPE model
# These settings match those used for training Llama 2
options = dict(
# Input spec
input="toy.txt",
input_format="text",
# Output spec
model_prefix="tok400", # output filename prefix
# Algorithm spec - BPE algorithm
model_type="bpe",
vocab_size=400,
# Normalization (turn off to keep raw data)
normalization_rule_name="identity", # turn off normalization
remove_extra_whitespaces=False,
input_sentence_size=200000000, # max number of training sentences
max_sentence_length=4192, # max number of bytes per sentence
seed_sentencepiece_size=1000000,
shuffle_input_sentence=True,
# Rare word treatment
character_coverage=0.99995,
byte_fallback=True,
# Merge rules
split_digits=True,
split_by_unicode_script=True,
split_by_whitespace=True,
split_by_number=True,
max_sentencepiece_length=16,
add_dummy_prefix=True,
allow_whitespace_only_pieces=True,
# Special tokens
unk_id=0, # the UNK token MUST exist
bos_id=1, # the others are optional, set to -1 to turn off
eos_id=2,
pad_id=-1,
# Systems
num_threads=os.cpu_count(), # use ~all system resources
)
spm.SentencePieceTrainer.train(**options);Loading and inspecting the trained model:
# Load and inspect the trained model
sp = spm.SentencePieceProcessor()
sp.load('tok400.model')
# Show the vocabulary - first few entries
vocab = [[sp.id_to_piece(idx), idx] for idx in range(sp.get_piece_size())]
print("First 20 tokens:")
for token, idx in vocab[:20]:
print(f" {idx}: '{token}'")
print(f"\nTotal vocabulary size: {len(vocab)}")Training with vocabulary size 400 on this text produces individual pieces—the individual tokens that SentencePiece creates. The vocabulary begins with the unk token at ID zero, followed by beginning of sequence and end of sequence at IDs one and two. Since pad ID was set to negative one, no pad ID appears in the vocabulary.
The next 256 entries are individual byte tokens. Since byte fallback was enabled (set to true) in Llama, the vocabulary includes all 256 byte tokens with their corresponding IDs.
# Show the SentencePiece vocabulary structure
print("SentencePiece Vocabulary Structure:")
print("=" * 40)
# 1. Special tokens (first few)
print("1. Special tokens:")
for i in range(3):
print(f" {i}: '{sp.id_to_piece(i)}'")
print("\n2. Byte tokens (next 256):")
print(" 3-258: <0x00> through <0xFF>")
for i in [3, 4, 5, 257, 258]: # Show first few and last few
print(f" {i}: '{sp.id_to_piece(i)}'")# 3. Merge tokens (BPE learned merges)
print("\n3. Merge tokens (BPE merges):")
print(" 259-399: Learned BPE merges")
for i in range(259, min(269, sp.get_piece_size())): # Show first 10 merges
print(f" {i}: '{sp.id_to_piece(i)}'")
# 4. Individual code point tokens
print("\n4. Individual code point tokens:")
print(" These are raw Unicode characters from training data")
# Find where individual tokens start (after merges)
for i in range(350, min(400, sp.get_piece_size())):
piece = sp.id_to_piece(i)
if len(piece) == 1 and not piece.startswith('<'): # Single character, not a byte token
print(f" {i}: '{piece}'")
if i > 360: # Just show a few examples
breakFollowing the byte tokens come the merges—the parent nodes in the merge tree. The visualization shows only the parents and their IDs, not the children. After the merges come the individual tokens and their IDs. These represent the individual code point tokens encountered in the training set.
SentencePiece organizes its vocabularies with this ordering: special tokens, byte tokens, merge tokens, then individual code point tokens. The raw code point tokens include all code points that occurred in the training set. Extremely rare code points—as determined by character coverage—are excluded. For instance, a code point occurring only once in a million sentences would be ignored and not added to the vocabulary.
With a vocabulary in place, encoding into IDs and decoding individual tokens back into pieces becomes possible:
# Test the SentencePiece tokenizer
test_text = "hello 안녕하세요"
ids = sp.encode(test_text)
pieces = [sp.id_to_piece(idx) for idx in ids]
print(f"Text: '{test_text}'")
print(f"Token IDs: {ids}")
print(f"Token pieces: {pieces}")
print(f"Decoded: '{sp.decode(ids)}'")
# Notice how Korean characters become byte tokens due to byte_fallback=TrueTesting with “hello 안녕하세요” reveals several interesting behaviors. Looking at the token IDs returned, the Korean characters stand out. These characters were not part of the training set, meaning SentencePiece encounters code points it hasn’t seen during training. These code points lack associated tokens, making them unknown tokens.
However, because byte fallback is enabled, SentencePiece doesn’t use unknown tokens. Instead, it falls back to bytes. It encodes the Korean characters with UTF-8, then uses byte tokens to represent those bytes. The resulting tokens represent the UTF-8 encoding, shifted by three due to the special tokens occupying earlier IDs.
Byte Fallback in SentencePiece
What is byte fallback?
When SentencePiece encounters a rare character (Unicode code point) that’s not in the vocabulary, instead of mapping it to <unk>, it:
- Converts the character to its UTF-8 bytes
- Maps each byte to a special byte token (
<0x00>through<0xFF>)
Example:
- Korean character ‘안’ → UTF-8 bytes:
0xEC 0x95 0x88 - Becomes 3 tokens:
<0xEC>,<0x95>,<0x88>
Key benefits:
- No information loss - can perfectly reconstruct original text
- Universal coverage - handles any language/character
- Graceful degradation - rare characters just use more tokens
Vocabulary impact:
- All 256 byte tokens are automatically added to vocabulary
- Takes up 256 slots of your vocab_size
- Remaining slots used for learned BPE merges
vs tiktoken: SentencePiece tries character-level first, falls back to bytes. tiktoken always works at byte-level.
Before proceeding, examining what happens without byte fallback provides useful contrast. Disabling byte fallback and retraining:
# Train SentencePiece WITHOUT byte fallback
options_no_fallback = options.copy()
options_no_fallback['byte_fallback'] = False
options_no_fallback['model_prefix'] = "tok400_no_fallback"
spm.SentencePieceTrainer.train(**options_no_fallback);# Load the no-fallback model and compare vocabularies
sp_no_fallback = spm.SentencePieceProcessor()
sp_no_fallback.load('tok400_no_fallback.model')
print(f"With byte fallback: {sp.get_piece_size()} tokens")
print(f"Without byte fallback: {sp_no_fallback.get_piece_size()} tokens")
# Show that byte tokens are gone
print("\nFirst 10 tokens (no fallback):")
for i in range(10):
print(f" {i}: '{sp_no_fallback.id_to_piece(i)}'")The first change is that all byte tokens disappear. The vocabulary now contains only merges, with many more merges available since byte tokens no longer consume vocabulary space.
# Test encoding Korean text without byte fallback
test_text = "hello 안녕하세요"
# With byte fallback
ids_with_fallback = sp.encode(test_text)
print(f"With fallback: {ids_with_fallback}")
print(f"Decoded: '{[sp.id_to_piece(id) for id in ids_with_fallback]}'")
# Without byte fallback
ids_no_fallback = sp_no_fallback.encode(test_text)
print(f"\nWithout fallback: {ids_no_fallback}")
print(f"Decoded: '{[sp_no_fallback.id_to_piece(id) for id in ids_no_fallback]}'")
# Korean characters become UNK (token 0)Encoding the test string now produces zeros. The entire Korean string becomes unknown, mapping to unk. Since the unk token is token zero, the output consists of zeros. This feeds into your language model. The language model receives unk for all unrecognized rare content. This is not ideal behavior. Llama correctly uses byte fallback to ensure these unknown or rare code points feed into the model in some manner.
Another interesting detail appears when decoding individual tokens. Spaces render as bold underscores. The exact reason SentencePiece switches whitespace into bold underscore characters is unclear—possibly for visualization purposes.
Notice the extra space at the beginning of “hello”. This comes from the add_dummy_prefix option set to true.
The documentation explains:
// Add dummy whitespace at the beginning of text in order to
// treat "world" in "world" and "hello world" in the exact same way.
optional bool add_dummy_prefix = 26 [default = true];Purpose: Ensures consistent tokenization by treating words the same whether they appear at the beginning of text or in the middle. Without this, “world” alone vs “world” in “hello world” might tokenize differently due to the presence or absence of leading whitespace.
sp.encode('world'), sp.encode('a world')sp.id_to_piece(313)Returning to the tiktokenizer, “world” as a token by itself has a different ID than “space world”. Token 14957 represents “world” while token 1917 represents ” world”. These are two different tokens for the language model. The language model must learn from data that they represent a similar concept. In the tiktoken world, words at the beginning of sentences and words in the middle of sentences look completely different to the model. The model must learn that they are roughly the same.
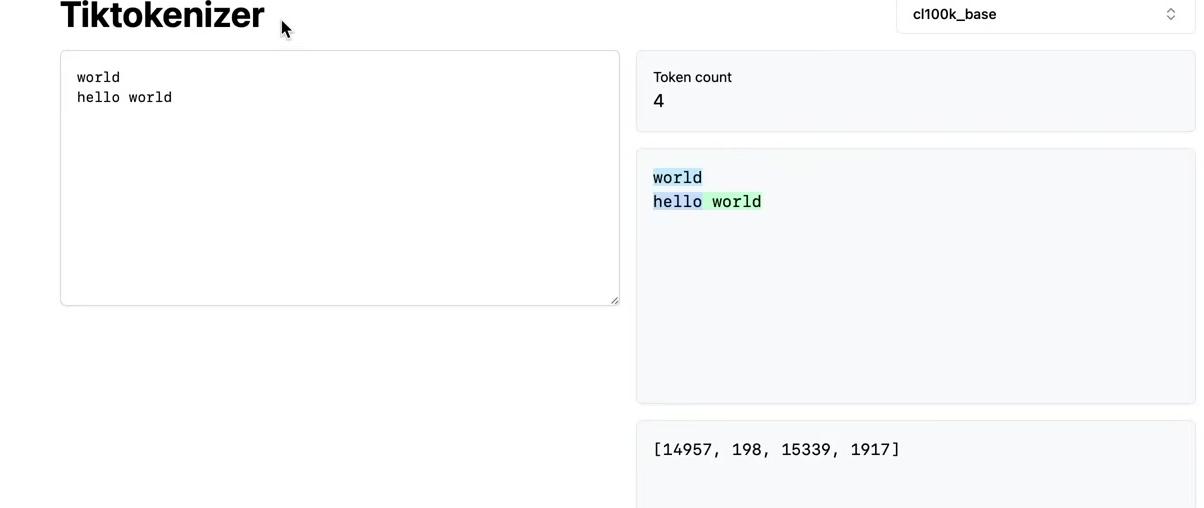
The add_dummy_prefix option addresses this issue. As part of preprocessing, it adds a space to strings. This makes both instances become “space world”. Llama 2 also uses this option.
The raw protocol buffer representation of the tokenizer that Llama 2 trained appears below. You can inspect these settings to make your tokenization identical to Meta’s Llama 2:
Llama 2 Tokenizer Configuration (from protobuf):
normalizer_spec {
name: "identity"
precompiled_charsmap: ""
add_dummy_prefix: true
remove_extra_whitespaces: false
normalization_rule_tsv: ""
}
trainer_spec {
input: "/large_experiments/theorem/datasets/MERGED/all.test1.merged"
model_prefix: "spm_model_32k_200M_charcov099995_allowWSO__v2"
model_type: BPE
vocab_size: 32000
self_test_sample_size: 0
input_format: "text"
character_coverage: 0.99995
input_sentence_size: 200000000
seed_sentencepiece_size: 1000000
shrinking_factor: 0.75
num_threads: 80
num_sub_iterations: 2
max_sentence_length: 4192
shuffle_input_sentence: true
max_sentencepiece_length: 16
split_by_unicode_script: true
split_by_whitespace: true
split_by_number: true
treat_whitespace_as_suffix: false
split_digits: true
allow_whitespace_only_pieces: true
vocabulary_output_piece_score: true
hard_vocab_limit: true
use_all_vocab: false
byte_fallback: true
required_chars: ""
unk_id: 0
bos_id: 1
eos_id: 2
pad_id: -1
unk_surface: " ⁇ "
unk_piece: "<unk>"
bos_piece: "<s>"
eos_piece: "</s>"
pad_piece: "<pad>"
train_extremely_large_corpus: false
enable_differential_privacy: false
differential_privacy_noise_level: 0.0
differential_privacy_clipping_threshold: 0
}This shows the exact configuration Meta used to train Llama 2’s tokenizer, including all preprocessing options, vocabulary settings, and special token definitions.
SentencePiece carries considerable historical baggage. Concepts like sentences with maximum lengths feel confusing and potentially problematic. The library is commonly used in the industry because it efficiently handles both training and inference. It has quirks—the unk token must exist, the byte fallback implementation lacks elegance. The documentation could be stronger. Understanding the library’s behavior required extensive experimentation, visualization, and exploration. Despite these issues, the repository provides a valuable tool for training your own tokenizer.
An Important Practical Constraint
One critical constraint to understand when training SentencePiece tokenizers: the vocab_size must be strictly greater than the number of unique characters (determined by character_coverage) plus the special tokens (unk, bos, eos, etc.). If you attempt to train with vocab_size=32000 but your training data contains 50,000 unique code points after applying character coverage, training will fail with the error: “Vocabulary size is smaller than required_chars.” This constraint becomes particularly important when working with diverse multilingual datasets that may contain tens of thousands of unique Unicode characters. The solution is either to increase vocab_size, decrease character_coverage to exclude more rare characters, or enable byte_fallback=True so that rare characters don’t need individual tokens. This is one reason why Llama 2 carefully balanced vocab_size=32000 with character_coverage=0.99995—ensuring enough vocabulary slots remain after accounting for all the base characters that needed representation.
Special Tokens and Extensions
Understanding Special Tokens
Beyond tokens derived from raw bytes and BPE merges, we can insert special tokens to delimit different parts of the data or introduce structure to the token streams. Looking at the encoder object from OpenAI’s GPT-2, we can see that the length is 50,257.
Where do these tokens come from? There are 256 raw byte tokens, and OpenAI performed 50,000 merges, which become the other tokens. This accounts for 50,256 tokens. The 257th token is a special token called “end of text”. This special token appears as the very last token and delimits documents in the training set.
# Find the token with the highest ID (should be the special token)
max_id = max(encoder.values())
special_token = [k for k, v in encoder.items() if v == max_id][0]
print(f"Special token: '{special_token}' with ID: {max_id}")When creating training data, we have documents that we tokenize to get a stream of tokens. Those tokens range from 0 to 50,256. Between documents, we insert the special end of text token.
This serves as a signal to the language model that the document has ended and what follows will be unrelated to the previous document. The language model must learn this from data. It needs to learn that this token usually means it should wipe its memory of what came before. What preceded this token is not informative to what comes next. We’re expecting the language model to learn this behavior, while providing this special delimiter between documents.
Testing this in Tiktokenizer with the GPT-2 tokenizer shows how this works. Typing “Hello world, how are you?” produces different tokens. When we add “end of text”, the individual words remain separate tokens until we complete the special token string. Once we finish typing <|endoftext|>, we suddenly get token 50,256.
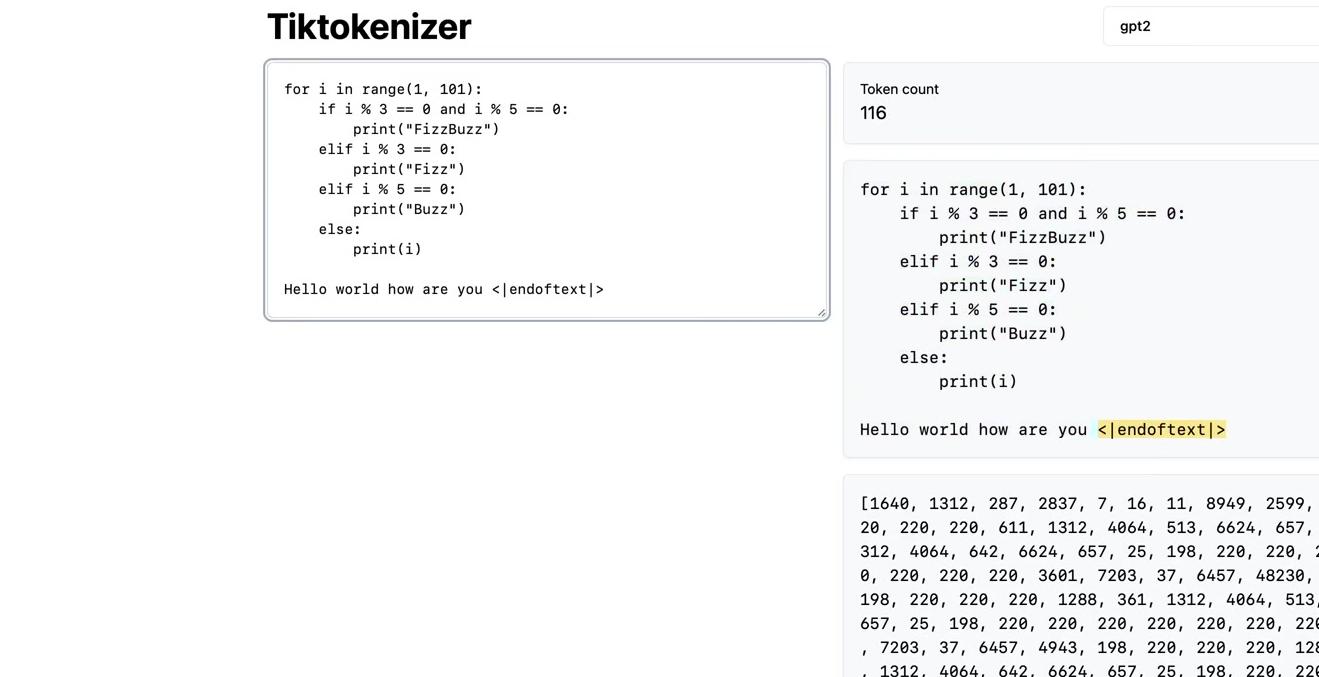
This works because the special token doesn’t go through the BPE merges. Instead, the code that outputs tokens has special case instructions for handling special tokens. We didn’t see these special instructions in encoder.py—they’re absent there.
graph TB
subgraph "Normal BPE Processing"
A[Text: 'Hello world'] --> B[Split by Regex Pattern]
B --> C[Apply BPE Merges]
C --> D[Token IDs: 15496, 995]
end
subgraph "Special Token Processing"
E["Text: 'Hello <endoftext> world'"] --> F[Scan for Special Tokens]
F --> G{Special token<br/>found?}
G -->|Yes| H["Direct Token Swap<br/><endoftext> → 50256"]
G -->|No| I[Normal BPE Processing]
H --> J[Final Tokens:<br/>15496, 50256, 995]
I --> J
end
subgraph "Special Token Registry"
K["Special Tokens Map<br/><endoftext>: 50256<br/><im_start>: 100264<br/><im_end>: 100265"]
K -.->|Lookup| H
end
style H fill:#FFD700
style I fill:#e1f5ff
style K fill:#ffe1f5
note1[Special tokens bypass<br/>normal BPE entirely]
note2[Registered outside<br/>the merge vocabulary]
H -.-> note1
K -.-> note2
The tiktoken library, implemented in Rust, contains extensive special case handling for these special tokens. You can register, create, and add them to the vocabulary. The library looks for these special tokens and swaps them in whenever it encounters them. These tokens exist outside the typical byte-pair encoding algorithm.
// From tiktoken/src/lib.rs - Special Token Handling
impl CoreBPE {
fn new_internal(
encoder: HashMap<Vec<u8>, Rank>,
special_tokens_encoder: HashMap<String, Rank>, // Special tokens mapping
pattern: &str,
) -> Result<Self, Box<dyn std::error::Error + Send + Sync>> {
let regex = Regex::new(pattern)?;
// This is the key part Andrej mentions - creating a special regex
// that matches all special tokens
let special_regex = {
let parts = special_tokens_encoder
.keys()
.map(|s| fancy_regex::escape(s)) // Escape special token strings
.collect::<Vec<_>>();
Regex::new(&parts.join("|"))? // Join with OR operator
};
let decoder: HashMap<Rank, Vec<u8>> =
encoder.iter().map(|(k, v)| (*v, k.clone())).collect();
let special_tokens_decoder: HashMap<Rank, Vec<u8>> =
special_tokens_encoder
.iter()
.map(|(k, v)| (*v, k.as_bytes().to_vec()))
.collect();
...
Ok(Self {
encoder,
special_tokens_encoder, // Store special tokens
decoder,
special_tokens_decoder, // Store special token decoder
regex_tls: (0..MAX_NUM_THREADS).map(|_| regex.clone()).collect(),
special_regex_tls: (0..MAX_NUM_THREADS)
.map(|_| special_regex.clone()) // Thread-local special regex
.collect(),
sorted_token_bytes,
})
}
pub fn encode_with_special_tokens(&self, text: &str) -> Vec<Rank> {
let allowed_special = self.special_tokens();
self.encode(text, &allowed_special).unwrap().0
}
}Key points from the implementation:
- Special regex creation: Creates a separate regex that matches all special tokens by escaping them and joining with
|(OR) - Separate handling: Special tokens bypass normal BPE processing entirely
- Thread-local storage: Uses thread-local regex instances for performance
- Direct token swapping: When special tokens are found, they’re directly mapped to their token IDs
Special tokens are used pervasively, not just in base language modeling for predicting the next token in a sequence, but especially during the fine-tuning stage and in ChatGPT-style applications. We don’t just need to delimit documents—we need to delimit entire conversations between an assistant and a user. Refreshing the Tiktokenizer page shows the default example using fine-tuned model tokenizers rather than base model encoders.
For example, the GPT-3.5 Turbo scheme uses several special tokens. “IM start” and “IM end” appear throughout (short for “imaginary monologue start”). Each message has a start and end token, and many other tokens can be used to delimit conversations and track the flow of messages.
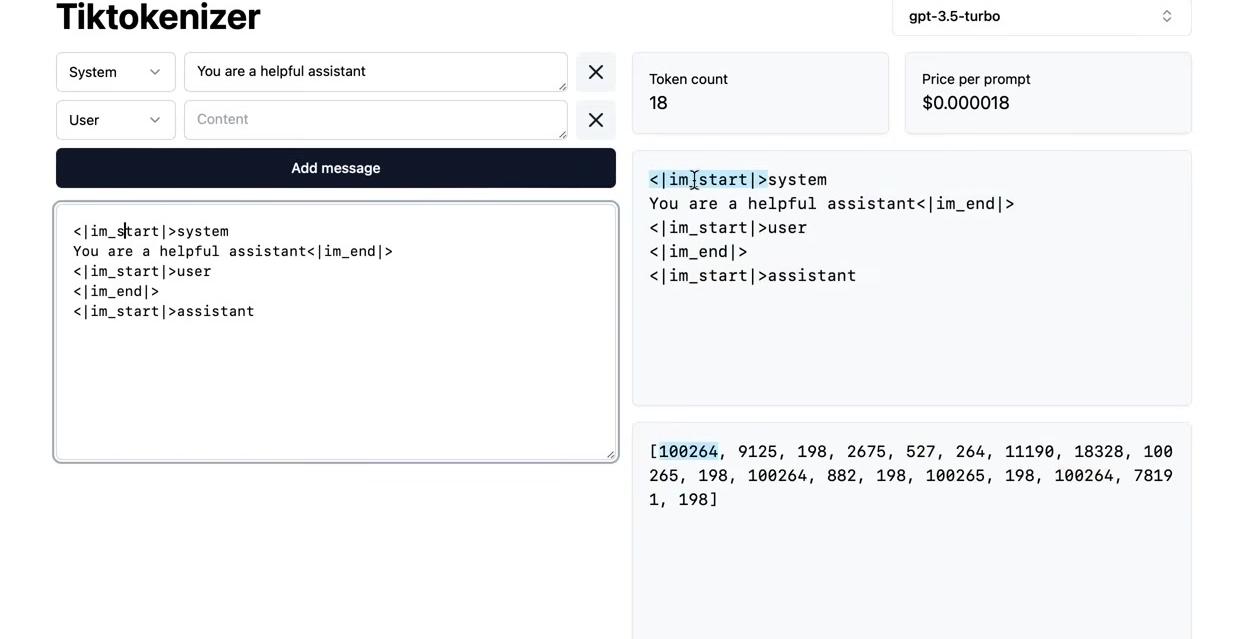
<|im_start|>system and <|im_end|> used to structure a conversation.The tiktoken library documentation explains how to extend tiktoken and create custom tokenizers. You can fork the CL100K base tokenizer from GPT-4 and extend it by adding more special tokens. These are completely customizable—you can create any arbitrary tokens and add them with new IDs. The tiktoken library will correctly swap them out when it encounters them in strings.
# Extending tiktoken with custom special tokens
import tiktoken
cl100k_base = tiktoken.get_encoding("cl100k_base")
# In production, load the arguments directly instead of accessing private attributes
# See openai_public.py for examples of arguments for specific encodings
enc = tiktoken.Encoding(
# If you're changing the set of special tokens, make sure to use a different name
# It should be clear from the name what behaviour to expect.
name="cl100k_im",
pat_str=cl100k_base._pat_str,
mergeable_ranks=cl100k_base._mergeable_ranks,
special_tokens={
**cl100k_base._special_tokens,
"<|im_start|>": 100264,
"<|im_end|>": 100265,
}
)cl100k_base._special_tokensenc.encode('<|im_start|>Hello world<|im_end|>', allowed_special={'<|im_start|>', '<|im_end|>'})enc._special_tokensReturning to the openai_public.py file we examined previously, we can see how GPT-2 in tiktoken registers special tokens. The vocabulary and pattern for splitting are defined, along with the single special token in GPT-2: the end of text token with its corresponding ID.
In GPT-4’s definition, the pattern has changed as discussed, but the special tokens have also changed in this tokenizer. The end of text token remains, just as in GPT-2, but four additional tokens appear: FIM prefix, middle, suffix, and end of prompt. FIM stands for “fill in the middle”. This concept comes from the paper Efficient Training of Language Models to Fill in the Middle.
# GPT-2 Special Tokens (from openai_public.py)
def gpt2():
# ... other tokenizer configuration ...
return {
"name": "gpt2",
"explicit_n_vocab": 50257,
"pat_str": r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}++| ?\p{N}++| ?[^\s\p{L}\p{N}]++|\s++$|\s+(?!\S)|\s""",
"mergeable_ranks": mergeable_ranks,
"special_tokens": {"<|endoftext|>": 50256}, # Only one special token
}
# GPT-4 Special Tokens (cl100k_base from openai_public.py)
def cl100k_base():
# ... other tokenizer configuration ...
special_tokens = {
"<|endoftext|>": 100257, # Same as GPT-2 but different ID
"<|fim_prefix|>": 100258, # Fill-in-the-middle: prefix
"<|fim_middle|>": 100259, # Fill-in-the-middle: middle
"<|fim_suffix|>": 100260, # Fill-in-the-middle: suffix
"<|endofprompt|>": 100276 # End of prompt marker
}
return {
"name": "cl100k_base",
"explicit_n_vocab": 100277,
"pat_str": r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{2,}|[^\r\n\p{L}\p{N}]?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+""",
"mergeable_ranks": mergeable_ranks,
"special_tokens": special_tokens,
}Key differences:
- GPT-2: Only has
<|endoftext|>(ID: 50256) - GPT-4: Has 5 special tokens including FIM (Fill-in-the-Middle) tokens for code completion tasks
- Vocabulary growth: From 50,257 tokens (GPT-2) to 100,277 tokens (GPT-4)
Training a language model and then adding special tokens is a common practice. When adding special tokens, you must perform model surgery on the transformer and its parameters. Adding an integer token means extending the embedding matrix for vocabulary tokens by adding a row. This row is typically initialized with small random numbers to create a vector representation for that token.
The final layer of the transformer must also be adjusted. The projection at the end into the classifier needs to be extended to accommodate the new token. This model surgery must accompany tokenization changes when adding special tokens. This is a common operation, especially when fine-tuning models—for example, converting a base model into a chat model like ChatGPT.
Vocabulary Size Considerations
Revisiting the question of how to set the vocabulary size reveals several important considerations. To understand these trade-offs, we can examine the model architecture developed in the previous video when building GPT from scratch.
The file defined the transformer model, with vocab_size appearing in specific places. Initially, the vocab size was set to 65 based on the character-level tokenization used for the Shakespeare dataset—an extremely small number compared to modern LLMs. In production systems, this grows much larger.
The vocabulary size doesn’t appear in most transformer layers. It only matters in two specific places within the language model definition.
# From gpt.py - Vocabulary size definition
vocab_size = len(chars) # Based on unique characters in textFile: gpt.py - Character-level vocabulary size
This shows how vocab_size is initially set based on the number of unique characters in the training text (e.g., 65 for Shakespeare dataset).
# From gpt.py - Token embedding table
class GPTLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# Token embedding table - vocab_size rows, n_embed columns
self.token_embedding_table = nn.Embedding(vocab_size, n_embed)
self.position_embedding_table = nn.Embedding(block_size, n_embed)
# ... other layers ...
# Final linear layer - projects to vocab_size logits
self.lm_head = nn.Linear(n_embed, vocab_size)File: gpt.py - Model architecture
This shows the two places where vocab_size matters:
- Token embedding: Maps token IDs to vectors (vocab_size → n_embed)
- Language model head: Maps final hidden states to logits (n_embed → vocab_size)
The first location is the token embedding table—a two-dimensional array where vocab_size determines the number of rows. Each vocabulary element (each token) has a vector that we train using backpropagation. This vector has size n_embed, which represents the number of channels in the transformer. As vocab_size increases, this embedding table grows by adding rows.
The second location appears at the end of the transformer in the lm_head layer, a linear layer that produces the logits. These logits become the probabilities for the next token in the sequence.
# From gpt.py - Forward pass using lm_head
def forward(self, idx, targets=None):
B, T = idx.shape
# Token and position embeddings
tok_emb = self.token_embedding_table(idx) # (B,T,C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
x = tok_emb + pos_emb # (B,T,C)
# Transformer blocks
x = self.blocks(x) # (B,T,C)
x = self.ln_f(x) # (B,T,C)
# Final projection to vocabulary
logits = self.lm_head(x) # (B,T,vocab_size)
# ... loss calculation ...File: gpt.py - Forward pass
The lm_head layer produces logits for each token position, with one probability for every token in the vocabulary. As vocab_size grows, this final computation becomes more expensive.
Intuitively, we need to produce a probability for every single token that might come next at every point in the transformer. With more tokens, we need to produce more probabilities. Every additional token introduces another dot product in this linear layer for the final transformer layer.
Why can’t vocabulary size grow indefinitely?
Several constraints limit vocabulary size:
Computational cost: The token embedding table grows, and the linear layer grows. The lm_head layer becomes significantly more computationally expensive as it must compute probabilities for each token.
Parameter under-training: With more parameters comes the risk of under-training. If the vocabulary contains a million tokens, each token appears increasingly rarely in the training data since many other tokens compete for representation. Fewer examples for each individual token mean the vectors associated with each token may be under-trained, as they don’t participate in the forward-backward pass as frequently.
Sequence compression trade-offs: As vocab_size grows, sequences shrink considerably. This allows the model to attend to more text, which is beneficial. However, too large of chunks being compressed into single tokens can be problematic. The model may have insufficient “time to think” per unit of text. Too much information gets compressed into a single token, and the forward pass of the transformer may not have adequate capacity to process that information appropriately.
These considerations guide the design of vocabulary size. This is primarily an empirical hyperparameter. In state-of-the-art architectures today, vocabulary sizes typically range in the high tens of thousands to around 100,000 tokens.
Extending Vocabulary Size
Another important consideration is extending the vocabulary size of a pre-trained model. This operation is performed fairly commonly in practice. During fine-tuning for ChatGPT, many new special tokens get introduced on top of the base model to maintain the metadata and structure of conversation objects between the user and the assistant. This requires numerous special tokens. Additional special tokens might also be added for tool use, such as browser access or other functionality.
Adding tokens to an existing model is straightforward. The process requires resizing the embedding table by adding rows. These new parameters are initialized from scratch using small random numbers. The weights inside the final linear layer must also be extended to calculate probabilities for the new tokens through additional dot products with the associated parameters.
Both operations constitute a resizing procedure—a mild form of model surgery that can be performed fairly easily. A common approach freezes the base model parameters while training only the newly introduced parameters. This allows new tokens to be incorporated into the architecture without disrupting the pre-trained knowledge. The choice of which parameters to freeze or train remains flexible depending on the specific use case.
Advanced Topics
Multi-modal Tokenization
The design space for introducing new tokens into a vocabulary extends far beyond special tokens and new functionality. Recent work has focused on constructing transformers that can simultaneously process multiple input modalities—not just text, but images, videos, and audio. The key question becomes: how do you feed in all these modalities and potentially predict them from a transformer? Do you need to change the architecture fundamentally?
Many researchers are converging toward a solution that preserves the transformer architecture. The approach tokenizes the input domains, then treats these tokens identically to text tokens. No fundamental architectural changes are required.
An early paper demonstrated this approach with images. The visualization shows how an image can be converted into integers that become image tokens. These tokens can be “hard” tokens (forced to be discrete integers) or “soft” tokens (allowed to be continuous while passing through a bottleneck, similar to autoencoders).
The OpenAI Sora technical report demonstrates this concept at scale with video generation. The report states: “Whereas LLMs have text tokens, Sora has visual patches.” The system converts videos into tokens with their own vocabularies. These discrete tokens can be processed with autoregressive models, or soft tokens can be handled with diffusion models. This remains an active area of research beyond the scope of this tutorial.
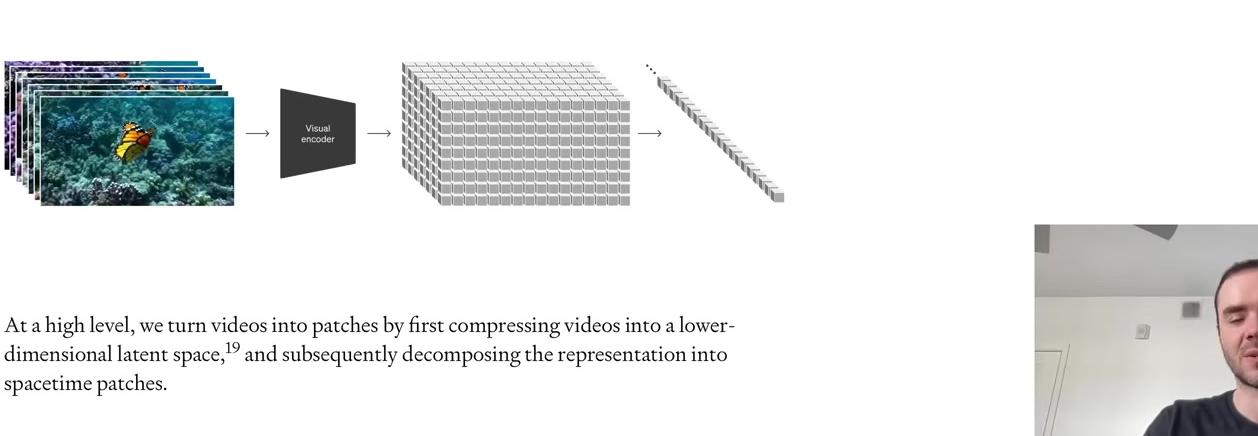
Gist Tokens and Prompt Compression
Learning to compress prompts with gist tokens addresses a practical challenge with language models that require very long prompts. Long prompts slow down inference because they must be encoded, processed, and attended to at each step.
The paper introduces new tokens as a compression technique. A few special “gist tokens” are placed in a sequence, then the model is trained by distillation. The entire model remains frozen—only the representations of the new tokens (their embeddings) are trained. The optimization adjusts these new token embeddings such that the language model’s behavior matches the behavior when using the full, long prompt.

This compression technique allows the original prompt to be discarded at test time, replaced by the gist tokens with nearly identical performance. This represents one example of parameter-efficient fine-tuning techniques where most of the model remains fixed. There’s no training of model weights, no LoRA, or other new parameters—only the token embeddings are trained.
Supporting Quotes from the Gist Tokens Paper:
The approach trains gist tokens for categories of prompts rather than individual prompts, using several key techniques:
Meta-learning approach for generalization:
“But where prefix-tuning requires learning prefixes via gradient descent for each task, gisting adopts a meta-learning approach, where we simply predict the gist prefixes zero-shot given only the prompt, allowing for generalization to unseen instructions without any additional training.”
Training across a distribution of tasks:
“However, we differ from this prior work in that we are not interested in distilling just a single task, but in amortizing the cost of distillation across a distribution of tasks T. That is, given a task t ∼ T, instead of obtaining the distilled model via gradient descent, we use G to simply predict the gist tokens (≈ parameters) of the distilled model”
Single model handles multiple task types:
“A dataset with a large variety of tasks (prompts) is crucial to learn gist models that can generalize. To obtain the largest possible set of tasks for instruction finetuning, we create a dataset called Alpaca+, which combines… 104,664 unique tasks t”
Reusable across similar prompts:
“Since gist tokens are much shorter than the full prompt, gisting allows arbitrary prompts to be compressed, cached, and reused for compute efficiency.”
The paper trains one model that learns to compress any prompt into gist tokens, rather than training separate tokens for each individual prompt. The gist tokens are predicted dynamically based on the input prompt content. This design space offers many potential directions for future exploration.
Common Tokenization Issues and Pitfalls
Why LLMs Struggle with Certain Tasks
Having explored the tokenization algorithm in depth, we can now revisit the issues mentioned at the beginning and understand their root causes.
Why can’t LLMs spell words well or perform spell-related tasks?
Characters are chunked into tokens, and some tokens can be quite long. Looking at the GPT-4 vocabulary reveals examples like .DefaultCellStyle, which represents a single token despite containing many characters.
Too much information gets compressed into this single token. Testing reveals that the model struggles with spelling tasks for this token. When asked “How many letters ‘l’ are there in the word .DefaultCellStyle?”, the prompt is intentionally structured so .DefaultCellStyle becomes a single token—this is what the model sees. The model incorrectly responds with three when the correct answer is four.

Another character-level task demonstrates the same limitation. When asked to reverse the string .DefaultCellStyle, GPT-4 attempted to use a code interpreter. When prevented from using tools, it produced an incorrect jumbled result. The model cannot correctly reverse this string from right to left.
Testing a different approach yields interesting results. Using a two-step process—first printing every character separated by spaces, then reversing that list—the model succeeds. When prevented from using tools, it correctly produces all the characters, then successfully reverses them. The model cannot reverse the string directly, but once the characters are explicitly listed out, the task becomes manageable. Breaking up the single token into individual character tokens makes them visible to the model, enabling successful reversal.
Why are LLMs worse at non-English languages?
Language models not only see less non-English data during training of the model parameters, but the tokenizer itself receives insufficient training on non-English data. The English phrase “Hello how are you?” tokenizes into five tokens, while its Korean translation requires 15 tokens—a three-fold increase. The Korean greeting “annyeonghaseyo” (안녕하세요), equivalent to “hello,” requires three tokens, whereas “hello” in English is a single token. This makes non-English text more bloated and diffuse, contributing to reduced model performance on other languages.
Why is LLM performance poor at simple arithmetic?
This relates to how numbers are tokenized. Addition algorithms operate at the character level—we add ones, then tens, then hundreds, referring to specific digit positions.

However, numbers are represented arbitrarily based on which digits happened to merge during tokenization training. The blog post “Integer tokenization is insane” systematically explores number tokenization in GPT-2. Four-digit numbers may appear as a single token or split into various combinations: 1-3, 2-2, or 3-1. Different numbers receive different tokenization patterns in an arbitrary manner. The model sometimes sees a token for all four digits, sometimes three, sometimes two, sometimes one—without consistency. This creates a significant challenge for the language model. While the model manages to handle this inconsistency, the situation remains far from ideal. When Meta trained Llama 2 using SentencePiece, they ensured all digits were split to improve arithmetic performance.
Why is GPT-2 not as good at Python?
This stems partly from modeling issues related to architecture, dataset, and model strength, but tokenization plays a significant role. The earlier Python example demonstrated how the GPT-2 tokenizer handles spaces inefficiently. Every single space becomes an individual token, dramatically reducing the context length the model can attend across. This represents a tokenization limitation in GPT-2 that was later addressed in GPT-4.
The Infamous Edge Cases
My LLM abruptly halts when it sees the string <|endoftext|>
A strange behavior emerges when attempting to get GPT-4 to print the string <|endoftext|>. When asked to “Print the string <|endoftext|>”, the model responds with “Could you please specify the string?” Repeating the request yields similar confusion—the model acts as if it cannot see <|endoftext|> and fails to print it.

Something is breaking with respect to special token handling. The internal implementation details remain unclear—OpenAI might be parsing this as an actual special token rather than treating <|endoftext|> as individual pieces without the special token handling logic. When calling .encode, someone might be passing in the allowed_special parameter and allowing <|endoftext|> as a special character in the user prompt. The user prompt represents attacker-controlled text, which should ideally not be parsed using special tokens. Something is clearly going wrong here. Knowledge of these special tokens becomes a potential attack surface. Attempting to confuse LLMs with special tokens can break the system in unexpected ways.
The trailing whitespace issue
In the OpenAI Playground using gpt-3.5-turbo-instruct (a completion model closer to a base model that continues token sequences), entering “Here’s a tagline for an ice cream shop” and pressing submit produces a completion. However, adding a trailing space before clicking submit triggers a warning: “Your text ends in a trailing space, which causes worse performance due to how the API splits text into tokens.”
What’s causing this warning? Consider how this appears in training data. The phrase “Here’s a tagline for an ice cream shop:” might be followed by a completion like ” Oh yeah” in a training document.
The space character serves as a prefix to tokens in GPT. The continuation isn’t an “O” token—it’s a ” O” token. The space is part of the token, and together they form token 8840.
Without the trailing space, the model can sample the ” O” token during completion. With the trailing space added, encoding the string produces “Here’s a tagline for an ice cream shop:” with the trailing space becoming token 220.
Token 220 has been added, but this space would normally be part of the tagline since ” O” is a single token. This puts the model out of distribution. The space should be part of the next token, but we’ve placed it here separately. The model has seen very little data with an isolated space token in this position. We’re asking it to complete the sequence, but we’ve begun the first token and then split it up. This creates an out-of-distribution scenario that produces unpredictable behavior. The model rarely encounters examples like this, hence the warning.
The fundamental issue is that the LLM operates on tokens—text chunks rather than individual characters. These tokens are the atoms of what the LLM sees, and this produces unexpected behaviors. Consider .DefaultCellStyle again. The model has likely never seen “DefaultCellSty” without “le” in its training set.
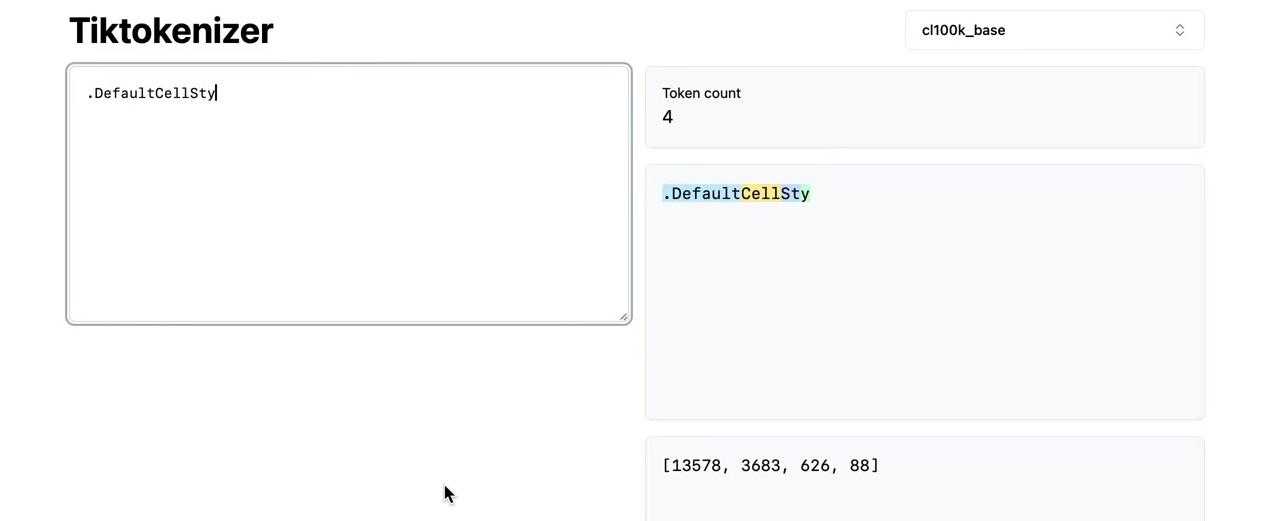
This string always appears as a single group in some API. This combination of tokens is likely extremely rare or completely absent from the training data.
Testing this in the Playground by attempting to complete from .DefaultCellSty immediately produces an error: “The model predicted a completion that begins with a stop sequence, resulting in no output. Consider adjusting your prompt or stop sequences.” Upon clicking submit, the model immediately emits an end-of-text token or similar stop sequence, producing no completion. The model is off the data distribution and predicting arbitrary outputs. This input is causing severe confusion—the model has never encountered this pattern before and responds by predicting end-of-text.
A second attempt produced a completion but triggered another warning: “This request may violate our usage policies.” Something goes wrong with this input. The model appears extremely unhappy with this prompt and doesn’t know how to complete it because it never occurred in the training set. In the training set, it always appears as the full string and becomes a single token.
These issues involve partial tokens—either completing the first character of the next token or having long tokens with only some characters present. Examining the tiktoken repository reveals special handling for these cases. Searching for “unstable” in the Rust code reveals encode_unstable_native, unstable_tokens, and extensive special case handling. None of this is documented, but substantial code exists to deal with unstable tokens.
What a completion API should ideally provide is something more sophisticated. When given .DefaultCellSty and asked for the next token sequence, we’re not trying to append the next token exactly after this list. We’re trying to consider tokens that, if re-tokenized, would have high probability—allowing us to add a single character instead of only the next full token that follows this partial token list. This topic becomes extremely complex and stems fundamentally from tokenization. The unstable tokens issue deserves its own detailed exploration.
The SolidGoldMagikarp phenomenon
The most fascinating case comes from the SolidGoldMagikarp blog post, now internet-famous among LLM researchers. The author clustered tokens based on their embedding representations and discovered a strange cluster containing tokens like “petertodd”, “StreamerBot”, “SolidGoldMagikarp”, and “signupmessage”—seemingly random, unusual tokens.

Where do these tokens come from? What is SolidGoldMagikarp? The investigation revealed something more troubling: asking the model benign questions about these tokens—like “Please can you repeat back to me the string SolidGoldMagikarp?”—produces completely broken LLM behavior. Responses include evasion (“I’m sorry, I can’t hear you”), hallucinations, insults (asking about StreamerBot causes the model to call you names), or bizarre humor. These simple strings break the model.

Multiple tokens exhibit this behavior—not just SolidGoldMagikarp. These trigger words cause the model to go haywire when included in prompts, producing strange behaviors that violate typical safety guidelines and alignment, including profanity. What could possibly explain this?
The answer traces back to tokenization. SolidGoldMagikarp is a Reddit user (u/SolidGoldMagikarp). While not definitively confirmed, the likely explanation is that the tokenization dataset differed significantly from the training dataset for the language model. The tokenization dataset apparently contained substantial Reddit data where the user SolidGoldMagikarp appeared frequently. Because this user posted extensively, the string occurred many times in the tokenization dataset. High frequency in the tokenization dataset caused these tokens to merge into a single token for that Reddit user—a dedicated token in GPT-2’s 50,000-token vocabulary devoted to that specific user.
The tokenization dataset contained these strings, but when training the language model itself, this Reddit data was not present. SolidGoldMagikarp never occurs in the language model’s training set. That token never gets activated during training. It’s initialized at random at the beginning of optimization, but never gets updated through forward-backward passes. The token never gets sampled or used, leaving it completely untrained. It remains like unallocated memory in a typical C program.
At test time, evoking this token plucks out a row of the embedding table that is completely untrained. This feeds into the transformer and creates undefined behavior. The model is out of sample, out of distribution, producing the bizarre behaviors documented in the blog post. Any of these weird tokens would evoke similar behavior because the model has never encountered them during training.
Token Efficiency
Different formats, representations, and languages can be more or less efficient with GPT tokenizers and other LLM tokenizers. JSON is dense in tokens, while YAML is significantly more efficient.
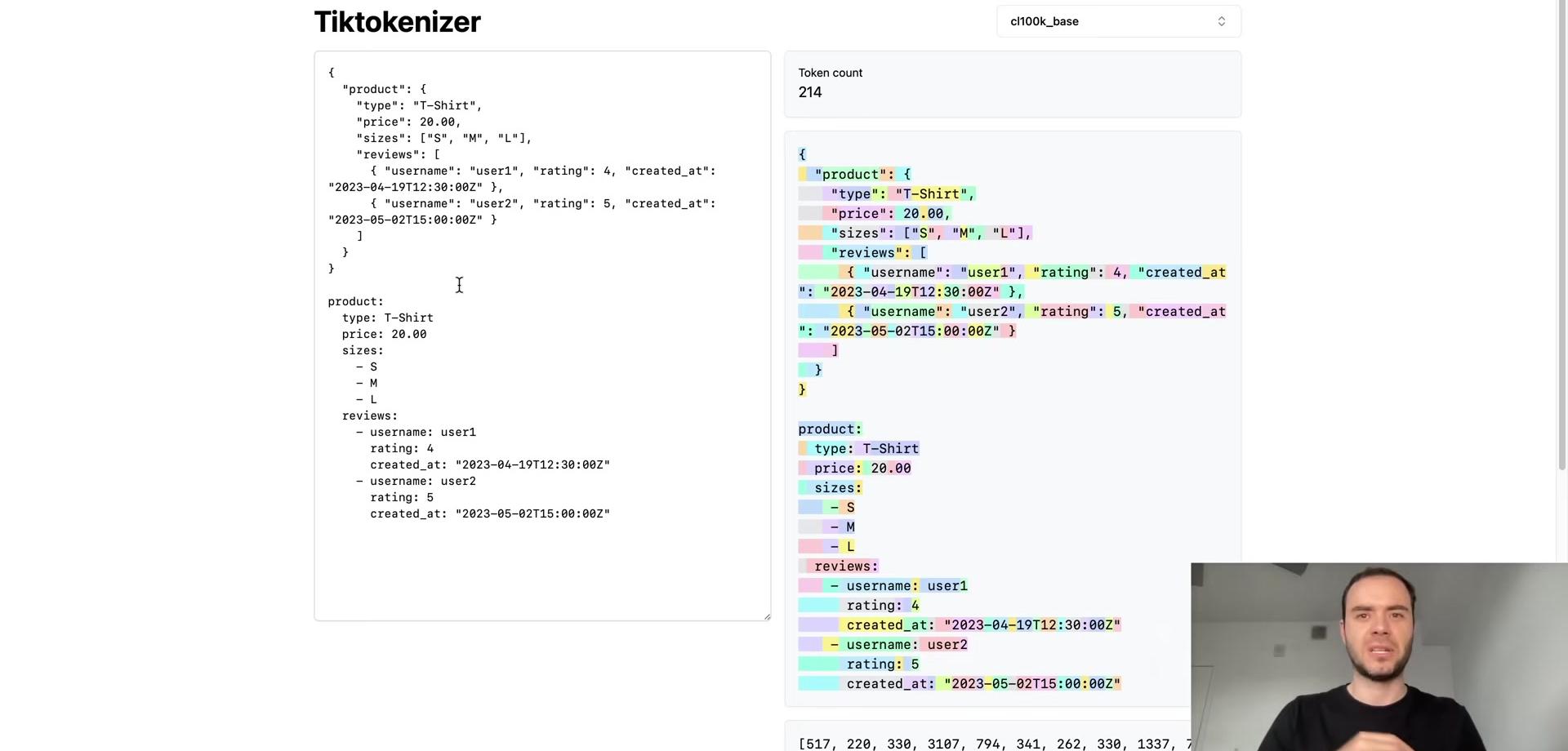
Comparing identical data in JSON and YAML reveals substantial differences. The JSON representation uses 116 tokens, while the YAML representation uses only 99 tokens—a meaningful improvement.
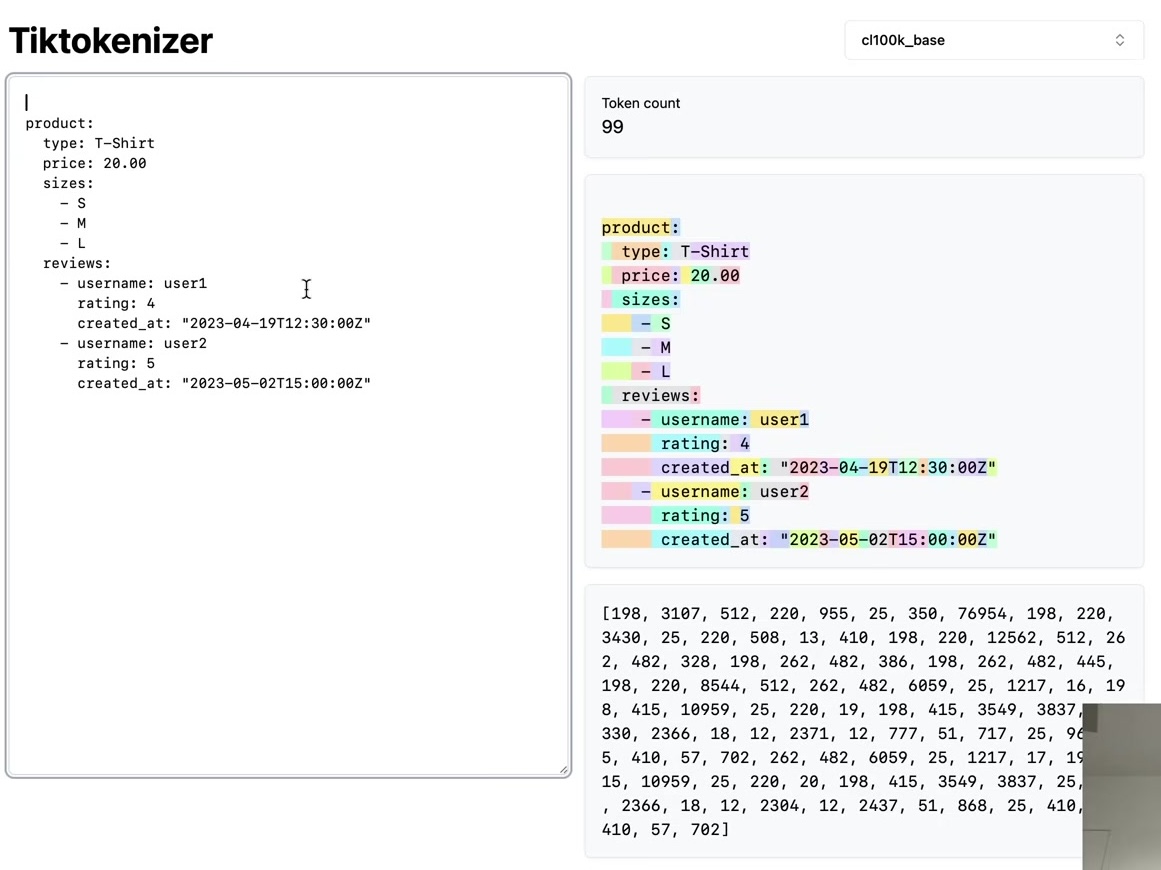
In the token economy, you pay per token in multiple ways: context length limits, computational costs, and direct dollar amounts for processing structured data. When working with structured data, prefer YAML over JSON. Tokenization density matters. Finding efficient encoding schemes requires measuring token efficiency across different formats and settings using tools like Tiktokenizer.
Conclusion and Final Recommendations
This concludes our exploration of tokenization. While the topic can feel dry and frustrating—this preprocessing stage lacks the elegance of the neural architectures it serves—dismissing tokenization would be a mistake. The sharp edges, footguns, security issues, and AI safety concerns (such as unallocated memory being fed into language models) make understanding this stage essential. Eternal glory awaits anyone who can eliminate tokenization entirely. One paper attempted this approach, and hopefully more will follow.
This tutorial has covered the fundamentals of the byte-pair encoding algorithm and its modern complexities:
- How tokenization evolved from simple character-level encoding to sophisticated BPE algorithms
- The crucial role of UTF-8 encoding and why we work with bytes
- How GPT-2 and GPT-4 use regex patterns to enforce merge boundaries
- The differences between tiktoken and SentencePiece approaches
- Special tokens and their role in structuring LLM inputs
- Why tokenization causes many unexpected LLM behaviors
Key Takeaways
- Tokenization is foundational - It bridges human text and neural networks. Every tokenization quirk cascades into model behavior.
- Different tokenizers for different purposes - GPT models optimize for English and code, while models like Llama aim for multilingual coverage. Choose wisely based on your use case.
- Token efficiency matters - In production systems, you pay per token. Understanding tokenization helps optimize prompts and choose better data formats (YAML over JSON).
- Edge cases are everywhere - From trailing spaces to partial tokens to unallocated embeddings, tokenization presents numerous sharp edges that can break applications.
- The dream of tokenization-free models - While current systems require tokenization, tokenization-free language models that work directly on bytes remain an active research area.
Remember: when your LLM exhibits bizarre behavior, tokenization is often the culprit.
Solveit
If you liked this and are interested in learning how to create stuff like this, you might be interested in the Solveit course and platform we used to create it: solve.it.com.